本文主要是介绍rabbitmq界面主要参数分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇主要分析rabbitmq broker界面参数
rabbitmq界面主要参数分析
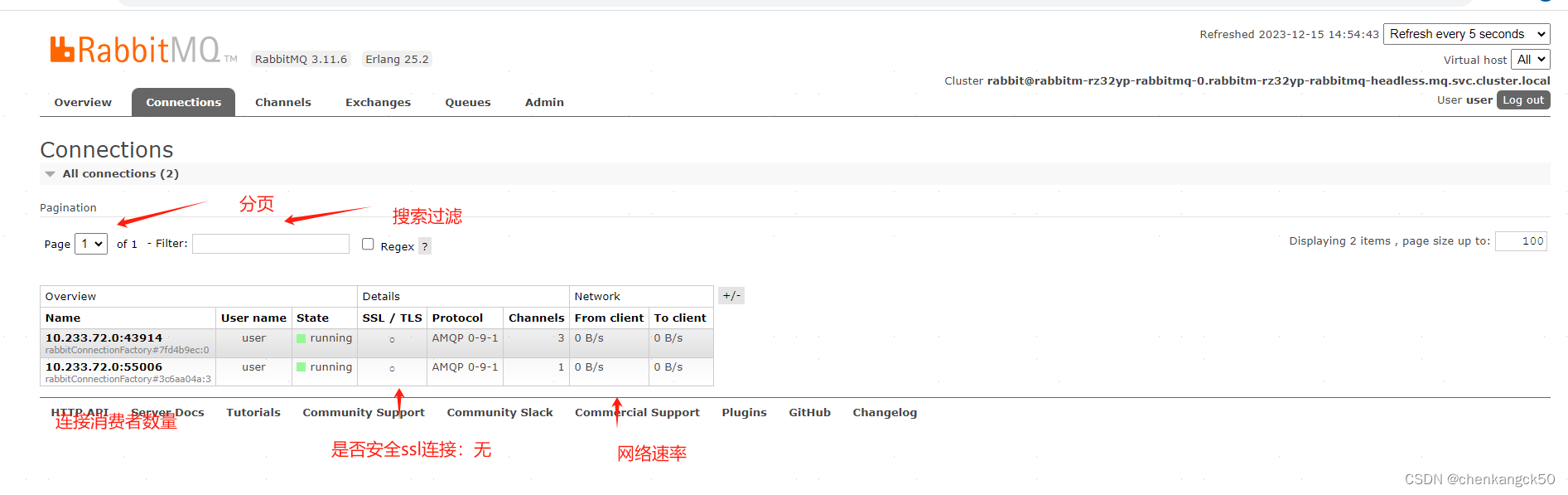
1、connections
User Name: user - 连接所使用的用户名。
State: running - 连接当前的状态,这里表明连接是活动的。
SSL/TLS: ○ - 表示这个连接没有使用SSL/TLS加密。 内部或受信任的网络中可能是可接受的,但在公共或不受信任的网络中可能需要考虑加密通信
Protocol: AMQP 0-9-1 - 使用的协议版本。
Channels: 3 - 通过这个连接开启的通道数量。
From Client: 0 B/s - 客户端到服务器的数据流速率。
To Client: 0 B/s - 服务器到客户端的数据流速率。
注释:即使没有发布,也有少量的数据流速,例如心跳信号(Heartbeats) 管理和监控数据等
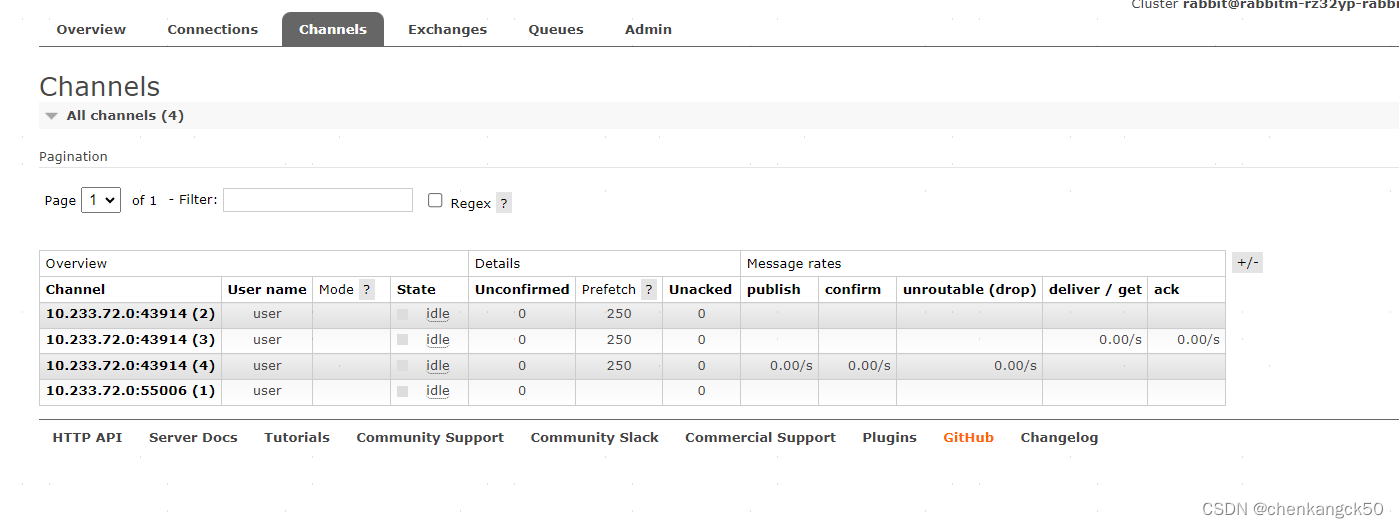
2.channels
“通道”(Channels)是建立在客户端与服务器之间单个TCP连接上的虚拟连接。这是 AMQP(高级消息队列协议)的一个关键概念,它允许多个轻量级的通道复用同一个TCP连接,从而减少了网络资源的消耗和建立多个物理连接的开销。
通道的作用:
1.资源效率:通过复用单个TCP连接,通道极大地提高了网络资源的利用率。
2并行处理:客户端可以在不同的通道上并行执行多个操作,例如,一个通道用于发送消息,另一个用于接收消息。
3.隔离:每个通道相互独立,一个通道上的失败不会直接影响到其他通道。
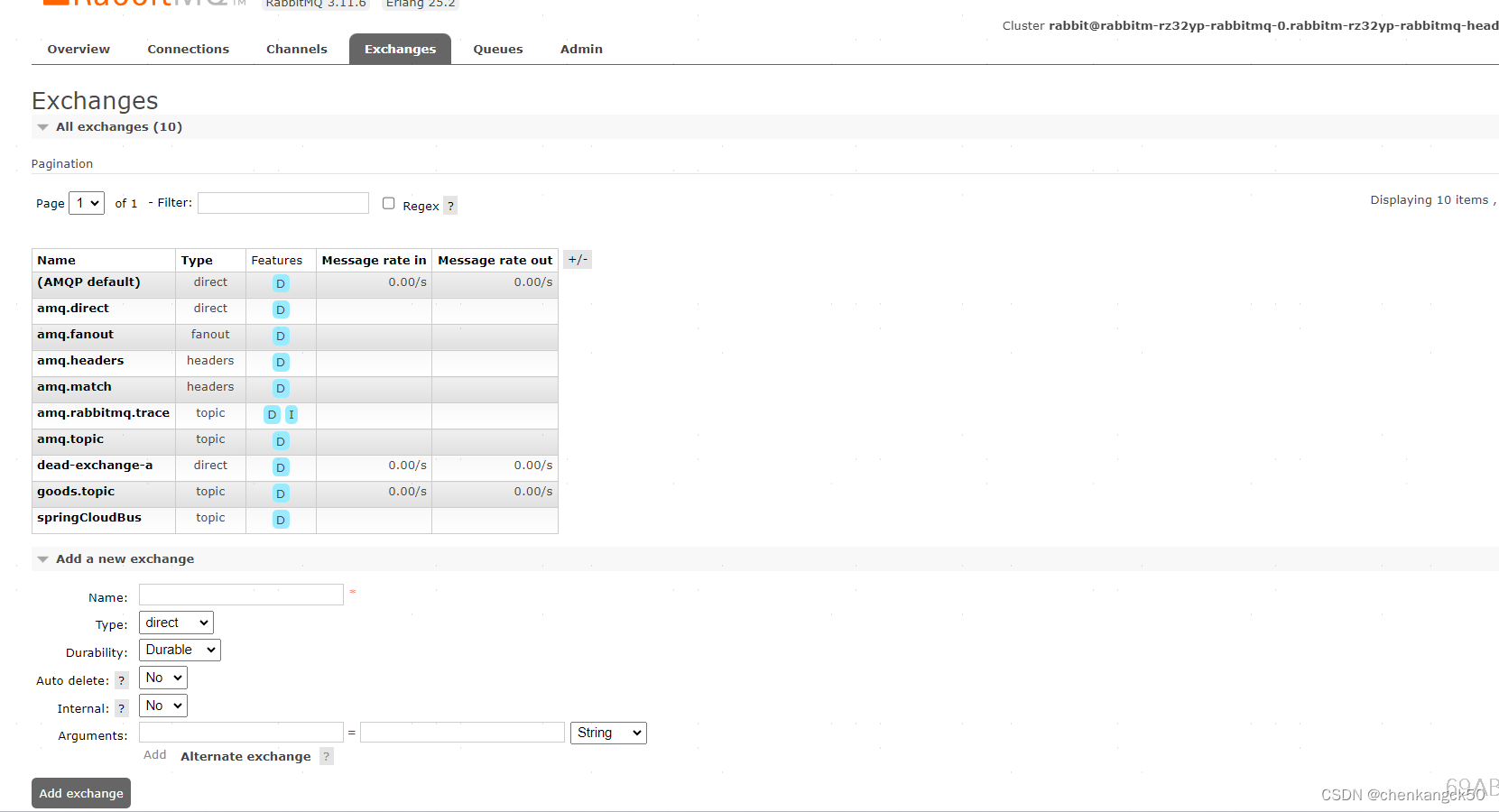
3.exchanges
您提供的信息是 RabbitMQ 消息队列系统中交换器(Exchanges)的列表。在 RabbitMQ 中,交换器是一种路由消息的机制,它定义了消息如何根据某种规则路由到队列。以下是对您列表中交换器的解释:
交换器列表
(AMQP default): 这是默认的直接交换器(Direct Exchange),用于默认的消息路由。
amq.direct: 另一个预定义的直接交换器。
amq.fanout: 预定义的扇出交换器(Fanout Exchange),广播消息到所有绑定的队列。
amq.headers: 预定义的头交换器(Headers Exchange),基于消息头的多条件匹配路由消息。
amq.match: 类似于头交换器。
amq.rabbitmq.trace: 用于追踪的主题交换器(Topic Exchange)。
amq.topic: 预定义的主题交换器。
dead-exchange-a: 用户定义的直接交换器,可能用于处理死信(失败的、未处理的消息)。
goods.topic: 用户定义的主题交换器,可能用于某些业务逻辑相关的消息路由。
springCloudBus: 用户定义的主题交换器,可能用于 Spring Cloud Bus 消息。
交换器属性
Type: 交换器的类型(如 Direct, Fanout, Headers, Topic)。
Features: 交换器的特性,D 表示持久化(Durable),I 表示内部(Internal)。
Message rate in/out: 显示消息进入和离开交换器的速率。
交换器的作用
交换器根据类型和绑定规则决定如何将消息路由到队列。例如:
Direct Exchange: 直接根据路由键将消息发送到指定的队列。
Fanout Exchange: 将消息广播到所有绑定的队列。
Topic Exchange: 根据模式匹配路由键来路由消息。
Headers Exchange: 根据消息头部的值和绑定的参数来路由消息。
添加新交换器
界面提供了添加新交换器的选项,您可以指定交换器的名称、类型、持久性等属性。
在 RabbitMQ 中,合理配置和使用交换器对于确保消息的正确路由和系统的高效运行至关重要。每种类型的交换器都适用于不同的场景和消息模式。
Name:
您需要为新交换器指定一个唯一的名称。这个名称用于在消息发布时指定消息应该发送到哪个交换器。
Type:
指定交换器的类型。常见的类型包括 direct, fanout, topic, 和 headers。每种类型根据不同的规则路由消息。
在您的例子中,选择的是 direct 类型,这意味着消息会根据消息的路由键(routing key)直接路由到绑定的队列。
Durability:
持久性(Durable)设置决定了交换器是否在 RabbitMQ 重启后仍然存在。
如果选择 “Durable”,交换器将在服务器重启后依然存在。
Auto delete:
这个选项决定了交换器在不再使用时是否自动删除。
如果选择 “No”,则交换器不会在停止使用后自动删除。
Internal:
内部(Internal)交换器不能由常规生产者直接发送消息到,只能由 RabbitMQ 服务器内部使用。
如果选择 “No”,则这个交换器可以被常规生产者使用。
Arguments:
这里可以指定一些交换器的额外参数,例如,可以设置某些插件或特殊行为的参数。
Add Alternate exchange:
可以指定一个备用交换器(Alternate Exchange)。当消息不能在当前交换器上被路由时,它们将被发送到这个备用交换器。
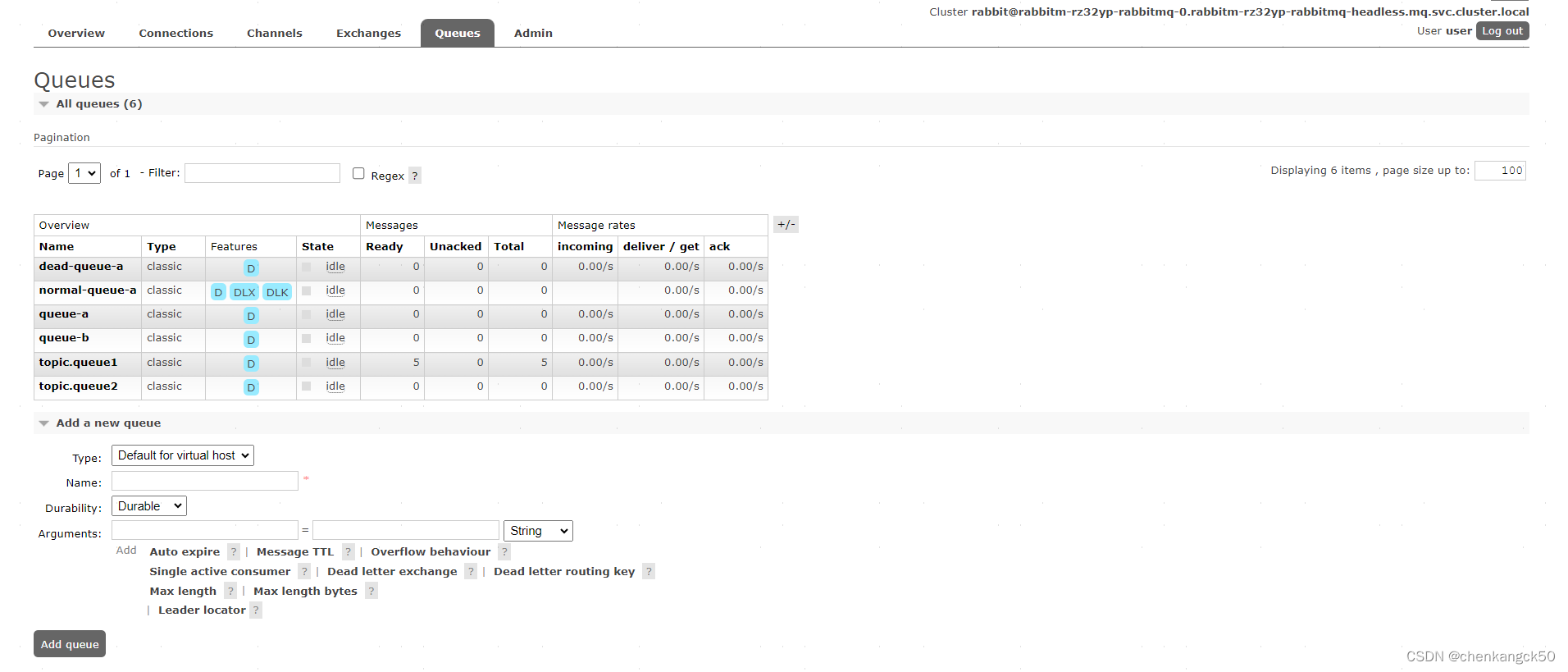
4.queues
队列列表
dead-queue-a: 一种典型的持久化(Durable)队列,当前处于空闲状态,没有准备好(Ready)、未确认(Unacked)或总计(Total)的消息。
normal-queue-a: 典型的持久化队列,带有死信交换(DLX)和死信路由键(DLK)特性,当前空闲,没有消息。
queue-a: 另一个典型的持久化队列,当前空闲,没有消息。
queue-b: 类似于 queue-a,一个空闲的持久化队列。
topic.queue1: 典型的持久化队列,有5条消息处于 Ready 状态,但当前没有消息被处理或确认。
topic.queue2: 典型的持久化队列,当前空闲,没有消息。
队列的属性
Type: 队列类型,这里都是“经典”(classic)。
Features: 队列的特性,如持久化(Durable,标记为 D)和死信路由相关特性(DLX, DLK)。
State: 队列的当前状态,如空闲(idle)。
Message Counts: 队列中的消息数量,分为 Ready、Unacked 和 Total。
Message Rates: 消息的流入(incoming)、分发/获取(deliver/get)和确认(ack)的速率。
添加新队列的选项
Type: 可选择的队列类型,如默认或根据虚拟主机(virtual host)设置。
Name: 指定新队列的名称。
Durability: 设置队列是否为持久化,持久化队列在 RabbitMQ 重启后依然存在。
Arguments: 设置其他队列参数,如消息的自动过期时间(Auto expire)、消息存活时间(TTL)、溢出行为(Overflow behaviour)、单一活跃消费者(Single active consumer)、死信交换和路由键(Dead letter exchange and routing key)、最大长度等。
Auto expire:
自动过期时间设置。如果队列在指定时间内未被使用(没有消费者连接),则会自动删除。
Message TTL (Time-To-Live):
消息存活时间。设定消息在队列中能存活的最长时间。超过这个时间的消息将被自动删除或转发到死信队列。
Overflow behaviour:
溢出行为。当队列达到最大长度时的处理方式,如拒绝新消息或丢弃旧消息。
Single active consumer:
单一活跃消费者。在这个模式下,即使有多个消费者连接到队列,也只有一个消费者能够消费消息。
Dead letter exchange:
死信交换器。无法处理的消息(如被拒绝或过期的消息)将被发送到指定的交换器。
Dead letter routing key:
死信路由键。指定发送到死信交换器的消息将使用的路由键。
Max length:
最大长度。队列可以存储的最大消息数量。
Max length bytes:
最大长度(字节)。队列可以存储的消息的最大总字节数。
Maximum priority:
最大优先级。设置队列支持的最大优先级数。消息可以根据优先级被更快地消费。
Lazy mode:
懒惰模式。在这种模式下,消息会被存储在磁盘上,而不是常驻内存,有助于处理大量消息
这篇关于rabbitmq界面主要参数分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






