本文主要是介绍全网最细,Web自动化测试-数据驱动测试(超强整理),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
1、什么是数据驱动测试
数据驱动测试被称为DDT:
D-data:数据
D-driver:驱动
T:tests:测试用例
数据驱动测试的使用场景:
将不同的数据放在同一个业务逻辑上运行,然后驱动测试用例执行
核心思想:实现一个用例脚本使用不同的参数数据进行全部的用例执行
2、pytest实现参数化流程
对于一样的用例执行流程,使用不同的参数数据可以进行数据驱动测试
实现参数化流程
安装第三库pytest测试框架
创建模块以及用例函数名都需要符合pytest默认的匹配规则
调用pytest标记参数化进行实现
import pytest@pytest.mark.parametrize(["username", "password"], [
[123, 456],
[789, 120],
["a", "b"],
["i", "o"],
])
def test_a(username, password):print(f"输入用户名:{username}")print(f"输入密码:{password}")
pytest -vs
3、获取数据的方式
在实现参数化结合数据驱动测试过程中,如果数据量比较大,那么不会直接使用固定列表中的实参
一般会放置文件中保持起来,需要使用的时候通过读取不同类型的文件数据进行符合参数化的标准
数据保存的文件格式类型:
Text文本
Csv文件
Excel文件
Json文件
Yaml文件
…
1)Text文本数据读取
读取文本数据进行数据处理符合参数化的标准:
def get_text_data():with open(r"D:\pythonProject54\用户名密码.txt",encoding="utf-8") as f:# 读取的每一行数据都有换行符# 列表中的每一个数据都是字符串不符合参数化的标准# 参数化的标准实参:列表中嵌套列表/元组# 处理数据方案:除去换行符,整理数据列表嵌套列表# print(f.readlines())list1 = []for i in f.readlines():list1.append(i.strip())else:# print(list1)list2 = []for i in list1:list2.append(i.split(","))else:# print(list2)# 符合参数化实参标准进行返回return list2# print(get_text_data())
数据处理完成之后的调用:
@pytest.mark.parametrize(["username2", "password2"], get_text_data())
def test_b(username2, password2):print(f"输入用户名:{username2}")print(f"输入密码:{password2}")
2)Csv文件数据读取
定义:逗号分隔值,以文本文件储存方式,表现形式是以表格的格式展示
使用csv文件的步骤:
新建一个文本文件
每个数据之间用,隔开
保存文件,然后修改文件的后缀名:text—csv
进行数据读取并且使用
# 读取csv文件数据内容
def get_csv_data():c1 = csv.reader(open(r"D:\pythonProject54\登录账号密码.csv", encoding="utf-8"))list1 = []for i in c1:list1.append(i)else:# print(list1)return list1# get_csv_data()
csv文件结合pytest参数化实现数据驱动测试使用
@pytest.mark.parametrize(["username3", "password3", "code3"], get_csv_data())
def test_c(username3, password3, code3):print(f"输入用户名:{username3}")print(f"输入密码:{password3}")print(f"输入验证码:{code3}")
项目实战中参数化实现数据驱动测试场景:
@pytest.mark.parametrize(["username3", "password3", "code3"], get_csv_data())
def test_admin_login(username3, password3, code3):# 获取驱动对象driver = webdriver.Chrome()# 访问被测页面driver.get('http://localhost/index.php/Admin/Admin/login')# 页面最大化driver.maximize_window()# 构造线性脚本执行用例# 输入账号driver.find_element(By.XPATH, '//*[@id="theForm"]/div/div[1]/div[2]/div[1]/input').send_keys(username3)# 输入密码driver.find_element(By.XPATH, '//*
[@id="theForm"]/div/div[1]/div[2]/div[2]/input').send_keys(password3)# 输入验证码driver.find_element(By.XPATH, '//*
[@id="theForm"]/div/div[1]/div[2]/div[3]/input').send_keys(code3)# 点击登录driver.find_element(By.XPATH, '//*
[@id="theForm"]/div/div[1]/div[2]/div[5]/span/input').click()# 获取实际结果# 断言预期结果和实际结果# 添加日志信息,缺陷报告....
3)Excel文件数据读取
Excel和Csv文件区别:
文件储存格式不一样:
Excel二进制
Csv文本格式
功能不一样:
Excel公式数据处理方式
Csv简单的数据表格显示
使用效率:
Csv文件读取速度更快,更加便捷且高效
Excel文件相对来说处理复杂程度更高
Excel数据读取使用步骤:
安装第三库
指定版本安装
pip install xlrd==1.2.0
读取数据处理参数化的标准:
# Excel数据读取和使用
def get_excel_data():xls = xlrd.open_workbook(r"D:\pythonProject54\实参数据内容.xlsx")# 获取表格中的工作簿sheet1 = xls.sheet_by_index(0)# 获取所有的数据列总数# print(sheet1.ncols) # 2## # 获取所有的数据行总数# print(sheet1.nrows) # 7# 获取每一行数据list1 = []for i in range(sheet1.nrows):# print(sheet1.row_values(i))list1.append(sheet1.row_values(i))else:# print(list1)return list1
# print(get_excel_data())
数据的使用:
@pytest.mark.parametrize(["username2", "password2"], get_excel_data())
def test_d(username2, password2):print(f"输入用户名:{username2}")print(f"输入密码:{password2}")
4)Json文件数据读取
json数据格式特点:
轻量级
简洁清晰
传输的效率特别高
使用步骤方式:
导入json模块
将json数据格式转化为Python的数据类型
将Python的数据类型格式转化为json格式
# json数据格式处理
json_str = '''
[{"name":"张三","sex":"男","age":18},{"name":"李四","sex":"女","age":20},{"name":"王
五","sex":"女","age":16}]
'''
# python中的字符串
print(type(json_str))# 转化为json数据格式
json_str2 = json.loads(json_str)
# print(json_str2)
# print(type(json_str2))
list1 = []
for i in json_str2:list1.append(i["name"])list1.append(i["sex"])list1.append(i["age"])
else:print(list1)
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
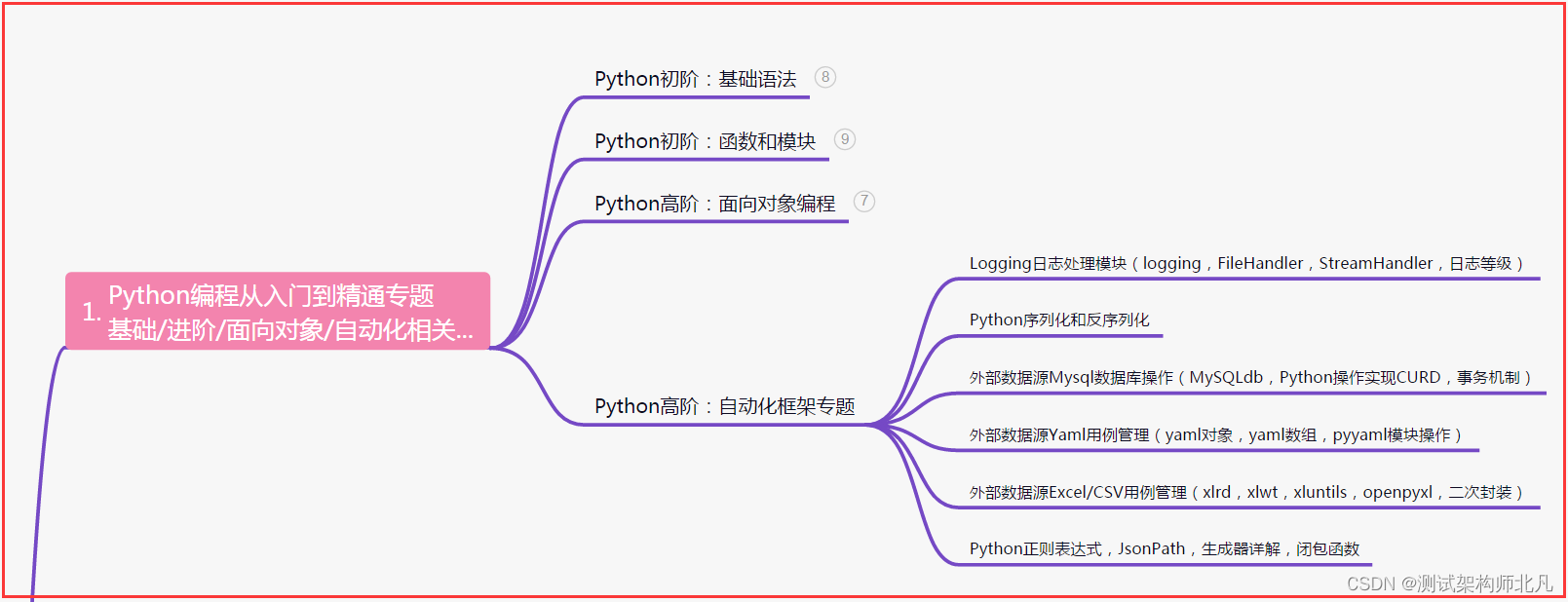
二、接口自动化项目实战
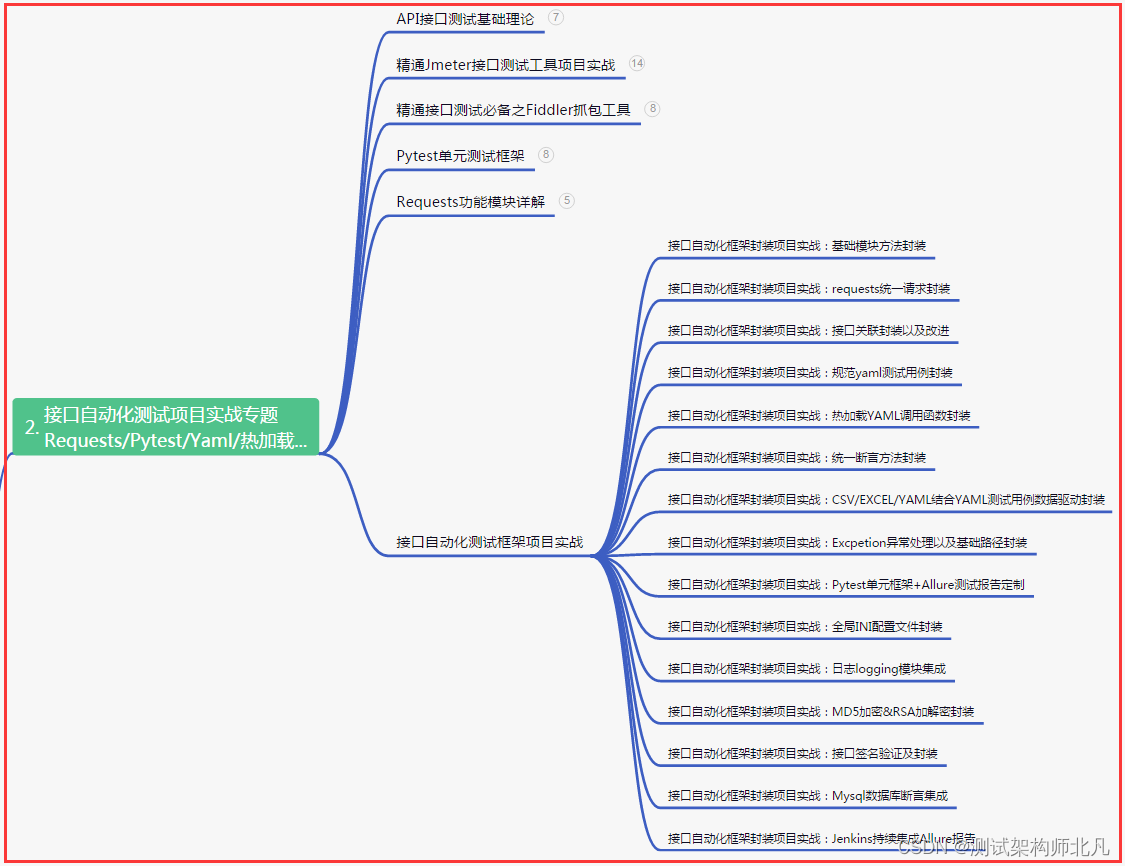
三、Web自动化项目实战
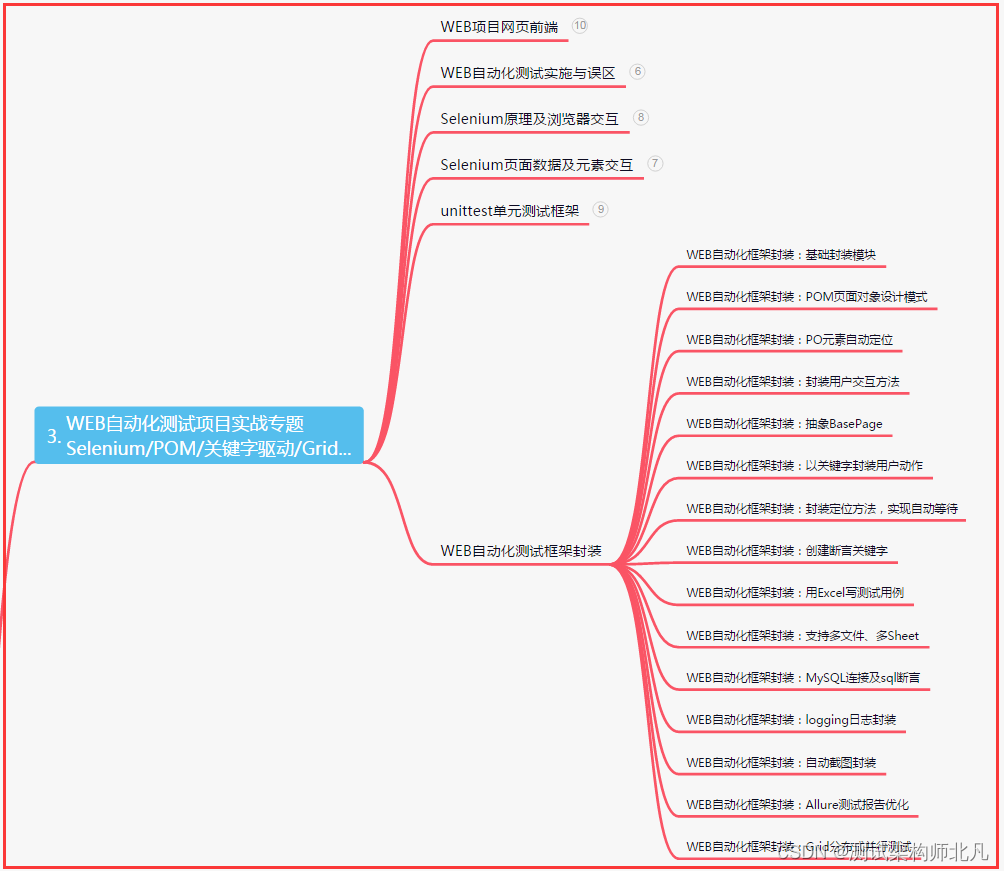
四、App自动化项目实战
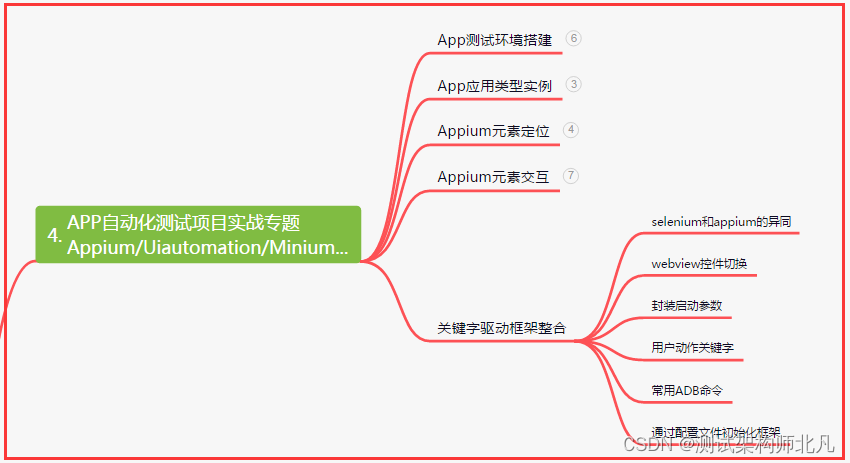
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
执着的追求是成功的前提,无畏的努力是梦想的基石。不论遇到多少困难,都要坚持奋斗,因为只有拼搏过后,我们才能品味到胜利的甜蜜与辉煌。
奋斗不止是一种选择,更是一种责任,因为每一份努力都将成就未来的自己,让我们坚定信念,勇往直前,创造属于自己的精彩人生。
不论起点如何,只要心怀梦想,脚踏实地,努力奋斗,我们都能迸发出无限的力量,创造属于自己的辉煌。相信自己,超越极限,成就不凡。
这篇关于全网最细,Web自动化测试-数据驱动测试(超强整理)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






