本文主要是介绍postgresql vacuum流程分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
VACUUM是postgresql MVCC机制不可分割的组成部分。
postgresql在管理同一个元组的多个版本时,采取在堆表页面上从老版本到新版本放置元组的方法,每个元组都记录了xmax和xmin用于判断其可见性。这样的好处是(1)在索引键没有更新时,btree始终指向最老的元组,更新非索引键的数据无需更新btree中的指针(2)回滚的事务时无需专门进行undo(对比MySQL有专门的回滚段,如果发生了事务回滚时需要从回滚段中把上个版本的数据还原出来的)。但是这也带来了垃圾元组(即对任何事务都不可见的元组)的回收开销,以释放堆表页面上的控件。这一回收动作正是由VACUUM执行的。
在postgresql中,当使用delete删除一行数据后,或者使用update更新一行数据后(未更新主键),老元组物理上并没有删除,只是被标记了xmax。需要通过VACUUM来完成物理上的删除。
VACUUM的几种不同形式
用户可见的vacuum命令有两个,一个是vacuum,另一个是vacuum full。其中vacuum full实质上是把表进行了重建,或者说重新聚簇,在vacuum full的过程中会占有表的8级锁,不允许在vacuum full的时候对表进行其它操作。与之不同的是,vacuum时只会持有表的4级锁,在vacuum的同时还可以继续对表进行查询、删除和更新。
本篇文章主要分析vacuum的流程,vacuum full的流程后面有机会再分析。
VACUUM的总体流程
用户下发VACUUM命令后,postgresql会调用table_relation_vacuum()函数来进行处理,table_relation_vacuum是个抽象方法,对于最常见的堆表来说,其对应的具体方法时heap_vacuum_rel。总的来说,heap_vacuum_rel包括三步:
(1)基于一个快照扫描堆表,确定哪些元组已经死亡,可以被删除
(2)基于上述死亡的元组扫描索引,并删除(或更新?)索引中的对应条目,如果发现某个索引页面中的内容全部被删除,则尝试(哪些场景下无法释放)释放该页面,在释放btree索引页面时,需要同步修改parent页面
(3)在删除完索引后,再删除堆表上已死亡的元组
之所以要先删除索引再删除堆表,是因为相反的顺序可能导致索引指向的元组无效(被删除了),会导致无法恢复的错误。
VACUUM流程图
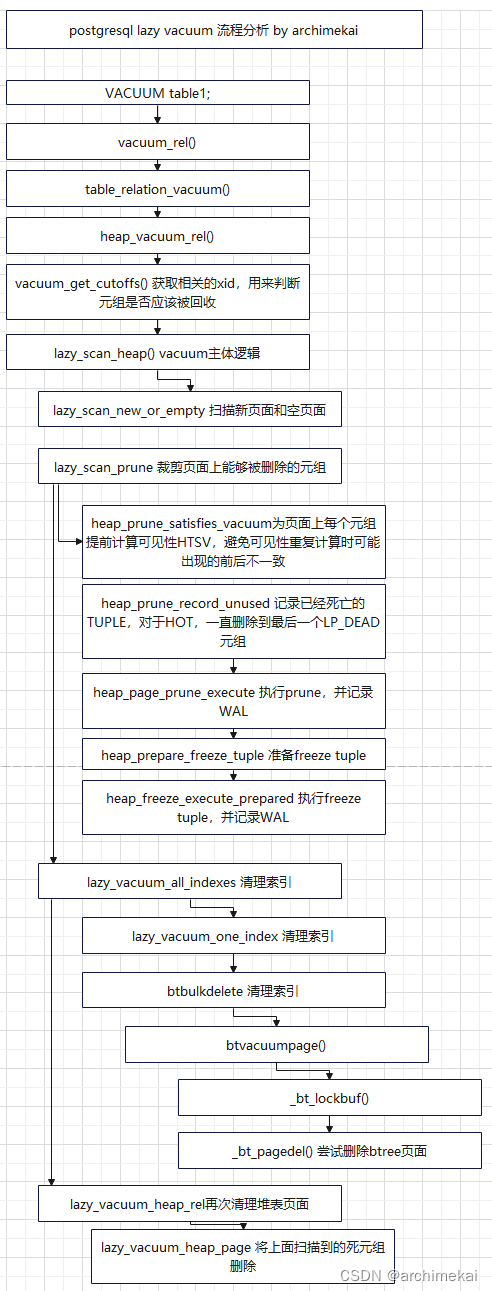
备注
pg中btree页面的几种状态
// https://github.com/postgres/postgres/blob/c9c0589fda0edc46b8f5e7362b04636c0c4f0723/src/include/access/nbtree.h
/* Bits defined in btpo_flags */
#define BTP_LEAF (1 << 0) /* leaf page, i.e. not internal page */
#define BTP_ROOT (1 << 1) /* root page (has no parent) */
#define BTP_DELETED (1 << 2) /* page has been deleted from tree */
#define BTP_META (1 << 3) /* meta-page */
#define BTP_HALF_DEAD (1 << 4) /* empty, but still in tree (什么条件下是half dead?) */
#define BTP_SPLIT_END (1 << 5) /* rightmost page of split group */
#define BTP_HAS_GARBAGE (1 << 6) /* page has LP_DEAD tuples (deprecated) */
#define BTP_INCOMPLETE_SPLIT (1 << 7) /* right sibling's downlink is missing */
#define BTP_HAS_FULLXID (1 << 8) /* contains BTDeletedPageData */
pg中堆表元组的几种状态
// https://github.com/postgres/postgres/blob/c8e1ba736b2b9e8c98d37a5b77c4ed31baf94147/src/include/storage/itemid.h
/** lp_flags has these possible states. An UNUSED line pointer is available* for immediate re-use, the other states are not.*/
#define LP_UNUSED 0 /* unused (should always have lp_len=0) */
#define LP_NORMAL 1 /* used (should always have lp_len>0) */
#define LP_REDIRECT 2 /* HOT redirect (should have lp_len=0) */
#define LP_DEAD 3 /* dead, may or may not have storage */
参考资料
openGauss源码解析
这篇关于postgresql vacuum流程分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





