本文主要是介绍Standford NLP Course(2) - Edit Distance,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Minimum edit distance
How similar are two strings? letter scale / word scale
- Insertion
- Deletion
- Substitution
For two strings
X of length n
Y of length m
Define D(i,j)
the edit distance between X[1 … i] and Y[1 … j]
the edit distance between X and Y is D(n,m)
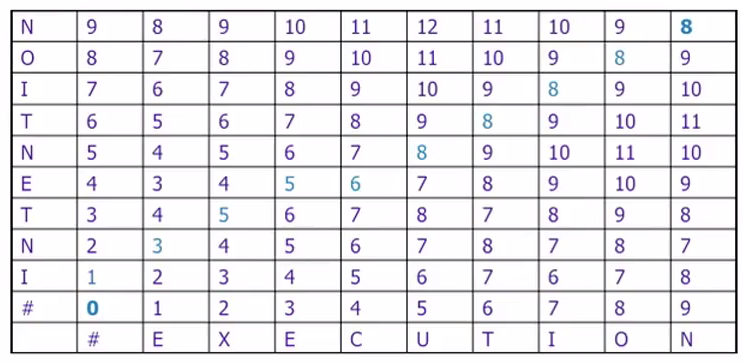
Dynamic Programming for Minimum edit distance动态规划计算最小编辑距离
Levenshtein 莱文斯顿距离
Bottom-up

1. 第一行 第一列加#,表示空字符
2. 空字符和任意x个字符距离都是x,因此第一行第一列直接填1 2 3…
3. 如果第i行第j列字母相同,比较左侧+1(insertion),下面+1(deletion),左下三个数字,取最小值
4. 如果第i行第j列字母不同,比较左侧+1,下面+1,左下+2三个数字(substitution),取最小值
Backtrace
得到距离,还需要知道它是怎么得来的
左侧:Insertion
下方:Deletion
左下:Substitution
Performance
Time: O(nm)
Space: O(mn)
Backtrace: O(m+n)
Weighted Minimum edit distance
Spell Correction: some letters are more likely to be mistyped than others
Biology: certain kinds of deletions or insertions are more likely than others

Minimum Edit Distance in Computational Biology
加了两种情况
所求的不是两者间的距离,而是两者的相似度
可以掐头去尾
但从视频里看更多地用于基因链条分析等等,算法也相对类似,就不仔细贴了
这篇关于Standford NLP Course(2) - Edit Distance的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




