本文主要是介绍路透社新闻分类--自然语言处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
路透社新闻分类
- 数据准备和载入
- 查看文件基本信息
- 创建网络模型
- 训练网络模型
- 词向量预训练与模型优化
embedding_matrix = pd.read_csv('embedding_matrix.csv')
embedding_matrix

import numpy as np
import pandas as pd
from tkinter import _flatten
import tensorflow as tfembedding_matrix = pd.read_csv('embedding_matrix.csv')
data = np.load('reuters.npz', allow_pickle=True)
data.files # 查看数据文件中的数据信息
X = data['x'] # 样本自变量
y = data['y'] # 样本标签(新闻主题类别)
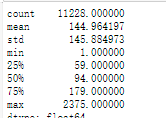
pd.Series(X).apply(len).describe() # 统计新闻词语数量的分布
wordList = _flatten(X.tolist()) # 将所有新闻报道转为一个一维元组
len(list(set(wordList))) # 对单词编码去重并统计单词数量
30979
X_padding = tf.keras.preprocessing.sequence.pad_sequences(X, maxlen=200, padding='post') # 执行padding操作
搭建RNN模型结构
input_shape=(200, )#文档长度
mask_zero=True
trainable=False不训练这个embedding
预训练embedding
30980*128=3965440就是我们要训练的参数的个数,即参数规模,这个参数是网络输出过程中的中间产物
# 搭建RNN神经网络模型
model = tf.keras.models.Sequential([tf.keras.layers.Embedding(30980, 128, input_shape=(200, ), mask_zero=True,weights=[embedding_matrix.values], trainable=False),tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)),tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(46, activation='softmax')
])
model.summary() # 查看网络结构

训练网络模型从而实现文本分类
# 网络模型训练参数设置
model.compile(loss='sparse_categorical_crossentropy',optimizer=tf.keras.optimizers.Adam(1e-4),metrics=['accuracy'])
model.fit(X_padding, y, validation_split=0.2, epochs=5, batch_size=8) # 模型训练

这篇关于路透社新闻分类--自然语言处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




