本文主要是介绍ArcGIS空间分析——空间聚类模式分析(聚类模式、离散模式还是随机模式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
比如我们在判断要素属性在空间上是否是随机分布的,或者是聚集的,或者是不是离散的
就需要考虑要素的空间相关关系
如果您在景观分布(或空间数据)中发现了空间结构(如聚类),就证明某些基础空间过程在发挥作用,而这方面通常正是地理学者或 GIS 分析人员所最为关注的。
简单利用ArcGIS分析空间全局自相关和空间局部自相关关系
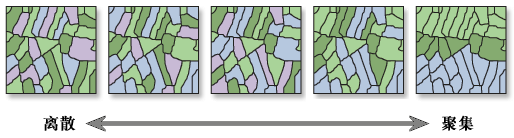
判断空间全局聚集特征
全局 Moran’s I
指数说明:
Moran’s I指数是运用最为广泛的全局指数之一,它通常使用单一属性来反映研究区域中邻近地区是相似、相异还是相互独立,判断该属性值在空间上是否存在聚集特征,进而反应其均等化程度。
工具:


在给定一组要素及相关属性的情况下,该工具评估所表达的模式是聚类模式、离散模式还是随机模式。
z 得分和 p 值是统计显著性的量度,用来判断是否拒绝零假设。对于此工具,零假设表示与要素相关的值随机分布。
使用 z 得分或 p 值指示统计显著性时,如果 Moran’s I 指数值为正则指示聚类趋势,如果 Moran’s I 指数值为负则指示离散趋势, Moran’s I 指数值为零则表示数据是随机分布的。
注意:最好使用投影数据
如图:
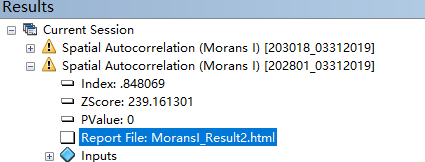
Moran’s I 指数值为0.848,表示数据是空间聚类的。
那么z-score和p-value怎么解读呢?

ArcGIS官方说明文档:
大多数统计检验在开始时都首先确定一个零假设。模式分析工具所返回的 z 得分和 p 值可帮助您判断是否可以拒绝零假设。p 值表示概率。对于模式分析工具来说,p 值表示所观测到的空间模式是由某一随机过程创建而成的概率。当 p 很小时,意味着所观测到的空间模式不太可能产生于随机过程(小概率事件),因此您可以拒绝零假设。
Z 得分表示标准差的倍数。例如,如果工具返回的 z 得分为 +2.5,我们就会说,结果是 2.5 倍标准差。如下所示,z 得分和 p 值都与标准正态分布相关联。
要拒绝零假设,您必须对所愿承担的可能做出错误选择(即错误地拒绝零假设)的风险程度做出主观判断。因此,请先选择一个置信度,然后再执行空间统计。典型的置信度为 90%、95% 或 99%。这种情况下,99% 的置信度是最保守的,这表示您不愿意拒绝零假设,除非该模式是由随机过程创建的概率确实非常小(低于 1% 的概率)
那么上面的值在2.58以上,表示显著性极高。p值为零,置信度在99%以上。

这个报告结果怎么查看呢?
判断空间局部聚集特征
局部 Maran’s I(local Maran’s I)
说明:
给定一组加权要素,使用 Anselin Local Moran’s I 统计量来识别具有统计显著性的热点、冷点和空间异常值。正值 I 表示要素具有包含同样高或同样低的属性值的邻近要素;该要素是聚类的一部分。负值 I 表示要素具有包含不同值的邻近要素;该要素是异常值。

工具:

结果说明:
生成具有统计显著性的高值 (HH) 聚类、低值 (LL) 聚类、高值主要由低值围绕的异常值 (HL) 以及低值主要由高值围绕的异常值 (LH)。
这是上海市医疗服务可达性的空间局部相关关系图
通过图可分析高可达性和低可达性空间相关关系。

更多:“聚类和异常值分析 (Anselin Local Moran’s I)”的工作原理:http://desktop.arcgis.com/zh-cn/arcmap/latest/tools/spatial-statistics-toolbox/h-how-cluster-and-outlier-analysis-anselin-local-m.htm
这篇关于ArcGIS空间分析——空间聚类模式分析(聚类模式、离散模式还是随机模式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






