本文主要是介绍caffe训练siamese网络(行人数据集),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考博客:https://blog.csdn.net/gybheroin/article/details/54133556#commentsedit
环境:windows10 x64 ,caffe, cuda 10.1,cudnn 7.5
数据集:行人数据集
文件夹目录结构:
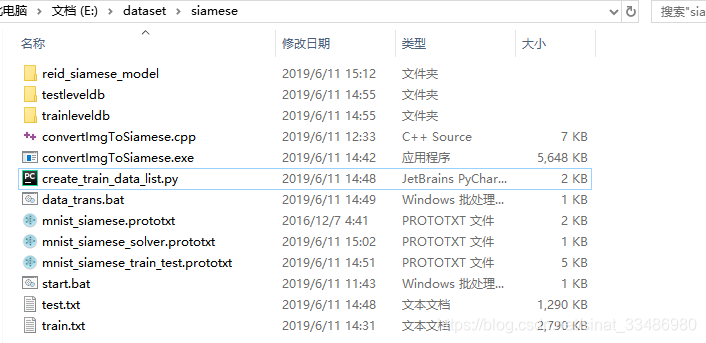
----------------------------------数据准备-------------------------------------
有两种准备数据的方法:
方法一:
按照上面的博客一步步做,自己写了个脚本处理图像,生成train.txt和test.txt,脚本如下:create_train_data_list.py
import osimport random
import glob
path="E:/dataset/Market-1501-v15.09.15/bounding_box_test" #测试图片路径images=glob.glob(path+"/*.jpg")
print (len(images))ft = open("./test.txt", 'w+') #训练时修改成train.txt#-----------------下面为正样本--------------------------names=[]
for image in images:name = (image.split("\\")[-1]).split("_")[0]names.append(name)
names=set(names) #所有行人的标号,不重复for name in names:print (name)sameImgs=[image for image in images if name==(image.split("\\")[-1]).split("_")[0]] #同一个人的图片路径集合for times in range(10): #随机选取10对同一个人的图片i = random.randint(0, len(sameImgs)-1)j = random.randint(0, len(sameImgs)-1)if i == j:continueelse:ft.write(sameImgs[i]+" "+sameImgs[j]+"\n")#-----------------下面为负样本--------------------------for iter in range(2000): #随机选取2000对不同的人i=random.randint(0, len(images)-1)j=random.randint(0, len(images)-1)if i==j:continueelse:iname = (images[i].split("\\")[-1]).split("_")[0]jname = (images[j].split("\\")[-1]).split("_")[0]if iname!=jname:print(iname)ft.write(images[i]+" "+images[j]+"\n")ft.close()有了train.txt和test.txt文件,然后需要根据txt文件,生成leveldb格式文件:
遇到的问题及解决办法:
1、convertImgToSiamese.cpp文件的编译
如图,修改caffe下面的convert_imageset工程,将convert_imageset.vcxproj用notepad打开

查找里面的include这一行,表示要编译那个cpp文件,将其修改为我们自己写的convertImgToSiamese.cpp
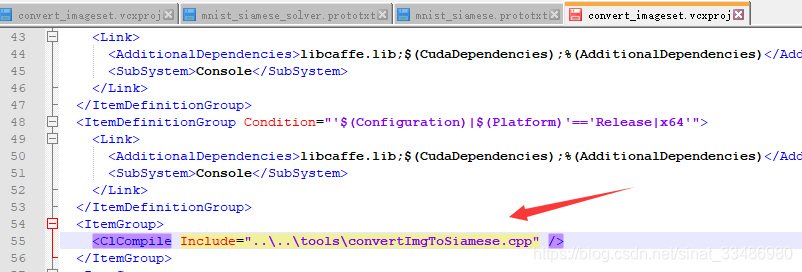
然后打开caffe整个工程文件

打开之后,将convert_imageset工程名改为convertImgToSiamese,然后右键生成

在release文件夹下生成exe文件
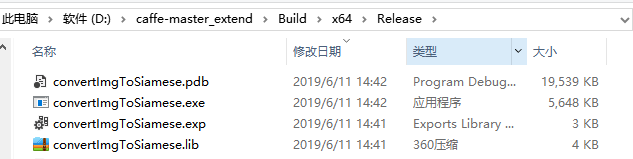
将其复制到我们的文件夹,待后续使用
2、数据转换的命令,导致训练时无法生成sst文件,只生成5个中间文件(大小只有1k,这里的5k是正确生成的)

原因:数据转换的命令参数设置问题

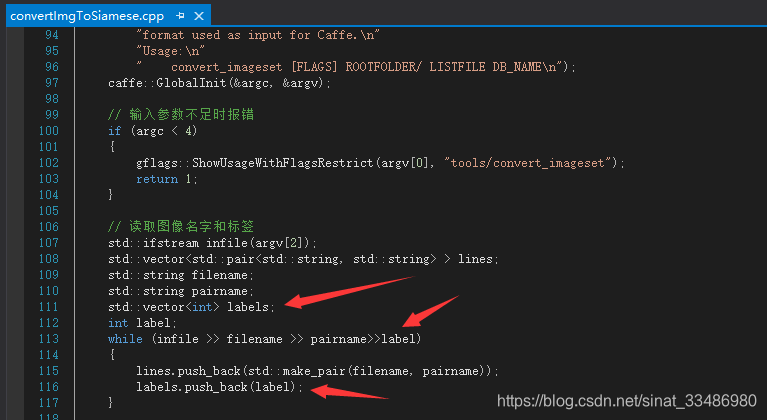
作者这里用的是train/ 作为根目录,在convertImgToSiamese.cpp中,原始图像数据读取的部分,是这样的:
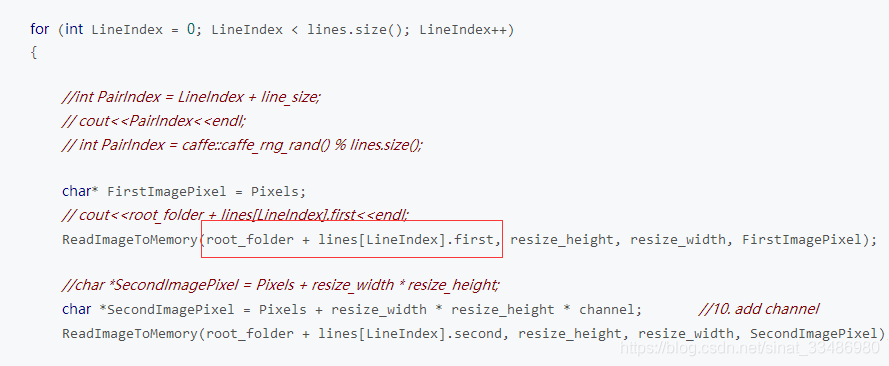
图像路径是根目录+一行中的图片相对路径,而我是这样的:

我的图片路径是完整的绝对路径,所以,我修改了cpp中的这部分代码,直接用txt中读取出来的路径作为图片的路径。

重新编译生成convertImgToSiamese.exe文件,写一个数据转换的脚本:

就可以看到了数据加载到datum中了:
最终正确生成的leveldb文件是这样的:

除了5个中间文件,还会生成最重要的sst文件,生成sst文件表示转换成功。
方法二(改进版)
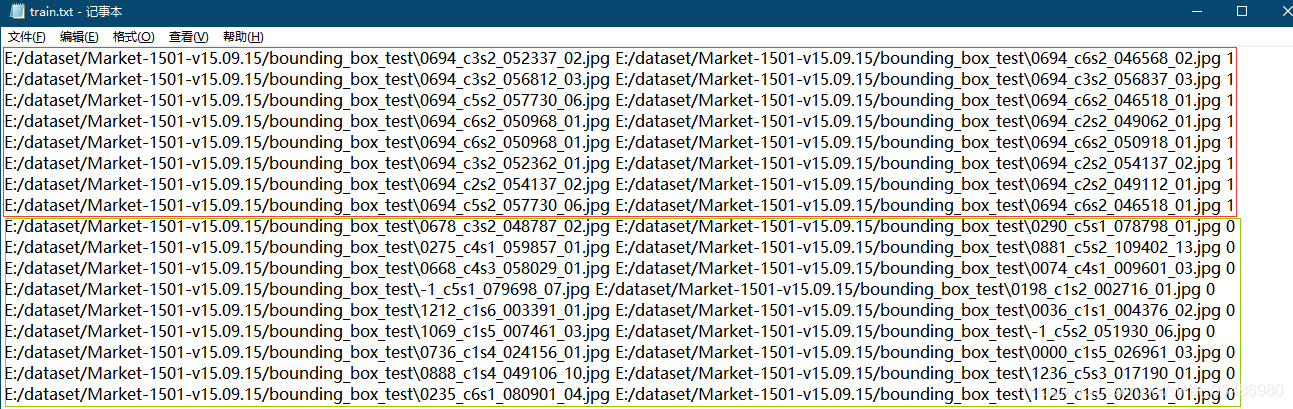
这个方法是后来我看别人基于第一种方法改进的, 把标签也放到了每行的最后, 这样通用性更强一些, 不用在代码里去改true和false的范围,要不然每换一次数据集就要重新生成一次convertImgToSiamese.exe文件。改进后的生成train.txt和test.txt的脚本文件为:

红色框标出的就是修改过的,在每行末尾加上1或0。重新生成的train.txt为:
然后修改convertImgToSiamese.cpp文件:
直接从文件的每一行读取成对的文件名以及最后的label。

这样就可以直接将每一行中的label读取出来,加入到datum中。不用设置正例的数目来判断label,这样就算是后面增加或者减少了正负例的数量,也不用重新编译convertImgToSiamese.cpp文件了。
--------*******************************************************************************************************************************-------
如果想将图像对和label随机shuffle一下,则要做如下修改:
添加头文件,利用系统时钟时间生成随机数种子。
![]()

然后就可以看到,在将随机打乱的数据放入datum时,label也跟着打乱了:

----------------------------------网络结构-------------------------------------
有三种选择:

第一种是将一对输入数据,分别送入两个分支(一边一个数据),这两个分支结构完全一样(这就是孪生的由来),权重共享,然后使用对比损失
第二种是只分开一部分,在后面将两个分支进行合并
第三种是直接将一对输入数据整合成多通道,比如3通道到的RGB图像,两张堆叠在一起,构成一个6通道的图像,然后将6通道的图像输入一个网络,最后使用softmax得到分类结果。
我开始用的是caffe官网提供的训练mnist的siamese网络结构,其实就是第一种两个分支的结构,如下图所示

我在这个基础上做了简单的修改,变得复杂了点:

------------------------------------训练--------------------------------------
接下来可以训练了:

然后训练的solver.prototxt为:
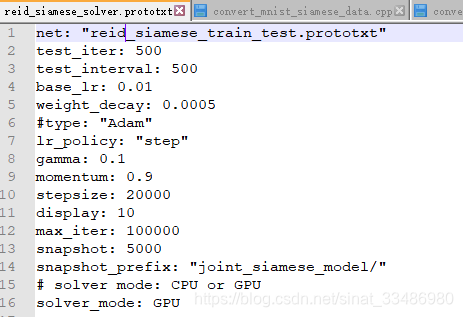
但是训练时候的loss特别低,一直为0.00几这种,后面想想,可能是由于做数据的时候没有shuffle,因为不shuffle的话,datum中的数据都是所有正例放在一起,后面是所有负例,在读取一批进行训练时,基本整个一批都是同类数据,因此loss基本接近于0。然后我使用了方法二(改进后)重新生成了训练数据,结果是loss变成了从一开始loss0.12-0.15左右一直波动,训练很多轮还是这样,我怀疑是对比损失 contrastive loss function的问题。
所以我换成了第三种网络结构(单一网络+softmax):

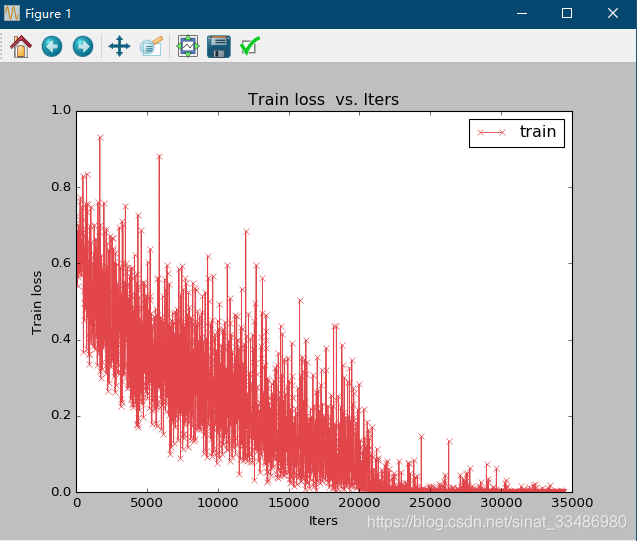
这时候使用方法二(改进后)重新生成的训练数据训练。结果就正常了,将训练结果可视化如图,训练loss的变化
这篇关于caffe训练siamese网络(行人数据集)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




