本文主要是介绍【并发设计模式】聊聊 基于Copy-on-Write模式下的CopyOnWriteArrayList,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在并发编程领域,其实除了使用上一篇中的属性不可变。还有一种方式那就是针对读多写少的场景下。我们可以读不加锁,只针对于写操作进行加锁。本质上就是读写复制。读的直接读取,写的使用写一份数据的拷贝数据,然后进行写入。在将新的数据指到原来的引用上。Java中的CopyOnWriteArrayList、CopyOnWriteArraySet 都是按照COW,写时复制实现的。
public E set(int index, E element) {// 加锁final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();E oldValue = get(elements, index);if (oldValue != element) {int len = elements.length;//复制一个数组Object[] newElements = Arrays.copyOf(elements, len);newElements[index] = element;setArray(newElements);} else {// Not quite a no-op; ensures volatile write semanticssetArray(elements);}return oldValue;} finally {// 解锁lock.unlock();}}
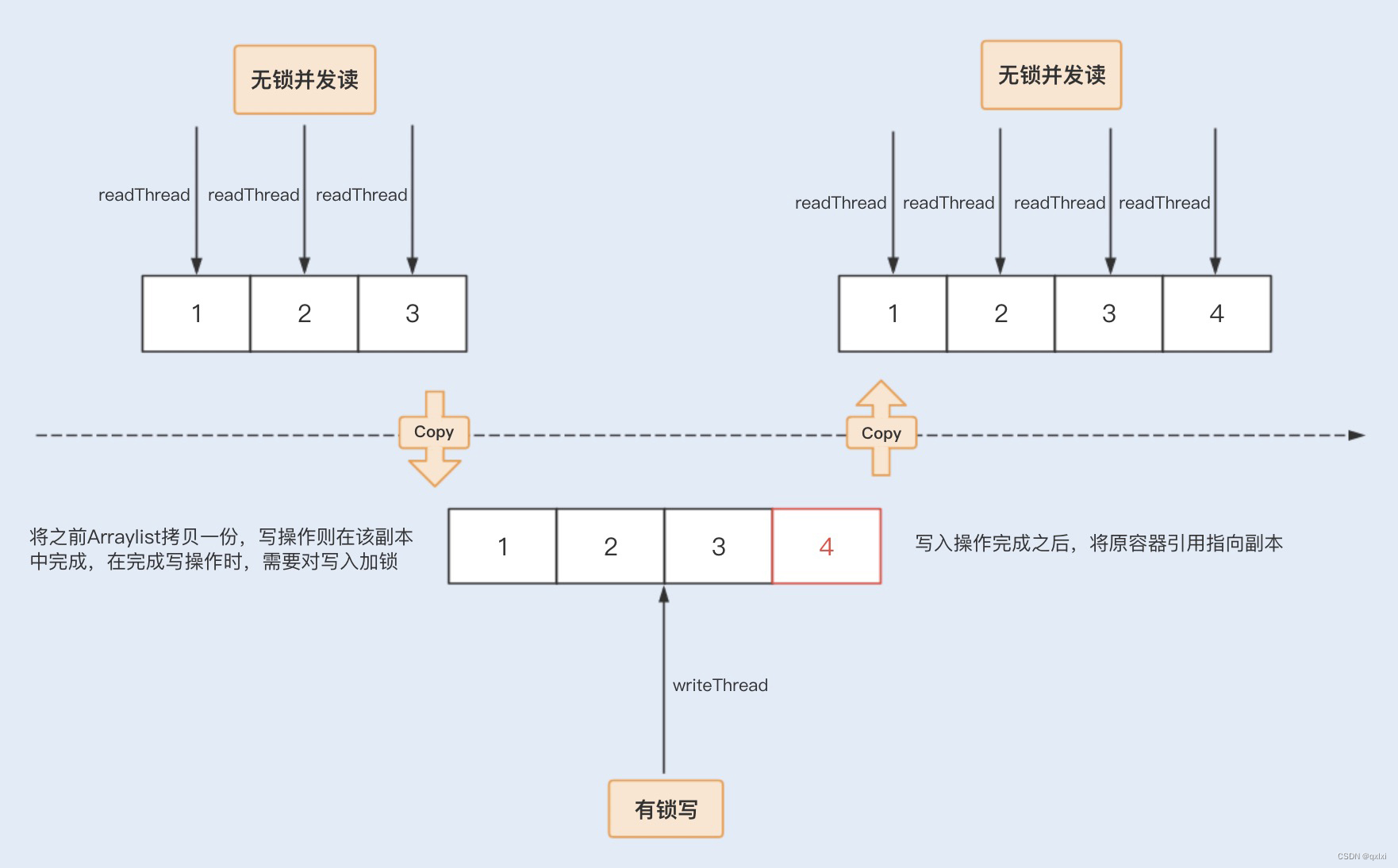
Copy On Write模式
那么COW在别的领域又没有对应的应用,
其实在类Linux中,操作系统创建进程的API是fork() , 传统的fork() 会创建一个父进程的完整副本,这样暂用的地址空间就比较大,并且很耗时。linux更加聪明,那就是fork()子进程的时候,不复制整个进程的地址空间,而是让父子进程共享同一个地址空间,只用在父进程或者子进程需要写入的是才会复制地址空间,父子空间在进行隔离。
最经典的领域其实还是函数式编程领域中,通过将数据拷贝一份进行处理,然后返回结果。
COW模式的缺点是可能对于空间上比较浪费的,毕竟需要使用两倍以上的空间,是一种读多写少场景下使用。空间换时间的一种取舍。
实际应用
在实际的RPC中,客户端都是按照路由表进行查询对应服务的列表,比如A服务对应三台实例,就会将请求分发给对应的服务,按照一定的负载均衡策略。而这类进行一般来说其实都是读多写少。处分出现系统故障,恢复服务下线才会出现问题。
我们按照Map.key为服务名,value使用CopyOnWriteArraySet保存。
public class RouterTables {private static HashMap<String,CopyOnWriteArraySet<Router>> cr = new HashMap<>();static {CopyOnWriteArraySet<Router> userApiRouters = new CopyOnWriteArraySet<>();userApiRouters.add(new Router("192.1.1.1","8080","online"));userApiRouters.add(new Router("192.1.1.2","8080","online"));userApiRouters.add(new Router("192.1.1.3","8080","faild"));CopyOnWriteArraySet<Router> accountApiRouters = new CopyOnWriteArraySet<>();accountApiRouters.add(new Router("192.1.1.1","8080","online"));accountApiRouters.add(new Router("192.1.1.2","8080","online"));accountApiRouters.add(new Router("192.1.1.3","8080","faild"));cr.put("api.user",userApiRouters);cr.put("api.account",accountApiRouters);}public static void addRouter(String apiServiceName,String ip,String port,String serverStatus) {if (!cr.containsKey(apiServiceName)) {CopyOnWriteArraySet<Router> accountApiRouters = new CopyOnWriteArraySet<>();accountApiRouters.add(new Router(ip,port,serverStatus));cr.put(apiServiceName,accountApiRouters);} else {CopyOnWriteArraySet<Router> routers = cr.get(apiServiceName);if (routers.contains(new Router(ip,port,serverStatus))) {return;} else {routers.add(new Router(ip,port,serverStatus));}}}public static Map<String,CopyOnWriteArraySet<Router>> findRouterInfoByApiName (String apiServiceName) {return (Map<String, CopyOnWriteArraySet<Router>>) cr.get(apiServiceName);}public static void deleteRouterInfoByApiName (String apiServiceName) {if (cr.containsKey(apiServiceName)) {cr.remove(apiServiceName);}}public static void prinltnAllInfo() {cr.forEach((s, routers) -> System.out.println(s +"\t"+ routers));}}具体效果就是如下:
api.order [Router{ip='192.1.1.1', port='8080', isOnline='online'}]
api.account [Router{ip='192.1.1.1', port='8080', isOnline='online'}, Router{ip='192.1.1.2', port='8080', isOnline='online'}, Router{ip='192.1.1.3', port='8080', isOnline='faild'}]总结
我们知道ArrayList是并发不安全的容器,如果需要在并发中使用数组集合,并且是读多写少的场景下,就非常推荐使用CopyOnWriteArrayList.

这篇关于【并发设计模式】聊聊 基于Copy-on-Write模式下的CopyOnWriteArrayList的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





