本文主要是介绍DataWhale-(scikit-learn教程)-Task07(集成学习)-202112,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、基本原理
集成学习(ensemble learning) 通过构建并结合多个学习器来完成学习任务,以提高比单个学习器更好的泛化和稳定性能。要获得好的集成效果,个体学习器应该“好而不同”。按照个体学习器的生成方式,集成学习可分为两类:序列集成方法,即个体学习器存在强依赖关系,必须串行生成,如Boosting;并行集成方法,即个体学习器不存在强依赖关系,可以并行生成,如Bagging,随机森林。
二、Boosting
Boosting指的是通过算法集合将弱学习器转换为强学习器。Boosting的主要原则是训练一系列的弱学习器,所谓弱学习器是指仅比随机猜测好一点点的模型,例如较小的决策树,训练的方式是利用加权的数据。在训练的早期对于错分数据给予较大的权重。 其工作机制如下:
- 先从初始训练集训练出一个基学习器;
- 再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注;
- 基于调整后的样本分布来训练下一个基学习器;
- 重复进行上述步骤,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。
以下介绍几种典型的Boosting方法。

import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as pltwine = load_wine()
print(f"所有特征:{wine.feature_names}")
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)base_model = DecisionTreeClassifier(max_depth=1, criterion='gini',random_state=1).fit(X_train, y_train)
y_pred = base_model.predict(X_test)
print(f"决策树的准确率:{accuracy_score(y_test,y_pred):.3f}")from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(base_estimator=base_model,n_estimators=50,learning_rate=0.5,algorithm='SAMME.R',random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"AdaBoost的准确率:{accuracy_score(y_test,y_pred):.3f}")# 测试估计器个数的影响
x = list(range(2, 102, 2))
y = []for i in x:model = AdaBoostClassifier(base_estimator=base_model,n_estimators=i,learning_rate=0.5,algorithm='SAMME.R',random_state=1)model.fit(X_train, y_train)model_test_sc = accuracy_score(y_test, model.predict(X_test))y.append(model_test_sc)plt.style.use('ggplot')
plt.title("Effect of n_estimators", pad=20)
plt.xlabel("Number of base estimators")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()# 测试学习率的影响
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
y = []for i in x:model = AdaBoostClassifier(base_estimator=base_model,n_estimators=50,learning_rate=i,algorithm='SAMME.R',random_state=1)model.fit(X_train, y_train)model_test_sc = accuracy_score(y_test, model.predict(X_test))y.append(model_test_sc)plt.title("Effect of learning_rate", pad=20)
plt.xlabel("Learning rate")
plt.ylabel("Test accuracy of AdaBoost")
plt.plot(x, y)
plt.show()# 使用GridSearchCV自动调参
hyperparameter_space = {'n_estimators':list(range(2, 102, 2)), 'learning_rate':[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]}gs = GridSearchCV(AdaBoostClassifier(base_estimator=base_model,algorithm='SAMME.R',random_state=1),param_grid=hyperparameter_space, scoring="accuracy", n_jobs=-1, cv=5)gs.fit(X_train, y_train)
print("最优超参数:", gs.best_params_)


三、Bagging




三、Stacking
1. Stacking 的基本思想
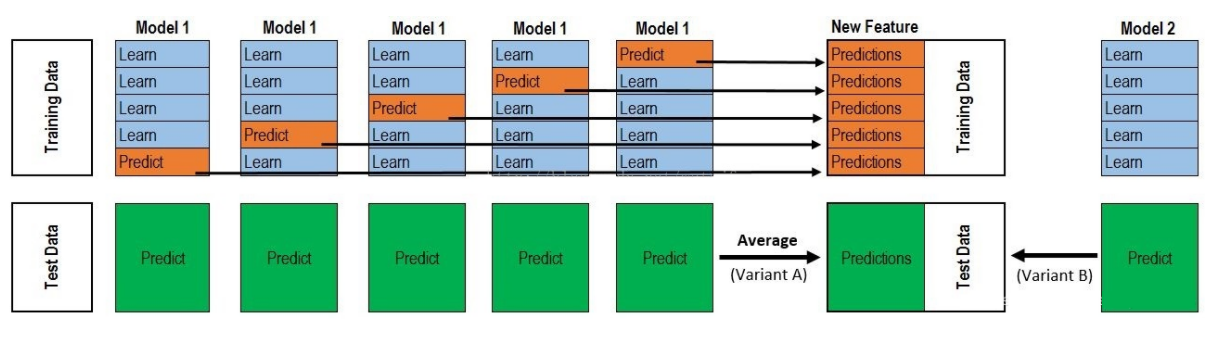
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。

这篇关于DataWhale-(scikit-learn教程)-Task07(集成学习)-202112的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







