本文主要是介绍【三】【C语言\动态规划】珠宝的最高价值、下降路径最小和、最小路径和,三道题目深度解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
动态规划
动态规划就像是解决问题的一种策略,它可以帮助我们更高效地找到问题的解决方案。这个策略的核心思想就是将问题分解为一系列的小问题,并将每个小问题的解保存起来。这样,当我们需要解决原始问题的时候,我们就可以直接利用已经计算好的小问题的解,而不需要重复计算。
动态规划与数学归纳法思想上十分相似。
数学归纳法:
-
基础步骤(base case):首先证明命题在最小的基础情况下成立。通常这是一个较简单的情况,可以直接验证命题是否成立。
-
归纳步骤(inductive step):假设命题在某个情况下成立,然后证明在下一个情况下也成立。这个证明可以通过推理推断出结论或使用一些已知的规律来得到。
通过反复迭代归纳步骤,我们可以推导出命题在所有情况下成立的结论。
动态规划:
-
状态表示:
-
状态转移方程:
-
初始化:
-
填表顺序:
-
返回值:
数学归纳法的基础步骤相当于动态规划中初始化步骤。
数学归纳法的归纳步骤相当于动态规划中推导状态转移方程。
动态规划的思想和数学归纳法思想类似。
在动态规划中,首先得到状态在最小的基础情况下的值,然后通过状态转移方程,得到下一个状态的值,反复迭代,最终得到我们期望的状态下的值。
接下来我们通过三道例题,深入理解动态规划思想,以及实现动态规划的具体步骤。
LCR 166. 珠宝的最高价值

题目解析

状态表示
我们可以定义dp[i][j]表示,从(0,0)位置出发,到达(i,j)位置,在所有的可能路径中,所能获得的最大价值数。
状态转移方程
要到达(i,j)位置,要么从(i,j-1)位置往右走一步,要么从(i-1,j)位置往下走一步。根据状态表示,dp[i][j]表示从(0,0)位置出发,到达(i,j)位置,在所有的可能路径中,所能获得的最大价值数。dp[i][j-1]表示从(0,0)位置出发,到达(i,j-1)位置,在所有的可能路径中,所能获得的最大价值数。dp[i-1][j]表示从(0,0)位置出发,到达(i-1,j)位置,在所有的可能路径中,所能获得的最大价值数。
很简单可以得到dp[i][j]=max(dp[i][j-1],dp[i-1][j])+frame[i][j]
在这两种情况下,选择一个更大的价值,再加上自己位置上的价值,就是从(0,0)到达(i,j)位置的最大价值,也就是dp[i][j]
故,状态转移方程为:
dp[i][j]=max(dp[i][j-1],dp[i-1][j])+frame[i][j]
初始化
在填表的过程中,为了不造成越界访问的情况,我们需要对数组中某一些位置进行初始化。根据状态转移方程我们知道,如果要推导出(i,j)位置的状态,我们需要知道(i-1,j)和(i,j-1)位置的状态,所以在数组的第一行和第一列中,如果我们要推导这些状态,就会造成越界访问,所以需要对这些位置上的值进行初始化。
初始化具体操作是根据状态表示定义,依次填写正确的状态。
dp[i][j]表示,从(0,0)位置出发,到达(i,j)位置,在所有的可能路径中,所能获得的最大价值数。
所以第一行中,第一个数填自己的价值,第二个数填前一个数的价值加上自己的价值,以此类推,第一列同理。
我们会发现这样初始化会非常的复杂。
我们能不能把这些位置的计算通过状态转移方程进行推导得出来呢?如果直接进行推导数组一定会造成越界访问的错误,但我们依旧有办法可以把所有状态统一用状态转移方程推导出来,同时也不会造成越界访问的错误。
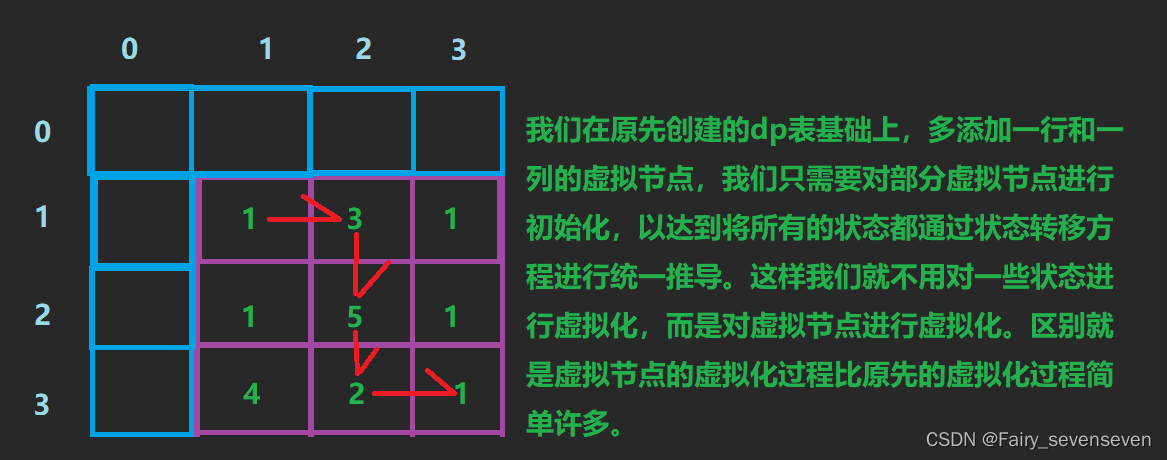
如果我们创建虚拟节点,将所有状态用状态转移方程进行推导,我们只需要初始化虚拟节点就可以了,这样做的好处是,对虚拟节点的初始化过程是十分简便的。
不过创建虚拟节点的操作有几点需要注意。
第一,对虚拟节点的初始化,必须能使所有状态正确推导。
第二,状态表示和状态转移方程需要改变对应关系。
意思是,dp[i][j]对应的位置在frame实际上是[i-1]j-1]位置。需要注意对应关系的改变。
接下来我们对虚拟节点进行初始化。
根据状态转移方程我们知道,(i,j)的状态需要由(i,j-1)(i-1,j)两个位置的状态推导得到,所以我们需要对虚拟节点除(0,0)位置外,每一个值都进行初始化。
因为(1,1)位置需要用到(0,1)(1,0)位置的状态值,其他的位置推导同理。
重新回到状态转移方程,dp[i][j]=max(dp[i][j-1],dp[i-1][j])+frame[i-1][j-1]
对于(1,1)点,dp[1][1]应该是它本身的价值,所以max(dp[i][j-1],dp[i-1[j])的值应该要为零。故把dp[i][j-1]=dp[i-1][j]置零。
对于第一行其他的点,他们的上方位置的价值应该是零,因为到不了哪些位置,所以也置零。
对于第一列同理。(这里说的第一行第一列是对于紫色框框来说的)
所以我们可以统一将dp数组置0,即可。
所以初始化是将dp数组全部置零。
填表顺序
从左到右,从上到下
返回值
返回最后一个值即可,即:dp[row][col]
代码实现
int jewelleryValue(int** frame, int frameSize, int* frameColSize) {int row=frameSize;int col=frameColSize[0];int dp[row+1][col+1];for(int i=0;i<=row;i++){memset(dp[i],0,sizeof(dp[i]));}for(int i=1;i<=row;i++){for(int j=1;j<=col;j++){dp[i][j]=fmax(dp[i-1][j],dp[i][j-1])+frame[i-1][j-1];}}return dp[row][col];
}931. 下降路径最小和
题目解析

状态表示
我们可以定义dp[i][j]表示,从开头某一位置出发,到达(i,j)位置时,下降路径的最小和。
状态转移方程
对于(i,j)位置,需要得到,从开头某一位置出发,到达(i,j)位置时,下降路径的最小和。
我们想一想能不能由其他状态推导出(i,j)位置状态的值。
到达(i,j)位置一共有三种情况,要么从(i-1,j-1)位置往右下走一步,要么从(i-1,j)位置往下走一步,要么从(i-1,j+1)位置往左下走一步。
dp[i-1][j-1]表示从开头某一位置出发,到达(i-1,j-1)位置时,下降路径的最小和。
dp[i-1][j]表示从开头某一位置出发,到达(i-1,j)位置时,下降路径的最小和。
dp[i-1][j+1]表示从开头某一位置出发,到达(i-1,j+1)位置时,下降路径的最小和。
所以很容易得到,dp[i][j]=min(dp[i-1][j-1],dp[i-1][j],dp[i-1][j+1])+matrix[i][j];
故,状态转移方程为:
dp[i][j]=min(dp[i-1][j-1],dp[i-1][j],dp[i-1][j+1])+matrix[i][j];
初始化
根据状态转移方程,我们需要推导(i,j)位置的值,需要运用(i-1,j-1),(i-1,j),(i-1,j+1)的值。
所以我们必须初始化第一行,第一列,和最后一列的数据。
我们发现这样的初始化操作十分的复杂。
我们希望简化这种复杂的操作。
所以我们把这些需要初始化的位置用虚拟节点代替,而原先需要初始化的位置改变为初始化虚拟节点。
我们知道初始化虚拟节点一般都是比较轻松的。
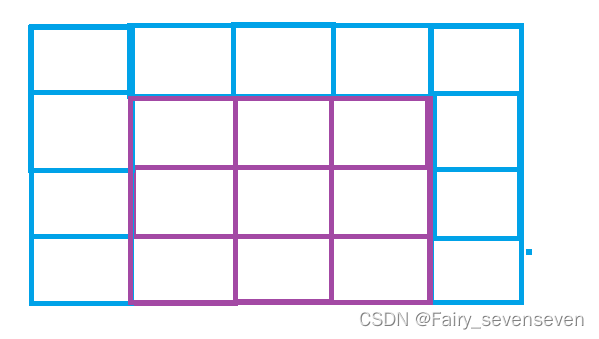
我们选择多添加一行和两列作为虚拟节点。将所有我们需要填写的状态位置都通过状态转移方程推导得到,这样我们就只需要初始化虚拟节点就可以了。
创建虚拟节点有几点注意事项:
第一,虚拟节点的初始化必须保证后续推导过程求值得准确性。
第二,注意下表得映射关系,也就是状态表示和状态转移方程的下标需要偏移。
接下来我们通过实际的含义,初始化虚拟节点里面的值。
关注我们需要填写的状态的第一行,也就是紫色框框圈住的第一行。
对于这些数据,我们需要用到蓝色第一行的数据,由状态转移方程,dp[i][j]=min(dp[i-1][j-1],dp[i-1][j],dp[i-1][j+1])+matrix[i-1][j-1];,实际上紫色的一行填写的数据一个就是matrix[i-1][j-1]
所以min(dp[i-1][j-1],dp[i-1][j],dp[i-1][j+1])值一个要为零。
所以蓝色第一行我们初始化为零。
关注我们需要填写的状态的第一列,也就是紫色第一列。
除第一个元素我们考虑过,其他的元素都需要用到蓝色第一列的数据。
dp[i][j]=min(dp[i-1][j-1],dp[i-1][j],dp[i-1][j+1])+matrix[i-1][j-1];
在三者去最小的时候,我们不能取到dp[i-1][j-1]位置的值,所以这些位置应该初始化无穷大。
最后一列的初始化同理。
所以初始化操作为:
蓝色第一行全部初始化为零,第一列和最后一列初始化为无穷大。
填表顺序
从左往右,从上往下
返回值
我们需要得到从最上面开始出发,到达最下面的路径最小和,所以我们需要访问最后一行的元素,找到他们的最小值返回即可。
代码实现
int minFallingPathSum(int** matrix, int matrixSize, int* matrixColSize) {int row=matrixSize;int col=matrixColSize[0];int dp[row+1][col+2];for(int i=0;i<=row;i++){memset(dp[i],0,sizeof(dp[i]));}for(int i=1;i<=row;i++){dp[i][0]=0x3f3f3f;dp[i][col+1]=0x3f3f3f;}for(int i=1;i<=row;i++){for(int j=1;j<=col;j++){dp[i][j]=fmin(dp[i-1][j-1],fmin(dp[i-1][j],dp[i-1][j+1]))+matrix[i-1][j-1];}}int ret=INT_MAX;for(int i=1;i<=col;i++){ret=fmin(ret,dp[row][i]);}return ret;
}我们首先把所有的数据初始化为零。然后再初始化第一列和最后一列的元素,初始化为无穷大。
这里我们可以用INT_MAX表示,也可以用0x3f3f3f3f表示。
0x3f3f3f3f是一个很有用的数值,它是满足以下两个条件的“最大整数”。
1、整数的两倍不超过 0x7f7f7f7f,即int能表示的最大正整数。
2、整数的每8位(每个字节)都是相同的。
我们在程序设计中经常需要使用 memset(a, val, sizeof a) 初始化一个数组a,该语句把数值 val(0x00~0xFF)填充到数组a 的每个字节上,所以用memset只能赋值出“每8位都相同”的 int。
当需要把一个数组中的数值初始化成正无穷时,为了避免加法算术上溢出或者繁琐的判断,我们经常用 memset(a, 0x3f, sizeof(a)) 给数组赋 0x3f3f3f3f的值来代替。
0x3f3f3f3f通常用于表示无穷大。
64. 最小路径和

题目解析
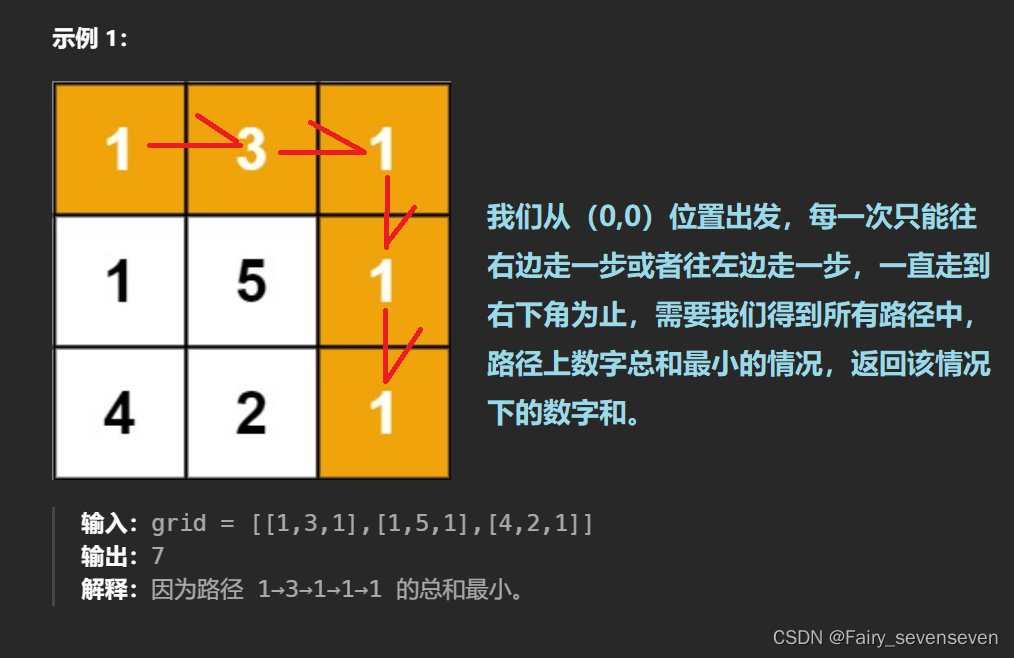
状态表示
我们可以定义,dp[i][j]表示,从(0,0)位置出发,到达(i,j)位置的所有情况下最小路径和。
状态转移方程
我们想一想,(i,j)位置的状态能不能由其他的位置推导得出来?
如果我们要到达(i,j)位置,要么从(i,j-1)位置向右走一步,要么从(i-1,j)位置向下走一步,dp[i][j]表示,从(0,0)位置出发,到达(i,j)位置的所有情况下最小路径和。
dp[i-1][j]表示,从(0,0)位置出发,到达(i-1,j)位置的所有情况下最小路径和。
dp[i][j-1]表示,从(0,0)位置出发,到达(i,j-1)位置的所有情况下最小路径和。
很容易可以得到,dp[i][j]=min(dp[i-1][j],dp[i][j-1])+grid[i][j]
故,状态转移方程为:
dp[i][j]=min(dp[i-1][j],dp[i][j-1])+grid[i][j]
初始化
根据状态转移方程,我们知道,如果要推导出(i,j)位置的状态值,我们需要用到(i,j-1)和(i-1,j)位置的状态值,所以我们需要初始化第一列和第一行的所有数据的值。当然我们也可以添加虚拟节点,使得所有状态值都可以用状态转移方程推导得出,将所有的状态进行统一化,这样我们就不用初始化第一行和第一列的状态,转而初始化虚拟节点的状态就可以了,而初始化虚拟节点的值是比较容易实现的。因为我们要使得原先第一行和第一列的数据可以有前驱使得可以利用状态转移方程推导得出,所以我们需要添加一列和一行。
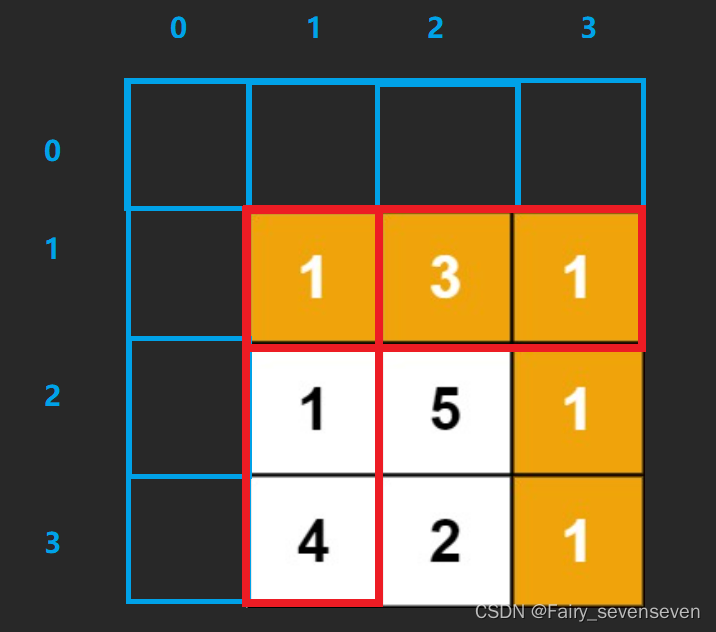
添加虚拟节点有几点注意事项:
第一,初始化虚拟节点的值,必须保证正确性,不能使得后续状态的推导出错。
第二,注意dp数组下标和原数组下标的映射关系,也就是状态表示和状态转移方程的下标映射关系。
我们目光回到红色框框住的一行和一列。
对于这些数据我们需要访问虚拟节点的值,推导出自己的状态值,状态转移方程是,
dp[i][j]=min(dp[i-1][j],dp[i][j-1])+grid[i][j]
对于(1,1)位置的状态,实际上他的值应该是他自己,根据状态转移方程,min(dp[0][1],dp[1][0])的值应该为0
对于行来说,除去第一个数据,其他的状态推导中不能取虚拟节点的值,所以上面虚拟节点的值应该为正无穷。
对于列来说,同理,左边虚拟节点的值也应该为正无穷。
所以我们可以把所有数据都初始化正无穷,dp[0][1]和dp[1][0]位置选一个置0即可。
填表顺序
从左往右,从上往下
返回值
返回dp[row][col]最后一个数据的值。
代码实现
int minPathSum(int** grid, int gridSize, int* gridColSize) {int row=gridSize;int col=gridColSize[0];int dp[row+1][col+1];for(int i=0;i<=row;i++){memset(dp[i],0x3f3f3f3f,sizeof(dp[i]));}dp[0][1]=0;for(int i=1;i<=row;i++){for(int j=1;j<=col;j++){dp[i][j]=fmin(dp[i-1][j],dp[i][j-1])+grid[i-1][j-1];}}return dp[row][col];
}0x3f3f3f3f是一个很有用的数值,它是满足以下两个条件的“最大整数”。
1、整数的两倍不超过 0x7f7f7f7f,即int能表示的最大正整数。
2、整数的每8位(每个字节)都是相同的。
我们在程序设计中经常需要使用 memset(a, val, sizeof a) 初始化一个数组a,该语句把数值 val(0x00~0xFF)填充到数组a 的每个字节上,所以用memset只能赋值出“每8位都相同”的 int。
当需要把一个数组中的数值初始化成正无穷时,为了避免加法算术上溢出或者繁琐的判断,我们经常用 memset(a, 0x3f, sizeof(a)) 给数组赋 0x3f3f3f3f的值来代替。
0x3f3f3f3f通常用于表示无穷大。
结尾
今天我们学习了动态规划的思想,动态规划思想和数学归纳法思想有一些类似,动态规划在模拟数学归纳法的过程,已知一个最简单的基础解,通过得到前项与后项的推导关系,由这个最简单的基础解,我们可以一步一步推导出我们希望得到的那个解,把我们得到的解依次存放在dp数组中,dp数组中对应的状态,就像是数列里面的每一项。最后感谢您阅读我的文章,对于动态规划系列,我会一直更新,如果您觉得内容有帮助,可以点赞加关注,以快速阅读最新文章。
最后,感谢您阅读我的文章,希望这些内容能够对您有所启发和帮助。如果您有任何问题或想要分享您的观点,请随时在评论区留言。
同时,不要忘记订阅我的博客以获取更多有趣的内容。在未来的文章中,我将继续探讨这个话题的不同方面,为您呈现更多深度和见解。
谢谢您的支持,期待与您在下一篇文章中再次相遇!
这篇关于【三】【C语言\动态规划】珠宝的最高价值、下降路径最小和、最小路径和,三道题目深度解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






