本文主要是介绍数据冒险之单链表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
定义链表的结点:Node.h
#ifndef NODE_H
#define NODE_Hclass Node
{
public:int data;Node *next;void printNode();
};
#endif 打印结点数据:Node.cpp
#include"Node.h"
#include<iostream>
using namespace std;void Node::printNode()
{cout << data << endl;
}List.h
/*单链表*/
#ifndef LIST_H
#define LIST_H#include"Node.h"
class List
{
public:List(); //创建线性表 ~List(); //销毁线性表 void ClearList(); //清空 bool ListEmpty(); //判空 int ListLength(); //获取线性表长度 bool GetElem(int i, Node *pNode); //获取指定元素 int LocateElem(Node *pNode); //定位元素 寻找第一个满足e的元素的位序 bool PriorElem(Node *pCurrentNode, Node *pPreNode);//获取指定元素的前驱 bool NextElem(Node *pCurrentNode, Node *pNextNode);//获取指定元素的后继 void ListTraverse(); //遍历线性表 bool ListInsert(int i, Node *pNode); //在第i个位置插入元素 bool ListDelete(int i, Node *pNode); //删除第i个位置的元素 bool ListInsertHead(Node *pNode);bool ListInsertTail(Node *pNode);
private:Node *m_pList;int m_iLength;//当前长度
};
#endif#include<iostream>
#include"List.h"
using namespace std;List::List()
{m_pList = new Node;m_pList->data = 0;m_pList->next = NULL;m_iLength = 0;
}
List::~List()
{ClearList();delete m_pList;m_pList = NULL;
}
void List::ClearList()
{Node *currentNode = m_pList->next;while (currentNode != NULL){Node *temp = currentNode->next;delete currentNode;currentNode = temp;}m_pList->next = NULL;m_iLength = 0;
}
bool List::ListEmpty()
{if (0 == m_iLength)return true;elsereturn false;}
int List::ListLength()
{return m_iLength;
}
bool List::GetElem(int i, Node *pNode)
{if (i<0 || i >= m_iLength)return false;Node *currentNode = m_pList;for (int k = 0; k <= i; k++){currentNode = currentNode->next;}pNode->data = currentNode->data;return true;
}
int List::LocateElem(Node *pNode)
{Node *currentNode = m_pList;int count = 0;while (currentNode->next != NULL){currentNode = currentNode->next;if (currentNode->data == pNode->data){return count; //小细节:当有重复时,只会返回第一次出现的 }count++;//为什么放后面?小细节:头节点数据域无意义,0是我们找到的头节点后的第一个节点 }return -1;
}bool List::PriorElem(Node *pCurrentNode, Node *pPreNode)
{Node *currentNode = m_pList;Node *currentNodeBefore = NULL;while (currentNode->next != NULL){currentNodeBefore = currentNode;currentNode = currentNode->next;if (currentNode->data == pCurrentNode->data){if (currentNodeBefore == m_pList)return false;pPreNode->data = currentNodeBefore->data;return true;}}return false;}
bool List::NextElem(Node *pCurrentNode, Node *pNextNode)
{Node *currentNode = m_pList;while (currentNode->next != NULL){currentNode = currentNode->next;if (currentNode->data == pCurrentNode->data){if (currentNode->next == NULL)return false;pNextNode->data = currentNode->next->data;return true;}}return false;
}void List::ListTraverse()
{Node *currentNode = m_pList;while (currentNode->next != NULL){currentNode = currentNode->next;currentNode->printNode();}cout << "m_iLength = " << m_iLength << endl;
}bool List::ListInsertHead(Node *pNode)
{Node *temp = m_pList->next; //头节点指向下一个结点的地址赋给temp保存起来Node *newNode = new Node;if (newNode == NULL) //如果申请内存失败return false;newNode->data = pNode->data;//数据域先赋给新结点m_pList->next = newNode; //头结点与新结点连接newNode->next = temp; //新结点与后面结点连接的m_iLength++; //插入成功长度加1return true;}bool List::ListInsertTail(Node *pNode)
{Node *currentNode = m_pList;while (currentNode->next != NULL) //先找到尾结点{currentNode = currentNode->next;}Node *newNode = new Node;if (newNode == NULL) //申请内存是否成功return false;newNode->data = pNode->data; //数据域先赋给新结点newNode->next = NULL; //插入后充当尾部currentNode->next = newNode; // 插入前的尾部与新结点连接m_iLength++; //插入成功长度加1return true;
}bool List::ListInsert(int i, Node *pNode)
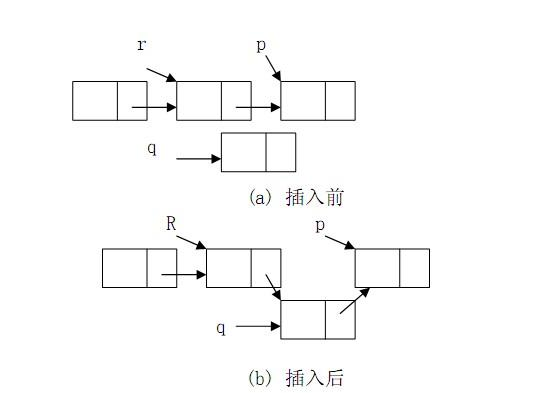
{if (i<0 || i>m_iLength) //插入位置合理性判断return false;Node *currentNode = m_pList;for (int k = 0; k<i; k++) //找到要插入的位置{currentNode = currentNode->next;}Node *newNode = new Node; //申请新结点if (newNode == NULL) //申请是否成功return false;newNode->data = pNode->data; //数据域传入newNode->next = currentNode->next;//当前结点所指向的下一结点的地址传给新结点currentNode->next = newNode;//当前结点与新结点连接m_iLength++; //插入成功长度加1return true;
}bool List::ListDelete(int i, Node *pNode)
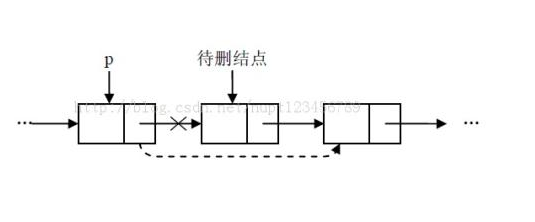
{if (i<0 || i >= m_iLength) //删除合理性判断return false;Node *currentNode = m_pList;Node *currentNodeBefore = NULL;//当前结点前一结点for (int k = 0; k <= i; k++) //找到删除位置和前一结点{currentNodeBefore = currentNode;currentNode = currentNode->next;}currentNodeBefore->next = currentNode->next;//当前结点的前一结点与其后一结点直接相连,相当于删除当前结点pNode->data = currentNode->data;//删除数据传出delete currentNode; //释放内存,已经没用了currentNode = NULL; //为了安全指为NULLm_iLength--; //删除成功长度-1return true;
}
main.cpp
#include<iostream>
#include"List.h"
using namespace std;int main(void)
{Node node1;node1.data = 3;Node node2;node2.data = 4;Node node3;node3.data = 5;Node node4;node4.data = 6;Node node5;node5.data = 77;List *pList = new List();cout << "从头部插入:" << endl;pList->ListInsertHead(&node1);pList->ListInsertHead(&node2);pList->ListInsertHead(&node3);pList->ListInsertHead(&node4);pList->ListTraverse();cout << "清除~~~";pList->ClearList();cout << "清除~~~DONE" << endl;cout << "从尾部插入:" << endl;pList->ListInsertTail(&node1);pList->ListInsertTail(&node2);pList->ListInsertTail(&node3);pList->ListInsertTail(&node4);pList->ListTraverse();cout << "从位置2插入 :" << endl;pList->ListInsert(2, &node5);pList->ListTraverse();cout << "从位置3删除 :" << endl;Node temp;pList->ListDelete(3, &temp);pList->ListTraverse();cout << "从位置1取出放入temp" << endl;pList->GetElem(1, &temp);cout << "temp = " << temp.data << endl;pList->PriorElem(&node2, &temp);cout << "从位置1取前驱temp" << endl;cout << "temp = " << temp.data << endl;pList->NextElem(&node2, &temp);cout << "从位置1取后继temp" << endl;cout << "temp = " << temp.data << endl;cout << "isEmpte:" << boolalpha << pList->ListEmpty() << endl;delete pList;pList = NULL;return 0;
}
这篇关于数据冒险之单链表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





