本文主要是介绍最小生成树和普利姆算法及克鲁斯卡尔算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、最小生成树的介绍
最小生成树(Minimum Cost Spanning Tree), 简称 MST。即给定一个带权的无向连通图,如何选取一棵生成树,使树上所有边上权的总和为最小,这叫最小生成树

- 给定一个带权的无向连通图,如何选取一棵生成树,使树上所有边上权的总和为最小,这叫最小生成树
- N个顶点,一定有N-1条边
- 包含全部顶点
- 求最小生成树的算法主要是普里姆算法和克鲁斯卡尔算法
二、普利姆算法
普利姆(Prim)算法求最小生成树,也就是在包含n个顶点的连通图中,找出只有(n-1)条边包含所有n个顶点的连通子图,也就是所谓的极小连通子图
2.1 普利姆算法的基本思路
- 设G=(V,E)是连通网,T=(U,D)是最小生成树,V,U是顶点集合,E,D是边的集合
- 若从顶点u开始构造最小生成树,则从集合V中取出顶点u放入集合U中,标记顶点v的visited[u]=1
- 若集合U中顶点ui与集合V-U中的顶点vj之间存在边,则寻找这些边中权值最小的边,但不能构成回路,将顶点vj加入集合U中,将边(ui,vj)加入集合D中,标记visited[vj]=1
- 重复步骤②,直到U与V相等,即所有顶点都被标记为访问过,此时D中有n-1条边
2.2 应用场景
有胜利乡有7个村庄(A, B, C, D, E, F, G),现在需要修路把7个村庄连通 各个村庄的距离用边线表示(权),比如 A – B 距离 5公里。问:如何修路保证各个村庄都能连通,并且总的修建公路总里程最短?

基本步骤:
-
首先,约定 V 为所有顶点的集合;约定 TE 为最小生成树中边的集合,初始为空;约定 U 为最小生成树中边的顶点集合,初始为空。
-
选择从 A 点开始普里姆算法,则 U = { A }。

-
找出所有与集合 U 中的顶点相连的权重最小的边作为最小生成树的边。此时集合 U 中只有一个 A顶点,在集合 V-U 中与 A 顶点相连的边有 <A,B>[5]、<A,C>[7]、<A,G>[2]。其中权重最小的边为 <A,G>[2],因此我们选择其为最小生成树的一条边,然后将此边加入 TE 集合,将 G 顶点加入 U 集合。此时 TE = { <A,G> },U = { A,G }。

-
继续找出所有与集合 U 中顶点相连的权重最小的边作为生成树的边。此时集合 U = { A、G },在顶点集合 V-U 中分别与顶点 A、C 相连的边有 <A、B>[5]、<A、C>[7]、<G、B>[3]、<G、E>[4]、<G、F>[6]。其中权重最小的边为 <G、B>[3],因此我们选取其为最小生成树的边,加入 TE 集合,将顶点 B 加入 U 集合。此时 TE = { <A,G> ,<G,B> },U = { A,G,B }。

-
继续找出所有与集合 U 中顶点相连的权重最小的边作为生成树的边。此时集合 U = { A、G、B },在顶点集合 V-U 中分别与顶点 A、C 相连的边有 <A、C>[7]、<G、E>[4]、<G、F>[6]、<B、D>[9]。其中权重最小的边为 <G、E>[4],因此我们选取其为最小生成树的边,加入 TE 集合,将顶点 B 加入 U 集合。此时 TE = { <A,G> ,<G,B> ,<G、E>},U = { A,G,B,E}。

-
继续找出所有与集合 U 中顶点相连的权重最小的边作为生成树的边。此时集合 U = { A、G、B、E },在顶点集合 V-U 中分别与顶点 A、C 相连的边有 <A、C>[7]、<E、C>[8]、<E、F>[5]、<G、F>[6]、<B、D>[9]。其中权重最小的边为 <E、F>[5],因此我们选取其为最小生成树的边,加入 TE 集合,将顶点 B 加入 U 集合。此时 TE = { <A,G> ,<G,B> ,<G、E>,<E、F>},U = { A,G,B,E,F}。

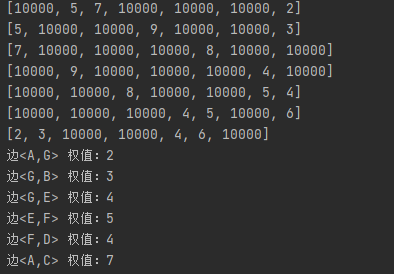
7.以此类推,最后得到的结果集为TE = { <A,G> ,<G,B> ,<G、E>,<E、F>,<F、D>,<A、C>},U = { A,G,B,E,F,D,C}。至此,集合 U 等于了 V,也就是构造出了最小生成树,最后将所有权值加起来的结果得到25,说明至少要修路25公里,普里姆算法结束。

2.3 代码实现
package algorithm.prim;import java.util.Arrays;public class PrimAlgorithm {public static void main(String[] args) {char[] data = new char[]{'A','B','C','D','E','F','G'};int verxes = data.length;int[][] weight = { // 邻接矩阵,约定 10000 代表不连通/*A*//*B*//*C*//*D*//*E*//*F*//*G*//*A*/{10000,5,7,10000,10000,10000,2},/*B*/{5,10000,10000,9,10000,10000,3},/*C*/{7,10000,10000,10000,8,10000,10000},/*D*/{10000,9,10000,10000,10000,4,10000},/*E*/{10000,10000,8,10000,10000,5,4},/*F*/{10000,10000,10000,4,5,10000,6},/*G*/{2,3,10000,10000,4,6,10000}};Graph graph = new Graph(verxes);MinTree minTree = new MinTree();minTree.createGraph(graph,verxes,data,weight);minTree.showGraph(graph);//普利姆算法minTree.prim(graph,0);}
}//创建最小生成树
class MinTree{//创建图的邻接矩阵/**** @param graph 图对象* @param verxes 图对应的顶点个数* @param data 图各个顶点的值* @param weight 图的邻接矩阵*/public void createGraph(Graph graph,int verxes,char data[],int[][] weight){int i,j;for(i = 0;i < verxes;i++){graph.data[i] = data[i];for(j = 0;j < verxes;j++){graph.weight[i][j] = weight[i][j];}}}//显示图的邻接矩阵public void showGraph(Graph graph){for(int[] link:graph.weight){System.out.println(Arrays.toString(link));}}//编写普利姆算法public void prim(Graph graph,int vNum){int[] visited = new int[graph.verxes];//判断顶点有没有被访问过,默认为0visited[vNum] = 1;//h1和h2记录两个顶点的下标int h1 = -1;int h2 = -2;int minWeight = 10000;//将minweight初试成一个较大的数,之后替换为最小权值for(int k = 1; k < graph.verxes;k++){//有n个顶点,算法结束后会有n-1条边//确定每一次生成的子图,和哪个结点的距离最近for(int i = 0;i < graph.verxes;i++){//i结点表示被访问过的节点for(int j = 0;j < graph.verxes;j++){//j表示还没有被访问过的节点if(visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight){//替换minweightminWeight = graph.weight[i][j];h1 = i;h2 = j;}}}System.out.println("边<" + graph.data[h1] + "," + graph.data[h2] + "> 权值:" + minWeight);//将当前找到的节点标记为已经访问visited[h2] = 1;//重置minweightminWeight = 10000;}}
}
class Graph{int verxes;//表示图的节点个数char[] data;//存放节点数据int[][] weight;//存放边,邻接矩阵public Graph(int verxes){this.verxes = verxes;data = new char[verxes];weight = new int[verxes][verxes];}
}
运行结果:
三、克鲁斯卡尔算法
3.1 克鲁斯卡尔算法的介绍
克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。其基本思想是按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路
首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止
3.2 应用场景
有北京有新增7个站点(A, B, C, D, E, F, G) ,现在需要修路把7个站点连通,各个站点的距离用边线表示(权) ,比如 A – B 距离 12公里。问:如何修路保证各个站点都能连通,并且总的修建公路总里程最短?

基本步骤:

最后形成一颗最小生成树,它包括的边依次是:<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>
Kruskal算法重点需要解决的两个问题
问题一 : 对图的所有边按照权值大小进行排序。
问题二 : 将边添加到最小生成树中时,怎么样判断是否形成了回路。
问题一,很好解决,采用排序算法进行排序即可。
问题二,处理方式是:记录顶点在”最小生成树”中的终点,顶点的终点是”在最小生成树中与它连通的最大顶点”。然后每次需要将一条边添加到最小生存树时,判断该边的两个顶点的终点是否重合,重合的话则会构成回路。
卡鲁斯卡尔算法的实现最麻烦的就是实现如何判断新添加的边是否和已选择的边构成回路,为此,引入了终点的概念:所有顶点按照从小到大(一般指索引大小)的顺序排列好之后,某个顶点的终点就是 “与它连通的最大顶点”。
下面将以实现过程的第三步为例,具体讲解一下判断回路的思想

在将<E,F> <C,D> <D,E>加入到最小生成树R中之后,这几条边的顶点就都有了终点:
(01) C的终点是F。
(02) D的终点是F。
(03) E的终点是F。
(04) F的终点是F。
所以,通过分析虽然<C,E>是权值最小的边。 但是 C 和 E 的终点都是 F, 即它们的终点相同, 因此, 将<C,E>加入最小生成树的话, 会形成回路。 这就是判断回路的方式。那么判别是否构成回路的方法就是:如果在加入之前的边的两个顶点的终点是同一个点,则说明出现了回路。
3.3 代码实现
package algorithm.kruskal;import java.util.Arrays;public class KruskalAlgorithm {private Edata[] edges; // 图中的边private int edgeNum;//边的个数private char[] vertexes;//顶点数组private int[][] matrix;//邻接矩阵private static final int INF = Integer.MAX_VALUE;// 使用INF表示两个顶点不能连通public static void main(String[] args) {char[] vertexes = {'A','B','C','D','E','F','G'};int[][] matrix = {//0表示自己和自己连接,有具体的权值就是能连通,INF表示不能连通/*A*//*B*//*C*//*D*//*E*//*F*//*G*//*A*/ { 0, 12, INF, INF, INF, 16, 14},/*B*/ { 12, 0, 10, INF, INF, 7, INF},/*C*/ { INF, 10, 0, 3, 5, 6, INF},/*D*/ { INF, INF, 3, 0, 4, INF, INF},/*E*/ { INF, INF, 5, 4, 0, 2, 8},/*F*/ { 16, 7, 6, INF, 2, 0, 9},/*G*/ { 14, INF, INF, INF, 8, 9, 0}};KruskalAlgorithm kruskalAlgorithm = new KruskalAlgorithm(vertexes, matrix);kruskalAlgorithm.print();kruskalAlgorithm.kruskal();}public KruskalAlgorithm(char[] vertexes, int[][] matrix){//初始化顶点数和边的个数int vlen = vertexes.length;//初始化顶点,复制拷贝的方式this.vertexes = new char[vlen];for (int i = 0;i < vertexes.length;i++){this.vertexes[i] = vertexes[i];}//初始化邻接矩阵的行和边this.matrix = new int[vlen][vlen];for (int i = 0;i < vlen;i++){for(int j = 0; j < vlen;j++){this.matrix[i][j] = matrix[i][j];}}//统计边for(int i = 0;i < vlen;i++){for (int j = i + 1;j < vlen;j++){if(this.matrix[i][j] != INF){edgeNum++;}}}//获取图中的边,放到Edata数组中,通过邻接矩阵来获取int index = 0;edges = new Edata[edgeNum];for(int i = 0;i < vertexes.length;i++){for(int j = i + 1;j < vertexes.length;j++){if(this.matrix[i][j] != INF){edges[index++] = new Edata(vertexes[i], vertexes[j], matrix[i][j]);}}}}//生成最小生成树public void kruskal(){int index = 0;//表示最后结果数组的索引int[] end = new int[edgeNum];//用于保存已有生成树的顶点的终点//创建结果Edata[] res = new Edata[edgeNum];//获取图中所有的边的集合,一共有12条边System.out.println("获取图的边的集合" + Arrays.toString(edges) + "共" + edges.length + "条边");//按照边的权值大小排序Arrays.sort(edges);for(int i = 0; i < edgeNum;i++){//获取到第i条边的第一个起点和终点int p1 = getPosition(edges[i].start);int p2 = getPosition(edges[i].end);//获取p1/p2这个顶点在已有最小生成树中的终点int m = getEnd(end,p1);int n = getEnd(end,p2) ;//是否构成回路if(m != n){end[m] = n;//设置m在已有最小生成树的终点res[index++] = edges[i];//有一条边加入到res数组中}}System.out.println("最小生成树为=");for(int i = 0;i < index;i++){System.out.println(res[i]);}}//打印邻接矩阵的方法public void print(){System.out.println("邻接矩阵为");for (int i = 0;i < vertexes.length;i++){for (int j = 0; j < vertexes.length;j++){System.out.printf("%-12d\t",matrix[i][j]);}System.out.println();}}//获取顶点的下标值private int getPosition(char ch){for(int i = 0;i < vertexes.length;i++){if(vertexes[i] == ch){return i;}}return -1;}/*** @param ends 记录各个顶点对应的终点* @param i 表示传入的顶点对应的下标* @return*///获取下标为i的顶点的终点private int getEnd(int[] ends, int i){while(ends[i] != 0){i = ends[i];}return i;}
}//Edata类,它的对象实例就是一条边
class Edata implements Comparable<Edata>{char start;//边的一个点char end;//边的终点int weight;//边的权值//构造器public Edata(char start, char end, int weight) {this.start = start;this.end = end;this.weight = weight;}@Overridepublic String toString() {return"{<" + start +"," + end +">, weight=" + weight + "}";}@Overridepublic int compareTo(Edata o) {return this.weight - o.weight;}
}运行结果:

这篇关于最小生成树和普利姆算法及克鲁斯卡尔算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



