本文主要是介绍TiDB故障处理之让人迷惑的Region is Unavailable,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
最近某集群扩容了一批物理机,其中 TiKV 节点有6台机器12个实例,同时调整了 label 设置增加了一层机柜级容灾。因为前期做了比较充分的准备工作,到了变更窗口只等着执行scale-out就行,操作过程也很顺利,很快就把所有节点都扩进去了,检查完各实例的运行状态,确保region已经开始正常调度,就放心去睡觉了(半夜变更,结束时凌晨1点左右)。
第二天一大早还在上班路上,业务方反馈数据库有部分SQL报错Region is Unavailable,怀疑新扩容的 TiKV 节点出了问题,火速赶到公司开始排查。
此时内心os,打工人1024不加班的小小心愿要破灭了。。🤣
故障现象
业务方反馈的报错信息如下:

其实Region is Unavailable不算什么疑难杂症,从过往经验来判断基本是 TiKV 节点的原因,从字面意思上看就是region在某段时间内不可用,可能的因素有:
-
region leader在调度中,或者无法选举出leader(会有内部backoff)
-
tikv实例繁忙被限流,同步可能会有
TiKV server is busy报错
-
tikv实例故障挂掉了,同步可能会有
TiKV server is timeout报错
-
其他tikv未知问题或bug等
前三种基本能覆盖90%以上的场景,所以我一开始还是从tikv着手排查。
但是让人迷惑的是,各种分析下来最后发现和tikv没有关系,这就是最有意思的点。🙈
好戏开始。
排查过程
首先检查前一天晚上扩容的12个tikv实例运行状态,分析监控和日志并未发现有异常现象,无重启,各节点负载也很低不存在性能瓶颈。
接着怀疑是偶发性报错,因为region还处于调度中(到这里感觉到了调度不太正常,比预期中的要慢),偶发性还是有可能的,另外通过监控面板failed query OPM发现tikv:9005报错码只是零星出现,也不排除这种可能性。
验证方式:从dashboard日志搜索中找出具体报错的SQL,直接用报错码搜索即可:
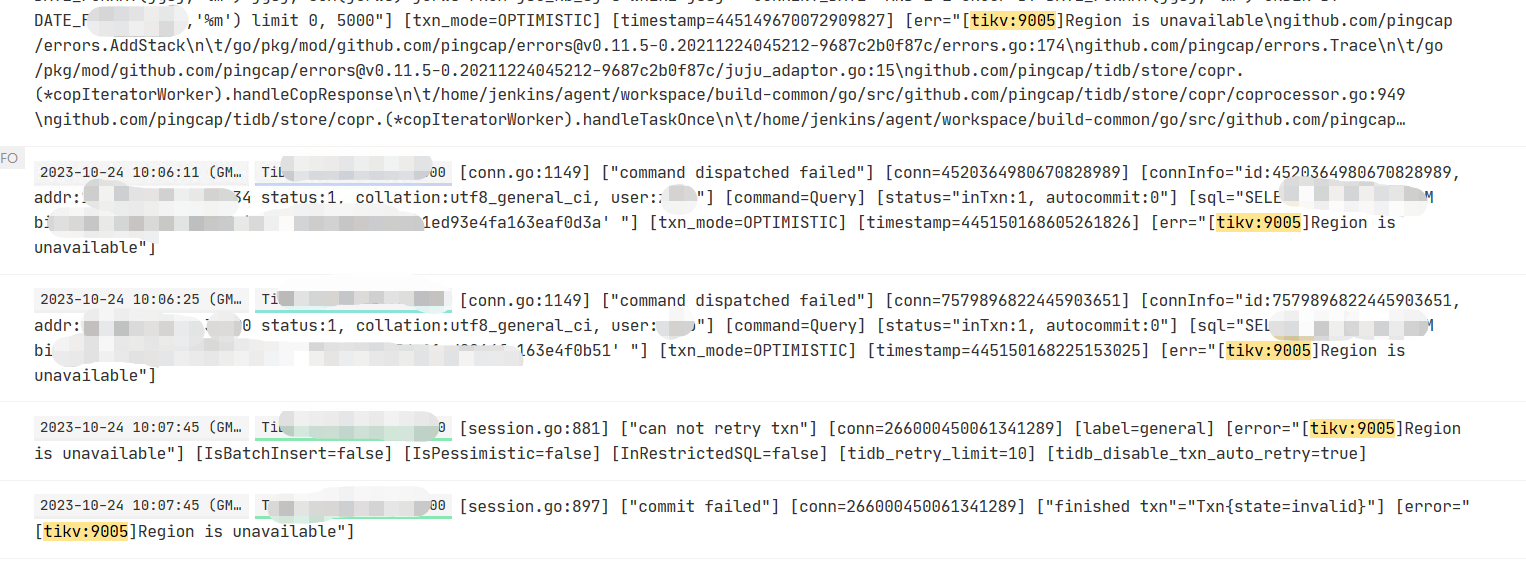
把SQL拿出来尝试手动执行,发现也报同样的错,多次执行效果一样。于是怀疑这张表的region有副本丢失,打算用show table regions看下这张表的region分布,发现了一个奇怪的报错:

从报错信息看,在执行show table regions的时候tidb server去请求了pd的一个API,这个API是作用是查询region id为xxx的详细信息,但是无法访问pd节点。跟着报错信息,我去检查了这个pd节点的状态,发现没有任何异常,服务正常运行未发生过重启。
接着我进去pd-ctl用报错的region id查询region信息,也能够正常返回,确认pd节点正常。
退出客户端,手动执行curl API,报错依旧,telnet测试报错pd实例,无法连接,然后把三个pd都telnet了一遍,发现只有这一个pd无法访问,异常诡异,初步怀疑网络有问题。
但是扩容前网络环境都检查过都是联通状态,而且都在同一个网段中,不应该有网络故障。
接着转头去看那个连接不上的pd节点日志,跟踪了一段时间发现绝大部分都是region调度的信息,但是一点一点翻发现中间偶尔出现operator timeout的字样,认真把日志读了几遍总算看清楚了它说的啥,大意就是在两个store之间mv peer超时(应该是10min)失败了:
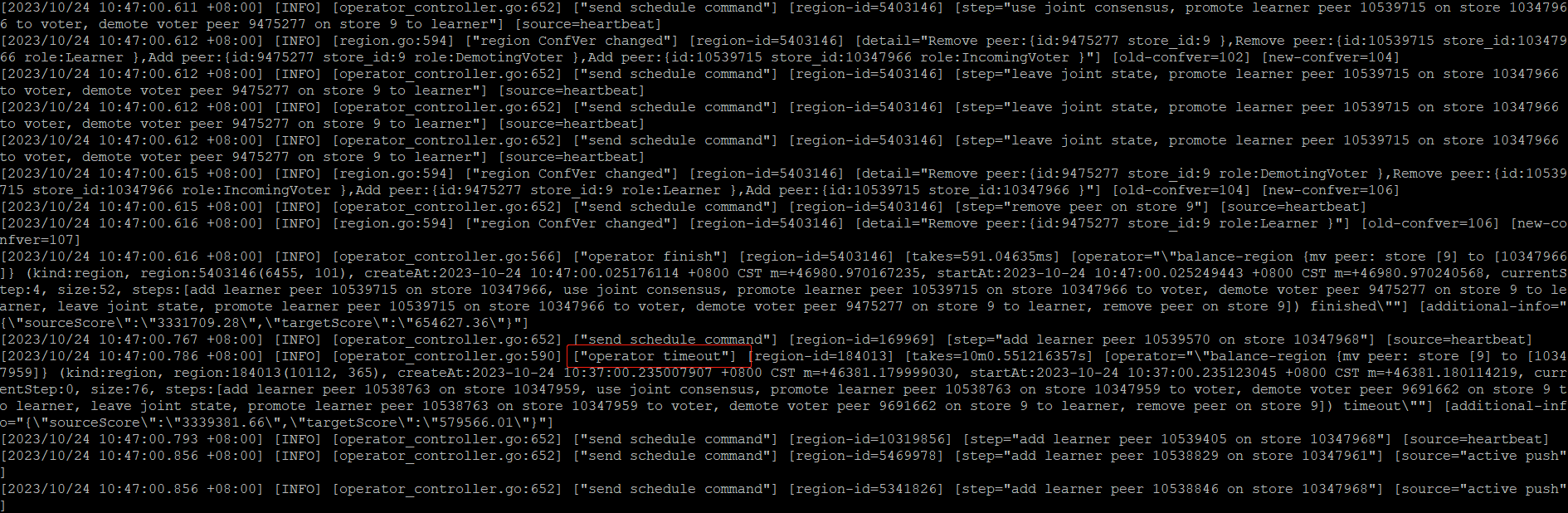
期间并没有发现pd自身运行异常问题,回想起前面的调度慢,猜测应该和这个现象有关,貌似和Region is Unavailable有一点点沾边了,但还不能完全解释过去,继续怀疑网络。
吐槽:给个WARN日志是不是好点
接着命令行登录原有的tidb实例,再次执行报错的SQL和show table regions,神奇的事情发生了,均能够正常返回。再换另一台新扩的tidb节点执行,报错依旧。
到这里基本判定是新扩进来的tidb实例有问题,此时距离故障出现超过2小时,业务方开始着急了,无奈之下只能把新扩的tidb实例从负载均衡中剔除临时绕过,详细原因进一步排查。
重新梳理了一下思路,我们都知道正常select查询和show table regions都需要从pd获取表的region分布信息,这个请求是从被连接的tidb server上发起的,现在奇怪的地方是新扩容的tidb server无法访问pd,原有的可以访问,那说明极有可能是新节点被限制访问了。
登录pd节点查看防火墙状态,是关闭状态,进一步检查发现iptables服务开启,查看配置规则后虎躯一震:

这简直是在不亚于在代码里下毒啊,所有tidb集群相关的通信端口全都显式地做了限制,只允许原集群的5台机器访问,做了也不算啥,偏偏有的做有的不做,这就有点坑了。。。而且这台机器上还部署了2个tikv实例,那前面operator timeout也说的通了。
至此复盘一下问题:原集群某些节点设置iptables规则,限制集群外的节点无法与tidb内部服务通信,新扩容的机器并不知道有这个限制,导致新扩容的tidb server无法从pd获取region信息,连接到新tidb server的会话无法读到region,抛出Region is Unavailable报错。同时该节点上的tikv实例无法与新扩容的tikv实例通信,导致region调度受影响,直观感受是调度非常慢。
回过头再看,还好故障比较简答,1024算是保住了。
解决方案
经过各方沟通,得知iptables是为了解决早期某安全漏扫问题设置,现在也没办法直接关掉。那么解决办法就只有一条路,把新扩容的所有机器ip都加到iptables白名单里即可,顺便也检查了原有的5台机器iptables设置情况,该加的都加上。
vi /etc/iptables.rules
systemctl restart iptables调整完毕后重新用客户端登录新扩容的tidb server执行SQL,发现一切都恢复正常了。
同时region迁移也明显加速,修改前:
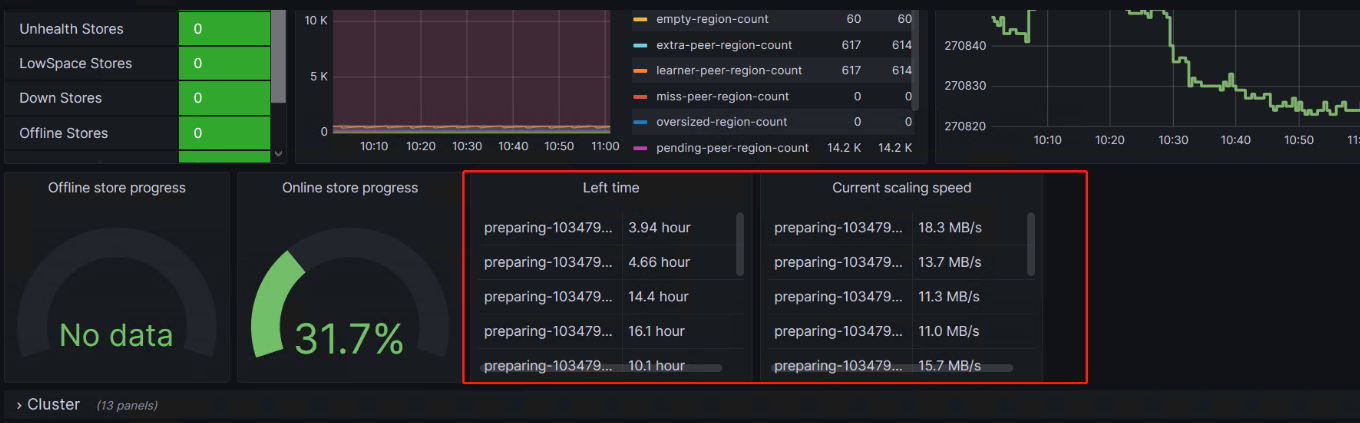
修改后:
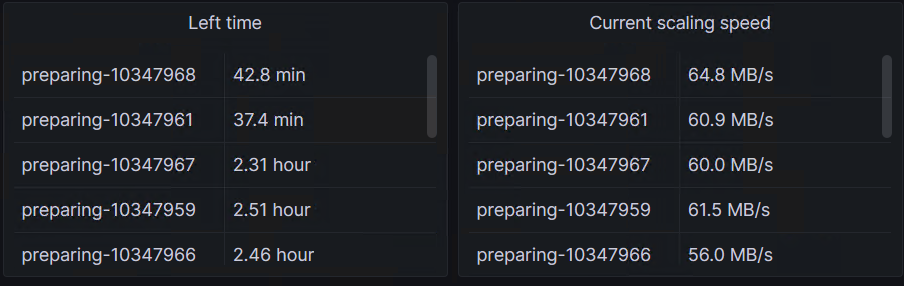
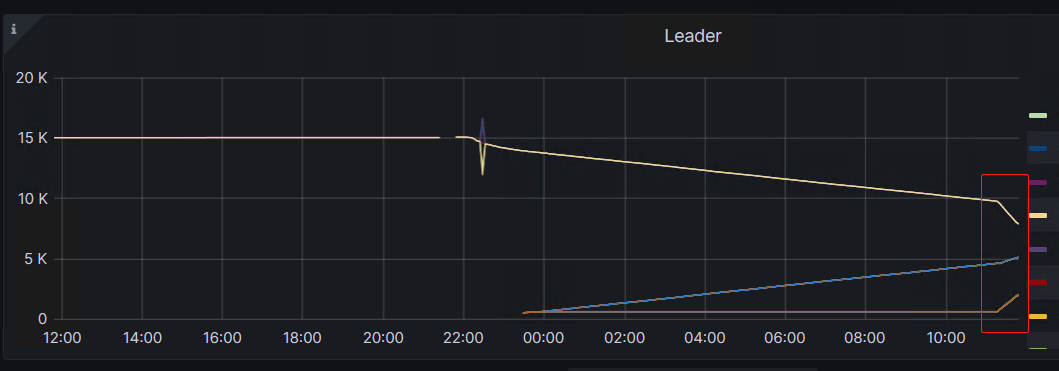
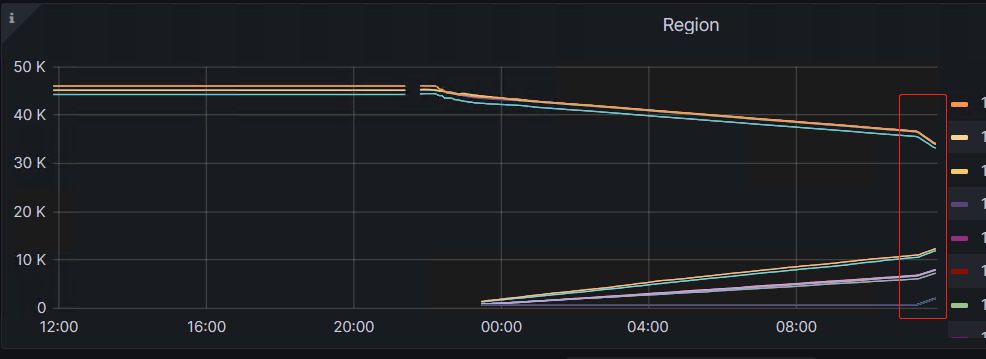
总结
看似一个简单的操作就解决了问题,实际背后隐藏了很多工作在里面,碰到问题不可怕,重要的是要有清晰的思路,综合运用自己的经验。
就像有个故事里说的,知道在哪画线比会画线更值钱,troubleshooting就是核心竞争力。
文章转载自:balahoho
原文链接:https://www.cnblogs.com/hohoa/p/17932468.html
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
这篇关于TiDB故障处理之让人迷惑的Region is Unavailable的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





