本文主要是介绍书同文车同轨:数据治理之数据标准管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面:
这是一个系列文章,沉淀了我在数据治理领域的一些实践和思考。共分为5篇。分别是:
一、大数据治理:那些年,我们一起踩过的坑
主要讲讲数据治理工作中常见的一些误区。
二、要打仗,你手里先得有张地图:数据治理之元数据管理
这一篇讲讲元数据的概念和具体应用场景。
三、不忘初心方得始终:数据治理之数据质量管理
提升数据质量,始终是数据治理工作中最重要的目标之一。本篇讲述如何科学地进行数据质量管理。
四、书同文车同轨:数据治理之数据标准管理
数据标准的落地始终是难题。本篇希望能提供一些数据标准建设的思路。
五、大数据的淘金之旅,数据治理之数据资产管理
不管厂商把它们叫什么:业务标签,数据资产,还是知识图谱管理,本质上都是从数据中提炼出来的资产。怎么管理和应用好这些资产,是现今数据治理的重要研究课题
这些观点是一家之言,欢迎同仁们商榷,共同探讨数据治理相关领域的问题。
谢谢。
正文:
一、大数据标准体系
根据全国信息技术标准化技术委员会大数据标准工作组制定的大数据标准体系,大数据的标准体系框架共由七个类别的标准组成,分别为:基础标准、数据标准、技术标准、平台和工具标准、管理标准、安全和隐私标准、行业应用标准。本文主要阐述其中的第二个类别:数据标准。
二、关于数据标准认识的几个误区
数据标准这个词,最早是在金融行业,特别是银行业的数据治理中开始使用的。数据标准工作一直是数据治理中的基础性重要内容。但是对于数据标准,不同的人却有不同的看法:
有人认为数据标准极其重要,只要制定好了数据标准,所有数据相关的工作依标进行,数据治理大部分目标就水到渠成了。
也有人认为数据标准几乎没什么用,做了大量的梳理,建设了一整套全面的标准,最后还不是被束之高阁,被人遗忘,几乎没有发挥任何作用。
首先亮明作者的观点:这两种看法都是不对的,至少是片面的。实际上,数据标准工作是一项复杂的,涉及面广的,系统性的,长期性的工作。它既不能快速地发挥作用,迅速解决掉数据治理中的大部分问题,同时也肯定不是完全没有作用,最后只剩下一堆文档——如果数据标准工作的结局真是如此,那只能说明这项工作没有做好,没有落到实处。本文主要的目的,就是分析为什么会出现这种情况,以及如何应对。而首先需要做的是厘清数据标准的定义。
三、数据标准的定义
何为数据标准,各相关组织并没有统一的,各方都认可的定义。结合各家对数据标准的阐述,从数据治理的角度出发,我尝试着给数据标准做一个定义:数据标准是对数据的表达、格式及定义的一致约定,包含数据业务属性、技术属性和管理属性的统一定义;数据标准的目的,是为了使组织内外部使用和交换的数据是一致的,准确的。
四、如何制定数据标准
一般来说,对于政府,会有国家或地方政府发文的数据标准管理办法,其中会详细规定相关的数据标准。所以在此主要讲企业如何制定数据标准。
企业的数据标准来源非常丰富,有外部的监管要求,行业的通用标准,同时也必须考虑到企业内部数据的实际情况,梳理其中的业务指标、数据项、代码等,将以上的所有的来源都纳入数据标准是没有必要的,数据标准的范围应该主要集中在企业业务最核心的数据部分,有的企业也称作关键业务数据或核心数据,只要制定出这些核心数据的标准,就能够支撑企业数据质量、主数据管理、数据分析等需要。
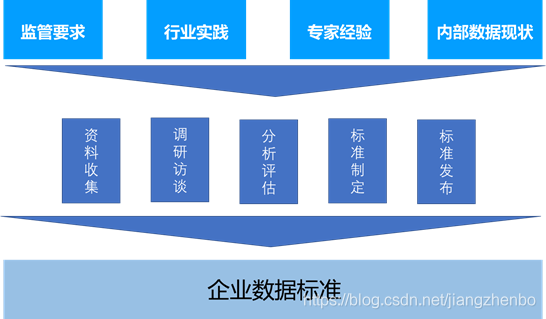
五、数据标准化的难题
数据标准好制定,但是数据标准落地相对就困难多了。国内的数据标准化工作发展了那么多年,各个行业,各个组织都在建设自己的数据标准,但是你很少听到哪个组织大张旗鼓地宣传自己的数据标准工作多么出色,换句话说,做数据标准取得显著效果的案例并不多。为什么会出现这种情况,主要有两个原因:
一是制定的数据标准本身有问题。有些标准一味地追求先进,向行业领先看齐,标准大而全,脱离实际的数据情况,导致很难落地。
第二个原因,是标准化推进过程中出了问题。这是我们重点阐述的原因,主要有以下几种情况:
- 对建设数据标准的目的不明确。某些组织建设数据标准,其目的不是为了指导信息系统建设,提高数据质量,更容易地处理和交换数据,而是应付监管机构检查,因此需要的就是一堆标准文件和制度文件,根本就没有执行的计划。
- 过分依赖咨询公司。一些组织没有建设数据标准的能力,因此请咨询公司来帮忙规划和执行。一旦咨询公司撤离,组织依然缺乏将这些标准落地的能力和条件。
- 对数据标准化的难度估计不足。很多公司上来就说要做数据标准,却不知道数据标准的范围很大,很难以一个项目的方式都做完,而是一个持续化推进的长期过程,结果是客户越做遇到的阻力越大,困难越多,最后自己都没有信心了,转而把前期梳理的一堆成果束之高阁,这是最普遍的问题。
- 缺乏落地的制度和流程规划。数据标准的落地,需要多个系统、部门的配合才能完成。如果只梳理出数据标准,但是没有规划如何落地的具体方案,缺乏技术、业务部门、系统开发商的支持,尤其是缺乏领导层的支持,是无论如何也不可能落地的。
- 组织管理水平的不足:数据标准落地的长期性、复杂性、系统性的特点,决定了推动落地的组织机构的管理能力必须保持在很高的水平线上,且架构必须持续稳定,才能有序地不断推进。
以上这些原因,导致数据标准化工作很难开展,更难取得较好的成效。数据标准化难落地,是数据治理行业的现状,不容回避。
六、如何应对这些难题
应对以上这些难题,最经济、最理想的模式当然是:做大数据建设,首先做标准,再做大数据平台,数据仓库等。但一般的不大可能有这样的认识,很多时候大家都是先建设再治理。先把信息系统、数据中心建好,然后标准有问题,质量不高,再建数据标准,但实际上这时候已经是回过头来做一些亡羊补牢的事情,客户的投资肯定有一部分是浪费。
正因为其太过理想化,所以这种模式几乎是见不到的。在实践中,我们往往还是需要更多地考虑如何把数据标准落地到已有的系统和大数据平台中。
数据标准落地有三种形式:
- 源系统改造:对源系统的改造是数据标准落地最直接的方式,有助于控制未来数据的质量,但工作量与难度都较高,现实中往往不会选择这种方式,例如有客户编号这个字段,涉及多个系统,范围广、重要程度高、影响大,一旦修改该字段,会涉及到相关的系统都需要修改。但是也不是完全不可行,可以借系统改造,重新上线的机会,对相关源系统的数据进行部分的对标落地。
- 数据中心落地:根据数据标准要求建设数据中心(或数据仓库),源系统数据与数据中心做好映射,保证传输到数据中心的数据为标准化后的数据。这种方式的可行性较高,是绝大多数组织的选择。
- 数据接口标准化:对已有的系统间的数据传输接口进行改造,让数据在系统间进行传输的时候,全部遵循数据标准。这也是一种可行的方法。
在数据标准落地的过程中,需要做好6件事情,如下图所示:
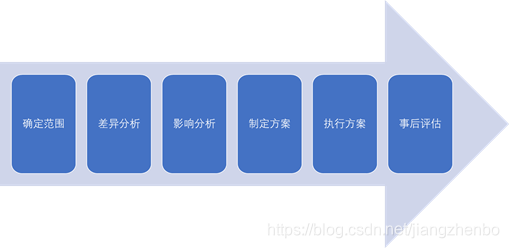
- 事先确定好落地的范围:哪些数据标准需要落地,涉及到哪些IT系统,都是需要事先考虑好的。
- 事先做好差异分析:现有的数据和数据标准之间,究竟存在哪些差异,这些差异有多大,做好差异性分析。
- 事先做好影响性分析:如果这些数据标准落地了,会对哪些相关下游戏厅产生什么样的影响,这些影响是否可控。元数据管理中的影响性分析可以帮助用户确定影响的范围。
- 制定落地的执行方案:执行方案要侧重于可落地性。不能落地的方案,最终只能被废弃。一个可落地的方案,要有组织架构和人员分工,每个人负责什么,如何考核,怎么监管,都是必须纳入执行方案中的内容。
- 具体地执行落地方案:根据执行方案,进行数据标准落地执行。
- 事后评估:事后需要跟踪、评估数据落地的效果如何,做对了哪些事,哪些做得不足,如何改进。
七、总结
数据标准的建设大致可以分成两个阶段:
1、梳理和制定数据标准。
2、数据标准的落地和实施。
其中后者是公认的难题。本文分析了其中的原因,提供了一些如何让数据标准更快更好落地的方法。
作者信息:
蒋珍波,大数据专家,擅长为客户提供科学合理的大数据解决方案,尤其擅长数据治理、数据中台解决方案。曾先后供职于东南融通、普元信息、数澜科技、数梦工场等公司,负责过数据仓库、大数据平台、数据中台、数据治理等售前咨询工作,和技术团队的管理工作,有政府、大中型企业等多个行业经验。著有畅销专业书籍《数据中台》、《一本书讲透IT售前》。
这篇关于书同文车同轨:数据治理之数据标准管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






