本文主要是介绍mysql 快速生成百万条测试数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、生成思路
利用mysql内存表插入速度快的特点,先利用函数和存储过程在内存表中生成数据,然后再从内存表插入普通表中
2、创建内存表及普通表
-
CREATE TABLE `vote_record_memory` ( -
`id` INT (11) NOT NULL AUTO_INCREMENT, -
`user_id` VARCHAR (20) NOT NULL, -
`vote_id` INT (11) NOT NULL, -
`group_id` INT (11) NOT NULL, -
`create_time` datetime NOT NULL, -
PRIMARY KEY (`id`), -
KEY `index_id` (`user_id`) USING HASH -
) ENGINE = MEMORY AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
-
CREATE TABLE `vote_record` ( -
`id` INT (11) NOT NULL AUTO_INCREMENT, -
`user_id` VARCHAR (20) NOT NULL, -
`vote_id` INT (11) NOT NULL, -
`group_id` INT (11) NOT NULL, -
`create_time` datetime NOT NULL, -
PRIMARY KEY (`id`), -
KEY `index_user_id` (`user_id`) USING HASH -
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
3、创建函数及存储过程
-
CREATE FUNCTION `rand_string`(n INT) RETURNS varchar(255) CHARSET latin1 -
BEGIN -
DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'; -
DECLARE return_str varchar(255) DEFAULT '' ; -
DECLARE i INT DEFAULT 0; -
WHILE i < n DO -
SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*62 ),1)); -
SET i = i +1; -
END WHILE; -
RETURN return_str; -
END
-
CREATE PROCEDURE `add_vote_memory`(IN n int) -
BEGIN -
DECLARE i INT DEFAULT 1; -
WHILE (i <= n ) DO -
INSERT into vote_record_memory (user_id,vote_id,group_id,create_time ) VALUEs (rand_string(20),FLOOR(RAND() * 1000),FLOOR(RAND() * 100) ,now() ); -
set i=i+1; -
END WHILE; -
END
4、调用存储过程
CALL add_vote_memory(1000000)
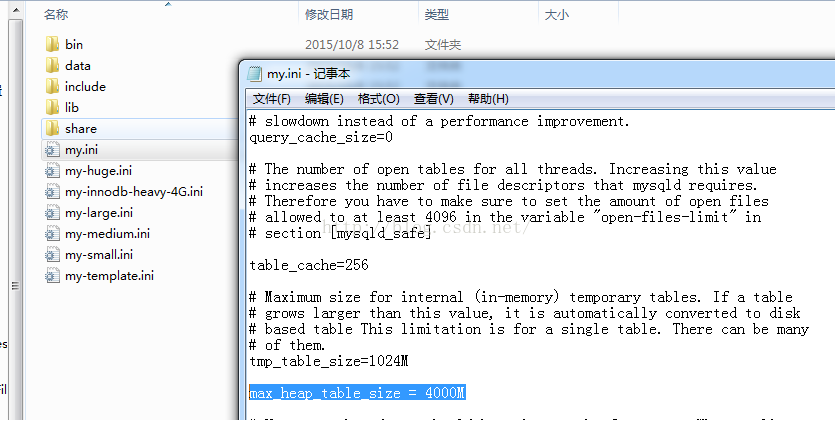
根据电脑性能不能所花时间不一样,大概时间在小时级别,如果报错内存满了,只在修改max_heap_table_size 个参数即可,win7修改位置如下,linux,修改my.cnf文件,修改后要重启mysql,重启后内存表数据会丢失
5、插入普通表中
INSERT into vote_record SELECT * from vote_record_memory
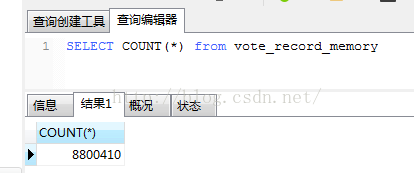
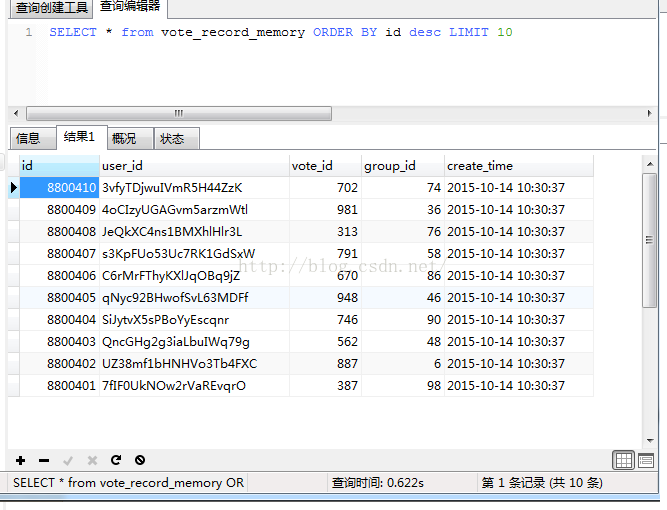
6、结果
这篇关于mysql 快速生成百万条测试数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






