本文主要是介绍手把手教你用Pyecharts库对淘宝数据进行可视化展示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
博学而约取,厚积而薄发。
大家好,我是Python进阶者。
一、前言
大家好,我是Python进阶者。上一篇文章给大家讲到了淘宝数据的预处理和词频处理,没有来得及看的小伙伴,记得去学习了下了,详情戳这里:手把手教你用Pandas库对淘宝原始数据进行数据处理和分词处理。这篇文章紧接着上一篇文章处理得到的数据进行可视化处理,一起来看看吧!
二、可视化
可视化部分,我们采用Pyecharts库来进行完成,这个库作图十分的炫酷,而且可以交互,十分带感,强烈推荐。关于这部分,小编以生成配料图表和生成保质期可视化图表为例来进行展开。
1、生成配料饼图
针对配料数据,我们使用一个饼图去进行展示,这样显得更加高大上一些,直接上代码。
# 生成配料图表
def get_ingredients_html(df):# 词表分词names = df.配料表.apply(jieba.lcut).explode()df1 = names[names.apply(len)>1].value_counts()# 写入分词后的结果with pd.ExcelWriter("淘宝商品配料数据.xlsx") as writer:df1.to_excel(writer, sheet_name="配料")fpath = r'C:\Users\pdcfi\Desktop\淘宝数据分析\淘宝商品配料数据.xlsx'# 读取数据 提取列df1 = pd.read_excel(fpath, header=None, skiprows=1, sheet_name='配料', names=['sx', 'sl'])a = df1['sx'].to_list()[:10]b = df1['sl'].to_list()[:10]from pyecharts.charts import Piefrom pyecharts import options as opts# 绘制可视化图表pie = (Pie().add('', [list(z) for z in zip(a, b)],radius=["20%", "60%"], # 半径长度rosetype="radius" # 扇区圆心角展现数据的百分比,半径展现数据的大小).set_global_opts(title_opts=opts.TitleOpts(title="淘宝商品数据配料统计", subtitle="8.19")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) # 数字项名称和百分比)pie.render('淘宝商品数据配料统计.html')
在Pycharm里边运行代码之后,我们将会得到一个淘宝商品数据配料统计.html文件,双击打开该HTML文件,在浏览器里边可以看到效果图,如下图所示。

是不是感觉一下子就高大上了呢?而且动动鼠标,你还可以进行交互,是动态图来着,十分好玩。
2、生成保质期可视化饼图
针对保质期数据,我们也先使用一个饼图去进行展示,直接上代码,其实你会发现和上面那个配料图表大同小异。
"""生成保质期可视化图表"""
def get_date_html(df):# 词表分词names = df.保质期.apply(jieba.lcut).explode()df1 = names[names.apply(len) > 1].value_counts()# 写入分词后的结果with pd.ExcelWriter("淘宝商品保质期数据.xlsx") as writer:df1.to_excel(writer, sheet_name="保质期")fpath = r'C:\Users\pdcfi\Desktop\淘宝数据分析\淘宝商品保质期数据.xlsx'# 读取数据 提取列df1 = pd.read_excel(fpath, header=None, skiprows=1, names=['bzq', 'rq'])a = df1['bzq'].to_list()[:10]b = df1['rq'].to_list()[:10]from pyecharts.charts import Piefrom pyecharts import options as opts# 绘制可视化图表pie = (Pie().add('', [list(z) for z in zip(a, b)],radius=["20%", "60%"], # 半径长度rosetype="radius" # 扇区圆心角展现数据的百分比,半径展现数据的大小).set_global_opts(title_opts=opts.TitleOpts(title="淘宝商品保质期可视化图表", subtitle="8.19")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) # 数字项名称和百分比)pie.render('淘宝商品保质期统计.html')
在Pycharm里边运行代码之后,我们将会得到一个淘宝商品保质期统计.html文件,双击打开该HTML文件,在浏览器里边可以看到效果图,如下图所示。

相信有小伙伴肯定感觉哪里不对,一个保质期的可视化,做成这种饼图似乎太丑了吧?嗯,的确是丑爆了,所以程序大佬把保质期这个图转为了柱状图,这样看上去就高大上很多了。
3、生成保质期可视化柱状图
其实数据都是一样的,只不过呈现方式不同,直接上代码。
"""生成保质期可视化图表"""
def get_date_html(df):# 词表分词names = df.保质期.apply(jieba.lcut).explode()df1 = names[names.apply(len) > 1].value_counts()# 写入分词后的结果with pd.ExcelWriter("淘宝数据.xlsx") as writer:df1.to_excel(writer, sheet_name="保质期")fpath = r'C:\Users\dell\Desktop\崔佬\数据分析综合实战\淘宝数据.xlsx'# 读取数据 提取列df1 = pd.read_excel(fpath, header=None, skiprows=1, names=['bzq', 'rq'])a = df1['bzq'].to_list()[:50]b = df1['rq'].to_list()[:50]bar = (Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK)).add_xaxis(a).add_yaxis("保质期(天数)",b).set_global_opts(title_opts=opts.TitleOpts(title="Bar-DataZoom(slider-保质期)"),datazoom_opts=opts.DataZoomOpts(),))return bar
这么处理之后,我们就会得到一个柱状图了,如下图所示。
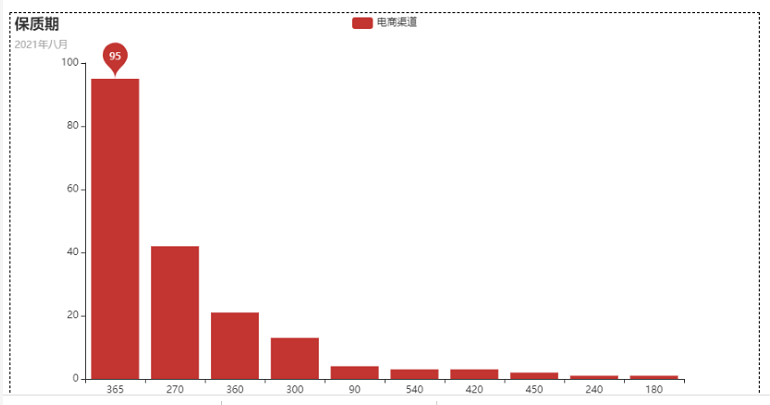
这把看上去,是不是觉得清晰很多了呢?
不过呢,程序大佬还觉得不够,想把这两张图放到一起,这应该怎么办呢?
4、合并饼图和柱状图到一个HTML文件
其实这个也并不难,只需要将生成两个图的函数放到一个布局类里边就可以完成了,直接上代码。
def page_draggable_layout(df):page = Page(layout=Page.DraggablePageLayout)page.add(get_ingredients_html(df),get_date_html(df))page.render("page_draggable_layout.html")
如果你想在一个HTML文件里边加入更多的图,只需要继续在add()函数里面进行添加生成可视化图的函数即可。话不多说,直接上效果图。

从上图我们可以看到配料饼图和保质期柱状图都同时在同一个HTML文件出现了,而且也是可以进行点击交互的噢!我们还可以收到拖拽,让图表移动,如下图所示,分为左右图进行展示。
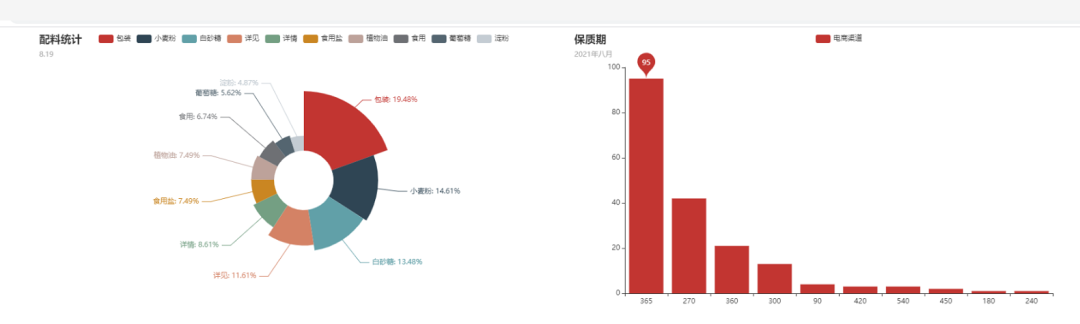
你以为到这里就结束了?其实并没有,程序大佬还想玩点更加高大上的,他想把table表一并显示出来,这样显得更加饱满一些。那么table表又如何来进行显示呢?
5、table表加持
其实在这里,程序大佬卡了一下,他在群里问,基于他目前的数据,像下图这样的df数据如何进行展示出来。

而且,他自己在不断的尝试中,始终报错,一时间丈二和尚摸不着头脑,不知如何是好。
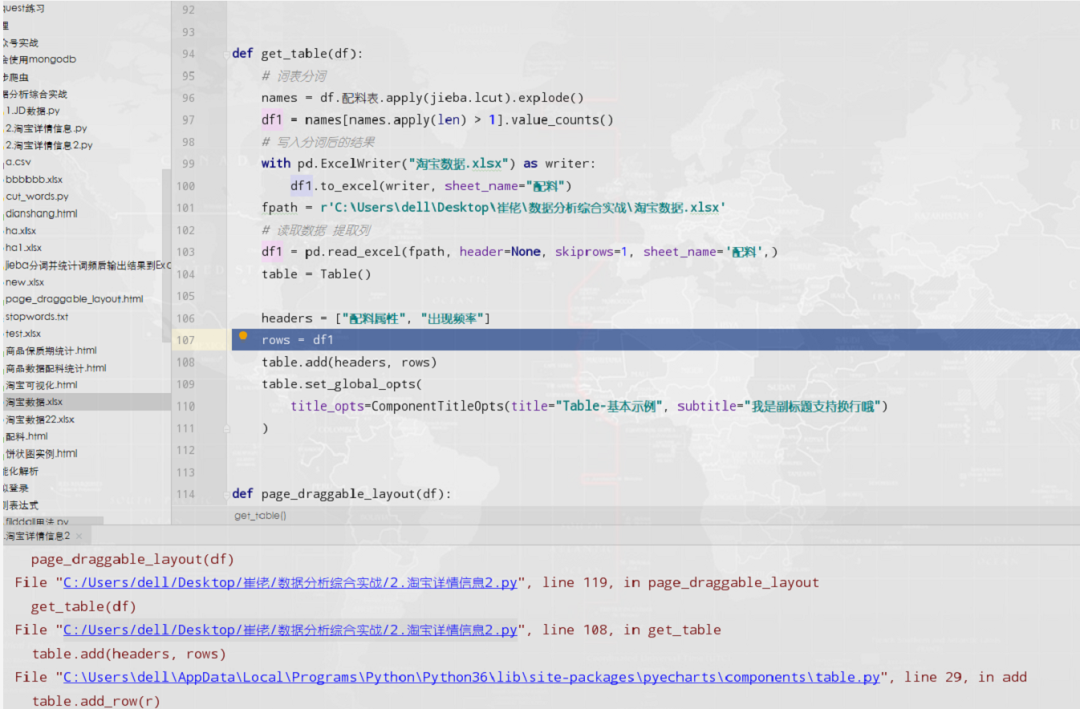
不过此时小小明大佬,又递来了橄榄枝,人狠话不多,直接丢了两行代码,让人拍手叫绝。
然后程序大佬,拿到Pycharm中一跑,啪,成了,真是拍案叫绝,小小明yyds!那么呈现的效果图是下面这样的。

这样看上去还稍微不太好看,拖拽下,调整下格式看看,如下图所示。

但是这样一看,确实高大上了一些,不过还是达不到程序大佬心里的预期,于是乎他继续折腾。
6、调整图像背景色
现在呢,程序大佬又想要加点背景色,这样显得高大上一些,代码如下。
# 绘制可视化图表
pie = (Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK)).add('', [list(z) for z in zip(a, b)],radius=["20%", "60%"], # 半径长度rosetype="radius" # 扇区圆心角展现数据的百分比,半径展现数据的大小).set_global_opts(title_opts=opts.TitleOpts(title="配料统计", subtitle="8.19")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) # 数字项名称和百分比)
return pie
其实核心的那句代码下面这个,引入了一个主题:
init_opts=opts.InitOpts(theme=ThemeType.CHALK)

得到的效果图如上图所示了。
7、添加漏斗图
这里是以数据里边的”食品添加“列来做实例的,代码如下所示。
def get_sptj_data(df):# 词表分词names = df.食品添加剂.apply(jieba.lcut).explode()df1 = names[names.apply(len) > 1].value_counts()# 写入分词后的结果with pd.ExcelWriter("淘宝数据.xlsx") as writer:df1.to_excel(writer, sheet_name="食品添加剂")fpath = r'C:\Users\dell\Desktop\崔佬\数据分析综合实战\淘宝数据.xlsx'# 读取数据 提取列df1 = pd.read_excel(fpath, header=None, skiprows=1, names=['sptj', 'sj'])a = df1['sptj'].to_list()[:10]b = df1['sj'].to_list()[:10]c = (Funnel(init_opts=opts.InitOpts(theme=ThemeType.CHALK)).add("商品",[list(z) for z in zip(a, b)],label_opts=opts.LabelOpts(position="inside"),).set_global_opts(title_opts=opts.TitleOpts(title="Funnel-Label(food_add)")))return c
得到的效果图如下图所示。

写到这里,基本上快接近尾声了,不过程序大佬为了感谢小小明大佬,后来又补充了一个极化装逼图来赞扬小小明。
8、极化图
直接上代码,程序大佬取的这个zb函数,就是装13的意思,取的太没有水平了。
def zb_data():data = [(i, random.randint(1, 100)) for i in range(10)]c = (Polar().add("",data,type_="effectScatter",effect_opts=opts.EffectOpts(scale=10, period=5),label_opts=opts.LabelOpts(is_show=False),).set_global_opts(title_opts=opts.TitleOpts(title="Polar-没啥用,用来装逼,小小明yyds")))return c
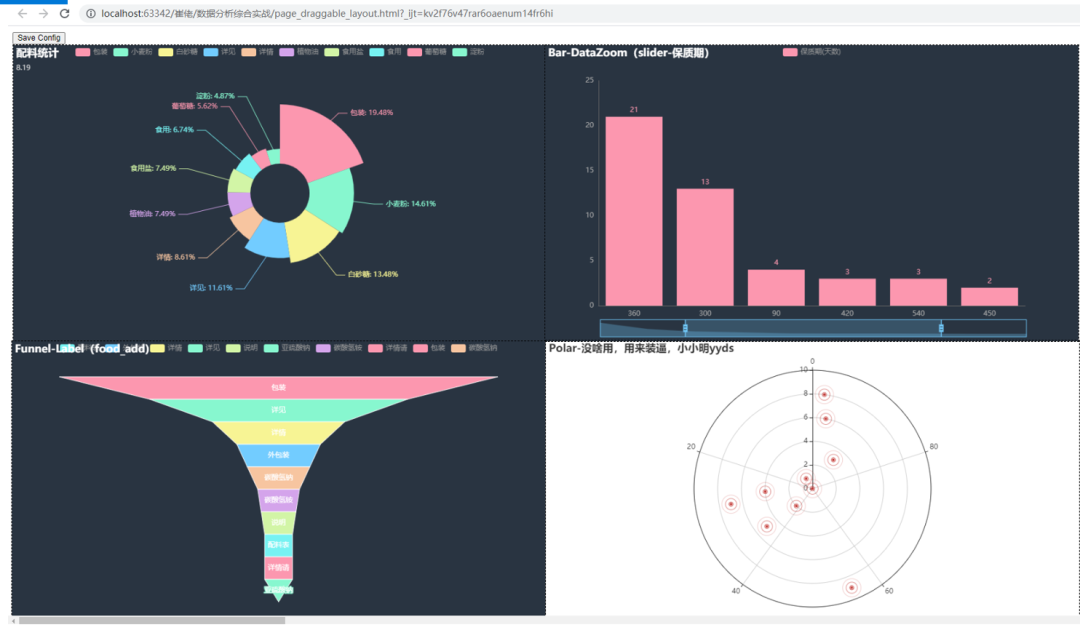
看上去确实很高大上呢。
三、总结
大家好,我是Python进阶者。本文基于一份杂乱的淘宝原始数据,利用正则表达式re库和Pandas数据处理对数据进行清洗,然后通过stop_word停用词对得到的文本进行分词处理,得到较为”干净“的数据,之后利用传统方法和Pandas优化处理两种方式对数据进行词频统计,针对得到的数据,利用Pyecharts库,进行多重可视化处理,包括但不限于饼图、柱状图、Table表、漏斗图、极化图等,通过一系列的改进和优化,一步步达到想要的效果,可以说是干货满满,实操性强,亲测有效。
最后非常感谢程序大佬和小小明大佬在期间不断提供的代码,也感谢我自己花时间和心思把这些看似杂乱的消息整理成文,分享给大家学习。有需要本文中完整代码文件的小伙伴,可以在后台直接回复关键词”程序和小小明大佬“即可获取。
我的这个Python交流群已经300多人了,有需要加入该群的小伙伴可以加我好友,一起学习,共同进步。

------------------- End -------------------
往期精彩文章推荐:
手把手教你用Python改造一款外星人入侵小游戏
手把手教你用Python网络爬虫+自动化来创建一位属于你自己的虚拟女票(附源码)
Python也能操作Mysql数据库
盘点那些年我们一起玩过的网络安全工具

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
这篇关于手把手教你用Pyecharts库对淘宝数据进行可视化展示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




