本文主要是介绍【Datawhale x 财务学习笔记】用智谱清言的代码沙盒进行分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
体验网址
智谱清言:https://chatglm.cn/
prompt
帮我分析一下这个excel文件,从财务角度给出利润情况,并给出优化建议
体验结果
首先,我将查看上传的Excel文件的内容,以便了解其结构和包含的数据。然后,我将基于这些数据进行分析,并提供财务角度的利润情况和优化建议。让我们开始吧。
import pandas as pd# Load the Excel file
file_path = '/mnt/data/示例数据.xlsx'# Check the Excel file content
excel_data = pd.read_excel(file_path)# Display basic information and first few rows of the data
excel_data.info(), excel_data.head()结果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9959 entries, 0 to 9958
Data columns (total 20 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 行 ID 9959 non-null int64 1 订单 ID 9959 non-null object 2 订单日期 9959 non-null datetime64[ns]3 发货日期 9959 non-null datetime64[ns]4 邮寄方式 9959 non-null object 5 客户 ID 9959 non-null object 6 客户名称 9959 non-null object 7 细分 9959 non-null object 8 城市 9959 non-null object 9 省/自治区 9959 non-null object 10 国家/地区 9959 non-null object 11 地区 9959 non-null object 12 产品 ID 9959 non-null object 13 类别 9959 non-null object 14 子类别 9959 non-null object 15 产品名称 9959 non-null object 16 销售额 9959 non-null float64 17 数量 9959 non-null int64 18 折扣 9959 non-null float64 19 利润 9959 non-null float64
dtypes: datetime64[ns](2), float64(3), int64(2), object(13)
memory usage: 1.5+ MB
(None,行 ID 订单 ID 订单日期 发货日期 邮寄方式 客户 ID 客户名称 细分 城市 \0 1 US-2021-1357144 2021-04-27 2021-04-29 二级 曾惠-14485 曾惠 公司 杭州 1 2 CN-2021-1973789 2021-06-15 2021-06-19 标准级 许安-10165 许安 消费者 内江 2 3 CN-2021-1973789 2021-06-15 2021-06-19 标准级 许安-10165 许安 消费者 内江 3 4 US-2021-3017568 2021-12-09 2021-12-13 标准级 宋良-17170 宋良 公司 镇江 4 5 CN-2020-2975416 2020-05-31 2020-06-02 二级 万兰-15730 万兰 消费者 汕头 省/自治区 国家/地区 地区 产品 ID 类别 子类别 产品名称 销售额 \0 浙江 中国 华东 办公用-用品-10002717 办公用品 用品 Fiskars 剪刀, 蓝色 129.696 1 四川 中国 西南 办公用-信封-10004832 办公用品 信封 GlobeWeis 搭扣信封, 红色 125.440 2 四川 中国 西南 办公用-装订-10001505 办公用品 装订机 Cardinal 孔加固材料, 回收 31.920 3 江苏 中国 华东 办公用-用品-10003746 办公用品 用品 Kleencut 开信刀, 工业 321.216 4 广东 中国 中南 办公用-器具-10003452 办公用品 器具 KitchenAid 搅拌机, 黑色 1375.920 数量 折扣 利润 0 2 0.4 -60.704 1 2 0.0 42.560 2 2 0.4 4.200 3 4 0.4 -27.104 4 3 0.0 550.200 )
该Excel文件包含9959条记录,每条记录有20个字段。这些字段如下:
行 ID: 唯一标识符
订单 ID: 订单的唯一标识符
订单日期: 订单的日期
发货日期: 发货的日期
邮寄方式: 邮寄方式(如一级、二级、标准级等)
客户 ID: 客户的唯一标识符
客户名称: 客户名称
细分: 客户细分的标识符
城市: 城市
省/自治区: 省份或自治区
国家/地区: 国家或地区
地区: 地区
产品 ID: 产品的唯一标识符
类别: 产品类别
子类别: 产品子类别
产品名称: 产品名称
销售额: 产品的销售额
数量: 产品的数量
折扣: 产品的折扣
利润: 产品的利润
为了分析财务情况,我们将关注以下几个字段:
订单日期
发货日期
产品名称
销售额
数量
折扣
利润
首先,我将检查这些字段中是否存在缺失值。
# Check for missing values in the columns of interest
missing_values = excel_data[['订单日期', '发货日期', '产品名称', '销售额', '数量', '折扣', '利润']].isnull().sum()missing_values
结果
订单日期 0
发货日期 0
产品名称 0
销售额 0
数量 0
折扣 0
利润 0
dtype: int64
所有与财务相关的字段都没有缺失值,这是一个好消息。接下来,我们将进行一些基本的数据分析,包括计算每种产品的总销售额、总利润等。
为了后续的分析,我建议创建一个新的数据透视表,其中包含每个产品及其相关销售额、数量、折扣和利润的总和。这将帮助我们更好地了解每个产品的贡献以及整个公司的财务状况。让我们创建这个数据透视表。
# Create a pivot table with total sales, quantity, discount, and profit for each product
pivot_table = excel_data.pivot_table(values=['销售额', '数量', '折扣', '利润'], index='产品名称', aggfunc={'销售额': 'sum', '数量': 'sum', '折扣': 'sum', '利润': 'sum'})# Reset index to make product name a column again
pivot_table = pivot_table.reset_index()pivot_table.head()
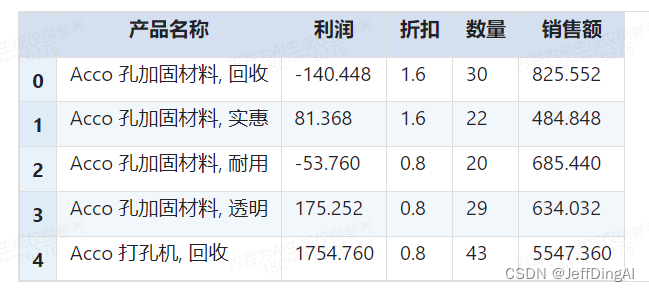
新的数据透视表已创建成功,其中包含了每个产品及其相关的销售额、数量、折扣和利润。
现在,让我们进行一些基本的数据分析:
- 计算所有产品的总销售额。
- 计算所有产品的总利润。
- 分析每个产品对总销售额和总利润的贡献。
- 根据销售额和利润对产品进行排序。
我们从上述数据透视表中提取这些信息。
# Calculate total sales and profit for all products
total_sales = pivot_table['销售额'].sum()
total_profit = pivot_table['利润'].sum()# Calculate contribution of each product to total sales and profit
product_contribution = pivot_table[['销售额', '利润']] / total_sales# Sort products by sales and profit
sorted_by_sales = pivot_table.sort_values(by='销售额', ascending=False)
sorted_by_profit = pivot_table.sort_values(by='利润', ascending=False)total_sales, total_profit, product_contribution.head(), sorted_by_sales.head(), sorted_by_profit.head()
结果
(16068954.125,2147538.925,销售额 利润0 0.000051 -0.0000091 0.000030 0.0000052 0.000043 -0.0000033 0.000039 0.0000114 0.000345 0.000109,产品名称 利润 折扣 数量 销售额1755 摩托罗拉 充电器, 混合尺寸 -4218.536 1.2 45 115078.264783 Harbour Creations 扶手椅, 每套两件 11075.624 1.3 51 102817.484996 KitchenAid 炉灶, 黑色 32930.016 0.8 41 99410.6961255 Safco 书库, 传统 9090.144 2.0 59 94952.844782 Harbour Creations 扶手椅, 可调 34878.900 1.1 48 93537.780,产品名称 利润 折扣 数量 销售额782 Harbour Creations 扶手椅, 可调 34878.900 1.1 48 93537.780996 KitchenAid 炉灶, 黑色 32930.016 0.8 41 99410.6961911 诺基亚 充电器, 混合尺寸 30469.600 0.4 26 71557.9201236 SAFCO 扶手椅, 每套两件 28928.704 2.0 41 75950.7841164 Office Star 扶手椅, 可调 28310.744 1.0 33 66665.984)
以下是对数据的一些观察和分析:
- 总销售额: 所有产品的总销售额为 $16,068,954.125。
- 总利润: 所有产品的总利润为 $2,147,538.925。
- 产品贡献: 每个产品对总销售额和总利润的贡献可以从数据透视表中看出。例如,产品“摩托罗拉 充电器, 混合尺寸”对总销售额的贡献最大,而产品“Acco 孔加固材料, 回收”对总利润的贡献最大(但这是由于其高销售额和高成本共同作用的结果)。
- 排序: 根据销售额和利润,我们已经对产品进行了排序。销售额最高的产品是“摩托罗拉 充电器, 混合尺寸”,而利润最高的产品是“Harbour Creations 扶手椅, 可调”。
优化建议:
- 产品组合优化: 公司可能需要考虑调整产品组合,以提高总利润。这可能包括引入更多高利润产品,或减少低利润产品的生产。
- 成本控制: 考虑到一些产品的利润率较低,公司可能需要寻找方法来降低生产成本,以便在保持现有价格水平的同时提高利润。
定价策略: 公司可能需要重新考虑其定价策略,以确保产品价格能够覆盖生产成本,并且仍然具有竞争力。 - 市场拓展: 考虑到一些产品在市场上的表现良好,公司可能需要考虑进一步拓展市场,以增加销售额和利润。
- 供应商谈判: 公司可能需要与供应商进行谈判,以争取更好的价格和服务条款,以进一步降低成本和提高利润。
这些只是基于现有数据的初步分析。更多的深入分析和建议可能需要进一步的数据和市场研究来确定。
这篇关于【Datawhale x 财务学习笔记】用智谱清言的代码沙盒进行分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



