本文主要是介绍【踩坑】ShardingJdbc实现自动生成主键时,根据雪花算法生成的主键值存放在别的字段上了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 问题
- 原因
- 实现效果
- 代码
问题
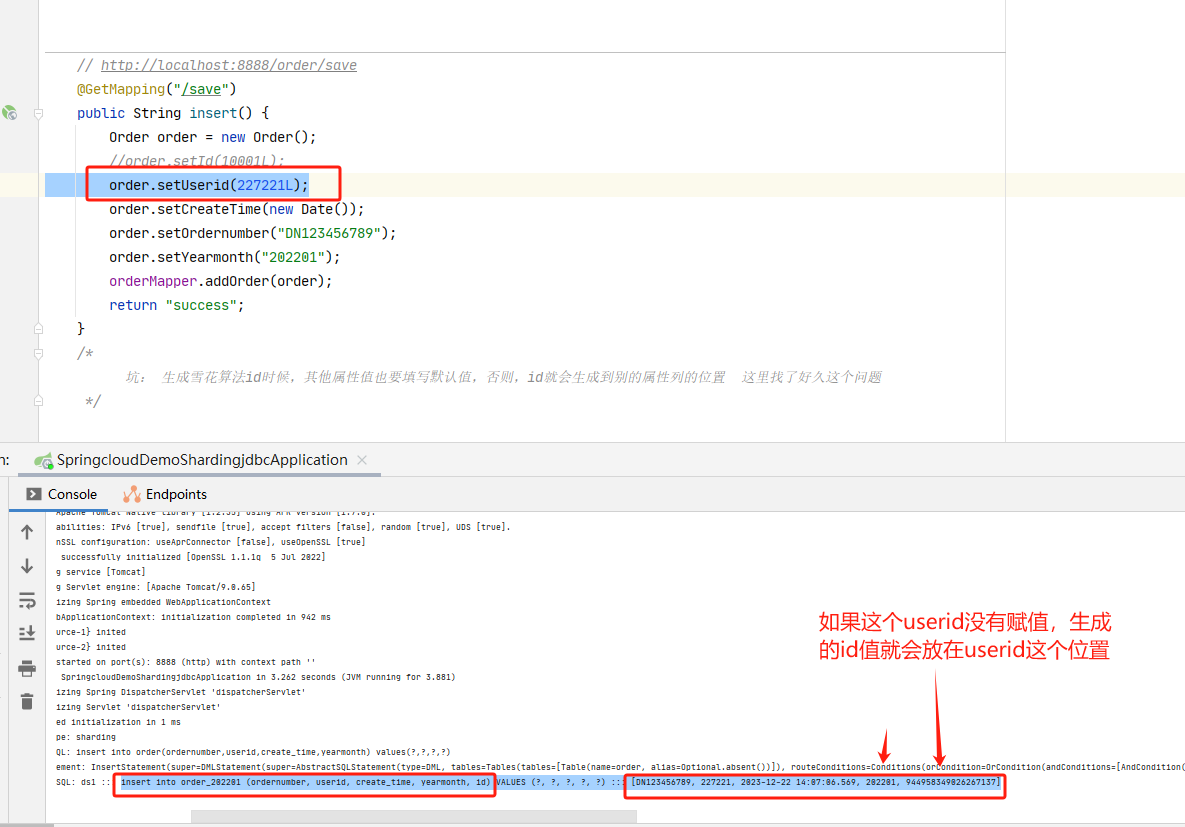
ShardingJdbc 生成雪花算法id主键时,插入到表中的数据显示生成的内容存放在别的字段上

正确的应该是:
原因
生成雪花算法id时候,其他属性值也要填写默认值,否则,id就会生成到别的属性列的位置 这里找了好久这个问题
实现效果


代码
sharding配置:根据年月分表
# 配置默认数据源ds1sharding:# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。default-data-source-name: ds1# 配置分表规则tables:# order 逻辑表名# 订单表按照 年月分表 生成表名 order_202101,order_202102,order_202103,order_202201,order_202202,order_202203order:# 最后一部分 ${ 生成一个从1到3的数字序列,然后将每个数字转换为字符串,并在左边填充0,使其总长度为2 }actual-data-nodes: ds1.order_$->{2021..2022}${(1..3).collect{t ->t.toString().padLeft(2,'0')}}key-generator:type: SNOWFLAKEcolumn: idprops:worker.id: 1max.vibration.offset: 255# Snowflake 算法是一种用于生成分布式系统中唯一 ID 的算法,其中的 worker.id 和 max.vibration.offset 是 Snowflake 算法的两个重要参数。## worker.id 表示工作节点 ID,取值范围为 0~1023。在多台机器上使用 Snowflake 算法生成 ID 时,需要为每台机器分配一个唯一的 worker.id,以避免不同机器生成相同的 ID。如果未指定,则会使用默认值 0。# max.vibration.offset 表示最大时间抖动偏移量,取值范围为 0~4095。由于 Snowflake 算法中使用了时间戳,如果在同一毫秒内生成了多个 ID,就需要对其中部分 ID 进行时间戳上的微调。max.vibration.offset 参数用于指定最大的微调偏移量。如果未指定,则会使用默认值 63。# 因此,在使用 Snowflake 算法作为主键生成策略时,可以通过 props 指定 worker.id 和 max.vibration.offset 参数,以满足不同的业务需求。例如:## 如果您的系统只有一台机器并且不需要很高的并发量,可以将 worker.id 设置为 0,不需要对时间戳进行微调,可以将 max.vibration.offset 设置为较小的值。# 如果您的系统需要支持多台机器和高并发量,可以将 worker.id 设置为不同的值,以避免 ID 重复,并且可以将 max.vibration.offset 设置为较大的值,以允许更多的微调偏移量。# 请注意,worker.id 和 max.vibration.offset 参数的具体取值需要根据实际情况进行调整,以确保生成的 ID 唯一性和正确性。table-strategy:inline:sharding-column: yearmonthalgorithm-expression: order_$->{yearmonth}defaultKeyGenerator:mapper
package com.song.springclouddemoshardingjdbc.mapper;import com.song.springclouddemoshardingjdbc.entity.Order;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.springframework.stereotype.Repository;@Mapper
@Repository
public interface OrderMapper {@Insert("insert into order(ordernumber,userid,create_time,yearmonth) values(#{ordernumber},#{userid},#{createTime},#{yearmonth})")@Options(useGeneratedKeys = true,keyColumn = "id",keyProperty = "id") // 可以不加void addOrder(Order order);}这篇关于【踩坑】ShardingJdbc实现自动生成主键时,根据雪花算法生成的主键值存放在别的字段上了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





