本文主要是介绍C语言版---双向循环链表排序,冒泡排序,选择排序,插入排序,快速排序,应有尽有,取之不尽用之不竭,交换节点版本,没有bug,保证看懂!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、废话不多说,直接上代码
如果想看单链表排序的朋友,可以在我的博客里找,点击左边。
你好
#include <stdio.h>
#include <stdlib.h>typedef struct node
{int data;struct node *prev;struct node *next;
}node;//生成一个节点
node *initList(void)
{node *new = malloc(sizeof(node));if(!new){printf("malloc fail!\n");return NULL;}new->data = 0;new->prev = new;new->next = new;return new;
}//头插法插入一个节点
void head_insert(node *head, node *new)
{new->next = head->next;head->next->prev = new;head->next = new;new->prev = head;
}
//尾插法插入一个节点
void tail_insert(node *head, node *new)
{new->prev = head->prev;head->prev->next = new;new->next = head;head->prev = new;
}//弹出一个节点
void Remove(node *new)
{new->prev->next = new->next;new->next->prev = new->prev;new->next = new;new->prev = new;
}
//遍历
void traverse(node *head)
{for(node *p = head->next; p != head; p = p->next){printf("%d ", p->data);}printf("\n");
}//选择排序
void choose_sort(node *head)
{//头结点是空的或者表是空的或者表只有一个节点时候不用排if(!head || head->next == head || head->next->next == head) {return;}node *p, *min, *tail;//tail及tail前面是排好序的,每次从tail后面选出一个最小值,插入到tail前面,直到等于head结束for(tail = head; tail->next != head; tail = tail->next){//从tail->next->next开始,到等于head时结束,与tail->next比较找出最小值minfor(min = tail->next, p = min->next; tail != head, p != head; p = p->next){if(min->data > p->data) //找到一个比min更小的,就记录{min = p; //由于是双向循环链表不需要记录min的前驱节点}}printf("本轮排序选择出的最小值: %d\n", min->data);if(min != tail->next) //如果tail->next本来就是本轮的最小值,则不用交换{/*弹出min节点min->prev->next = min->next;min->next->prev = min->prev; */Remove(min);/*尾插法插到tail后面min->prev = tail;min->next = tail->next;tail->next->prev = min;tail->next = min;*/head_insert(tail, min);}traverse(head); //显示每一轮排序结果}
}//冒泡排序
void bubble_sort(node *head)
{int flag;node *p, *tmp, *tail;tail = head; //tail以及tail后面的是排好序的元素,第一次还没有排好,所以为headwhile(1){flag = 1; //flag用来标志是否已经排好序//每次从head->next开始遍历,直到tail结束, prev是p的前驱节点for(p = head->next; p && p->next != tail;){//交换后,p已经移动到后面,不需要再遍历下一个if(p->data > p->next->data){flag = 0; //修改flag=0,标志本轮循环交换过tmp = p->next; //在弹出p节点前需先记录p->next节点/*弹出p节点p->prev->next = p->next;p->next->prev = p->prev;*/Remove(p);/*插入p节点p->next = tmp->next;tmp->next->prev = p;p->prev = tmp;tmp->next = p;*/head_insert(tmp, p);}else //没有交换就继续遍历下一个{p = p->next;}}printf("本轮排序移动出的最大值:%d\n", p->data);traverse(head); 显示每一轮排序结果if(flag) //如果内层循环中都没有交换过,则所有节点都已经是排好序的{printf("冒泡排序结束!\n");break;}tail = p; //tail向前移一个,tail以及tail后面的是排好序的元素}
}//插入排序,最优版本
void insert_sort(node *head)
{//头结点是空的或者表是空的或者表只有一个节点时候不用排if(!head || head->next == head || head->next->next == head) {return;}node *p, *q, *tail;//head->next->next开始遍历,tail及tail前面的是排好序的,p是本轮待插入值,等于head时结束for(tail = head->next, p = tail->next; p != head; p = tail->next){//从head->next开始遍历,直到tail结束for(q = head; q != tail; q = q->next){if(p->data < q->next->data) //插入后结束本次遍历{/*弹出p节点tail->next = p->next;p->next->prev = tail; */ Remove(p);/*把p节点插入到q->next前面,即q的后面p->next = q->next;q->next->prev = p;q->next = pp->prev = q;*/head_insert(q, p);break;}}printf("本轮排序插入值:%d, ", p->data);if(tail == q) //在tail前面没有插入,就下移{printf("已处于插入位置\n");tail = tail->next;}else{//p已经处于插入位置,显示时要用p->next->dataprintf("插入到%d的前面\n", p->next->data);}traverse(head); //显示每一轮排序结果}
}//快速排序的一次划分,第一种版本
node *partition(node *head, node *tail)
{node *p, *basic, *tmp;//从baisc后面开始遍历,找到比baisc小的就插入到head后面,直到tail结束,prev是p的前驱节点//这里head可以理解为本次待划分的链表的头结点,tail是链表的最后一个节点的下一个(NULL)for(basic = head->next, p = basic->next; p != tail; p = p->next){if(p->data < basic->data){//保留p->prev的位置, 交换后p要复位tmp = p->prev;/*弹出p节点p->next->prev = p->prev;p->prev->next = p->next;*/Remove(p);/*p节点插入到head后p->next = head->next;head->next->prev = p;p->prev = head;head->next = p;*/head_insert(head, p);//p复位p = tmp;}}return basic;
}//快速排序,第一种版本
void quick_sort(node *head, node *tail)
{//头结点是空的或者表是空的或者表只有一个节点时候不用排//tail是链表的结束点,一开始等于head,后面等于basicif(!head|| head->next == tail || head->next->next == tail){return;}//baisc前的节点都比basic小,baisc后的节点都比baisc大node *basic = partition(head, tail);printf("本次划分节点:%d\n", basic->data);quick_sort(head, basic); //把head->next到basic前一个进行递归排序quick_sort(basic, tail); //从basic->next到tail前一个进行递归排序
}//交换两节点,p, q互换
void swap(node *p, node *q)
{if(p->data == q->data){return;}node *tmp = p->prev; //记录p的前驱节点Remove(p); //弹出p节点head_insert(q, p); //把p插入到q后面Remove(q); //弹出q节点head_insert(tmp, q); //把q插入到tmp后面
}//快速排序的一次划分,第二种版本
node *partition2(node *head, node *tail)
{node *p, *q, *tmp;p = head->next; //这里head可以理解为本次待划分的链表的头结点q = tail->prev; //这里tail是链表的最后一个节点的后面,可以理解为NULL//区间长度等于零时结束//特别说明,内层循环中判断条件中,有且仅有一个内层循环要加“<=”号,二选一//内层循环只能是两个,如果是一个的话,会出错,举例:12 34 78 56 23 99 34 12 45 76while(p != q){//从后面开始往前遍历,直到p==q或者p->data大于等于q->datawhile(p != q && p->data < q->data){q = q->prev; }if(p == q) //如果p->data 都小于q->data,表示已经排好{break;}tmp = p->prev; //交换前先保留p->prev,用来复位p 和 qswap(p, q); //交换p和qq = p; //q复位p = tmp->next; //p复位//从前面开始往后遍历,直到p==q或者p->data大于q->datawhile(p != q && p->data <= q->data){p = p->next;}if(p == q) //如果p->data 都小于q->data,表示已经排好{break;}tmp = p->prev; //交换前先保留p->prev,用来复位p 和 qswap(p, q); //交换p和qq = p; //q复位p = tmp->next; //p复位}return p;
}//快速排序,第二种种版本
void quick_sort2(node *head, node *tail)
{//头结点是空的或者表是空的或者表只有一个节点时候不用排//tail是链表的结束点,一开始等于head,后面等于basicif(!head|| head->next == tail || head->next->next == tail){return;}//baisc前的节点都比basic小,baisc后的节点都比baisc大node *basic = partition2(head, tail);printf("本次划分节点:%d\n", basic->data);quick_sort2(head, basic); //把head->next到basic前一个进行递归排序quick_sort2(basic, tail); //从basic->next到tail前一个进行递归排序
}int main(void)
{int i, len;node *head, *new, *p, *q;printf("请输入双向循环链表的长度: ");scanf("%d", &len);head = initList();head->data = len;printf("请输入元素:");for(int i = 0; i<len; i++){new = initList();scanf("%d", &new->data);tail_insert(head, new);}printf("请选择排序方式,1.选择排序 2.冒泡排序 3.插入排序 4.快速排序: ");scanf("%d", &i);printf("排序前:\n");traverse(head);switch(i){case 1:choose_sort(head);break;case 2:bubble_sort(head);break;case 3:insert_sort(head);break;case 4:quick_sort2(head, head);break;}printf("由小到大排序后:\n");traverse(head);return 0;
}温馨提示:
如果复制时发现有缩进报错,后者空格报错等问题,以VScode为例,可以按Ctrl+F,复制一个报错的空格,然后替换成一个手打的空格键,具体操作可以搜搜,可以看我的博客。
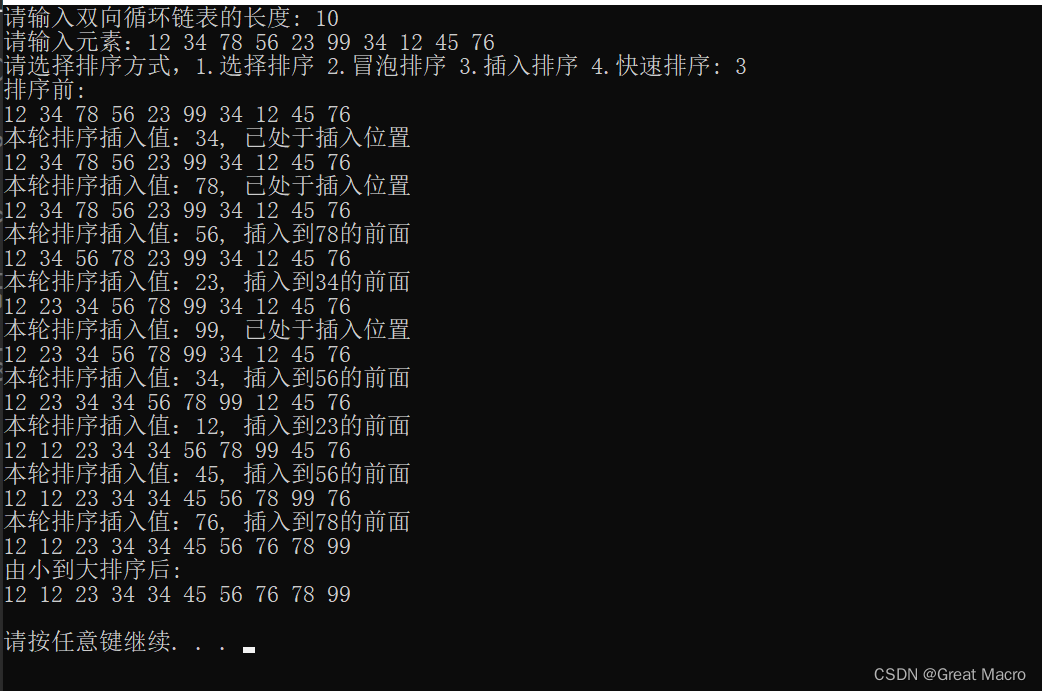
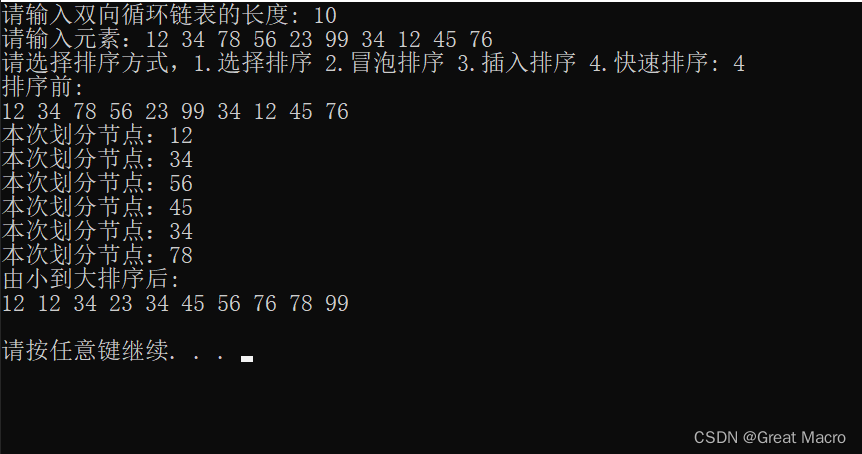
具体截图:以 12 34 78 56 23 99 34 12 45 76为例,其他朋友可以自己举
选择排序
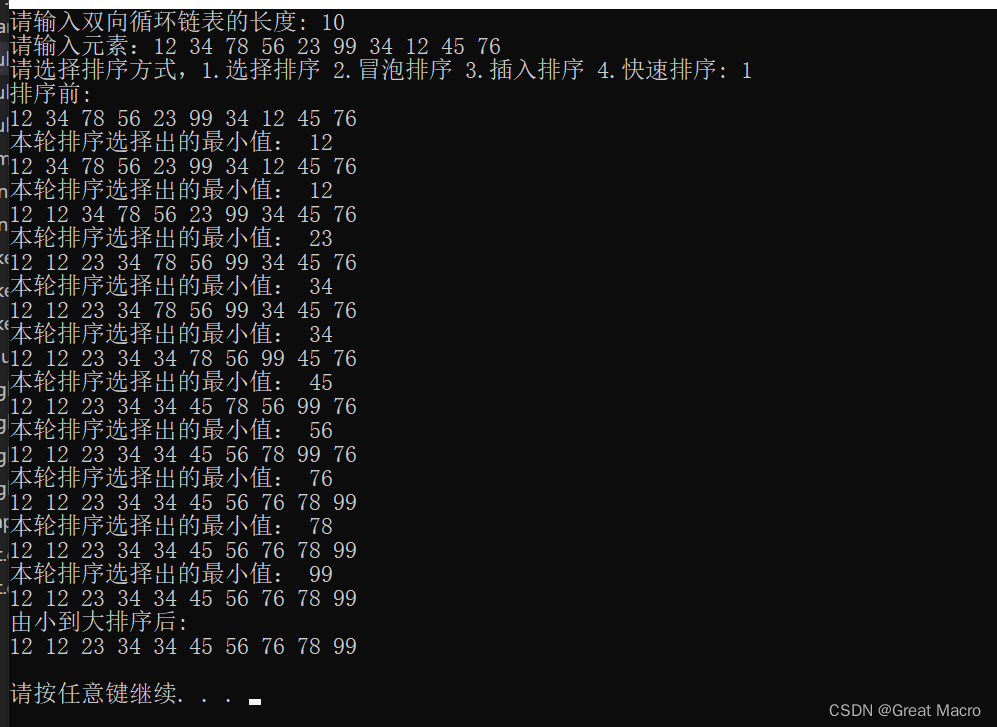
冒泡排序

插入排序
快速排序
二、代码分析
如果你认真看完上述的代码和注释,那么,我可以大概率保证你基本可以看懂了双向循环链表的排序,其实也不难,就是在关键步骤和控制条件。下面来仔细分析每个排序的关键步骤和控制条件。
冒泡排序
思路:冒泡排序就是从首元结点开始,左右两两比较大小,以从小到大排序为例,如果比后面一个的节点大,就交换,然后继续往后比较,直到到达已经排好的元素为止。
特点:每一轮冒泡排序结束后,总会把最大的节点放到最后面,不断的往前移,直到头结点,就结束了。
注意的地方:单链表的交换,不同于数组的交换,单链表的交换后,以p和q为例,p在q的前面,如果p->data > q->data,就交换p和q节点,交换后p已经处于下一次待交换的位置,所以不需要在p = p->next了,否则会漏了一个没排,出错,需要特别注意!跟单链表的差不多!
优化地方:1.设置flag,来标志链表中的元素是否已经是排好序的,因为这里做可以用一次循环判断出链表中的元素是否已经排好,而不用进行无用的多层循环。2.设置一个tail,来指明后面的节点是排好的,当遍历到tail时,就结束本轮循环,同时tail前移一个。
选择排序
思路:选择排序就是每次从未排好的节点中,通过遍历比较大小的方法,选择出一个最小的(以从小到大排为例),然后插入到排好的后面,这样,每轮循环就可以选出一个最小的,直到全部插入完为止。
特点:跟插入排序很像,但两者略有不同,选择排序先选出最小的,然后直接插入到排好元素的后面,而插入排序是直接选出一个节点,然后通过和排好的元素进行比较大小来插入到合适的位置。
注意的地方:以从小到大排为例,采用尾插法应该是每次选取最小的,如果采用头插法应该是每次选取最大的。跟单链表的差不多!
优化地方:如果这个节点本来就处于待插入地方,即当前最小的,就不需要交换了,直接进行下一轮。设置一个tail标志,之所以说有点像插入排序,就是体现在这里了。
插入排序
思路:插入排序就是每次直接从未排好序的节点中拿一个出来,一般是下一个;然后在排好序的节点中通过遍历的方法来比较应该插入到的位置,直到插完为止。
特点:直接选一个插入,不像选择排序那样,先选了,再插入。
注意的地方:需要设置标志tail来指明已经排好的节点的界限,遍历查找插入位置时,遇到tail,说明待插入节点是已经排好的节点中最大的,不需要插入,同时tail要后移一个。跟单链表的差不多!
优化地方:tail标志和直接插入。
快速排序
思路:每次选中一个基准点,然后从基准点后面开始遍历,如果找到比基准点小节点(以从小到大排为例),就插入到基准点前面,直到链表的尾部,结束。这样每一次划分后,处于基准点前面的节点都比基准点小,处于基准点后面的节点都比基准点大。然后分别递归划分基准点前的节点和后的节点。
特点:每次划分结束后能找到一个基准点,可以看成是中位数,然后递归。有点像二分查找,跟一颗二叉树差不多。
注意的地方:第一次传参数时,传head(头节点)和NULL。而且需要严格控制退出条件,头结点为空,或者没有节点,或者只有一个节点时,不用排,直接返回。
优化的地方:这里写了两种版本的,第一种,采用先定好基准点,后比较的方法,详情可以看我的博客里的单链表排序或者上面的讲解。
另外一种版本,采用先比较,然后找出基准点,就是数组常用的,往中间靠的方法,一个head和tail,如果head<tail,tail就一直往前移,然后如果head<tail,head就一直往后移,直到head == tail是就是本次划分的基准点。因为是双向循环链表,有前指针,所以可以采用这种方法,单链表一般不采用这种方法,时间复杂度太高。
三、总结
如果之前看过我博客里写的单链表排序,对于写双向循环链表排序,基本上直接搬过来就行,只需要修改一下结束条件单链表的为NULL,双向循环链表的为头结点head。
虽然这么做很方便,但是体现不了双向循环链表的灵魂,单链表每次交换时,要额外寻找到其前驱节点,而双向循环链表不需要,直接就可以用,因为其本来就有前指针。所以我特意优化了某些地方,详情请对比两篇CSDN的代码注释。
本期排序算法到这里,结束了,如果你觉得我写的不错,可不可以给我一个点赞,收藏,转发,评论等等,你们的支持,是我最大的动力!^_^
下一期准备出C语言版的数组排序,冒泡排序,选择排序,插入排序,快速排序,堆排序,希尔排序等。记得关注我哦!^_^
这篇关于C语言版---双向循环链表排序,冒泡排序,选择排序,插入排序,快速排序,应有尽有,取之不尽用之不竭,交换节点版本,没有bug,保证看懂!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







