本文主要是介绍MNIST简单数据处理:哪个数字最费墨水?——Pandas入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
手写数据集MNIST的简单数据处理
数据集
来源–LIBSVM:
LIBSVM是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包。
数据格式:
该软件使用的训练数据和检验数据文件格式:
<label> <index1>:<value1> <index2>:<value2> …
<label> 为数据集标签,对于分类,它是标识某类的整数(支持多个类),本例中就是数字0~9;
<index> 是以1开始的整数,可以是不连续的,本例中就是28×28的灰度图像中,所代表的的像素点的编号,最大编号为784;
<value> 是实数,也就是自变量,在本例中为灰度值,取值(0, 1],若为0,则不会出现在数据集中。
原始数据集下载网址:https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/
下载mnist8m -> mnist8m.bz2 (大小约为19G)



处理过程
因为本例不涉及像素编号,所以提前预处理了像素编号和“:”,删掉了之后的数据集看起来是下面的样子。

过程很简单:
对于每一个数字,将该数字的灰度值求和,也就是整行求和。这个灰度值的和,就是我们认为该数字“耗费的墨水”。之后再对所有相同数字取平均值,并排序,得到每个数字耗费墨水的程度。
代码:
#!coding:utf-8
import sys
import time
import pandas as pd
import numpy as np# 计时
start = time.time()
df = pd.read_csv('sample1.csv', header=None, dtype=float)# 填充NAN值,因为每个数字对应的每行长度是不一样的
# 也就是占用的像素数不同,因此会出现很多Nan值,我们视为0
df = df.fillna(0)
# print(type(df[1][3]))
# dflist1 = [[]for i in range(2)]# 只提取了数据集的前300行来计算, width是行的长度
numbers = 300
width = 252# 每行灰度值求和
for j in range(numbers):grey_sum = 0for i in range(1, width):grey_sum = grey_sum + df[i][j]list1[0].append(df[0][j])list1[1].append(grey_sum)# 将list1转置为df2
df2 = pd.DataFrame(list1).transpose()# 将所有数字0~9的求和后的灰度值取平均
average = []
for i in range(0, 10):df_k = df2[df2[0] == i]num_count = df_k.shape[0]average.append(np.sum(df2[df2[0] == i])/num_count)# 排序
final_results = sorted(average, key = (lambda average: [average[1], average[0]]))# 转DataFrame,设置列标题
sort = pd.DataFrame(final_results)
sort.columns = ['Number', 'Grayscale Value']
print(sort)end = time.time()
print('Time used:', end-start)
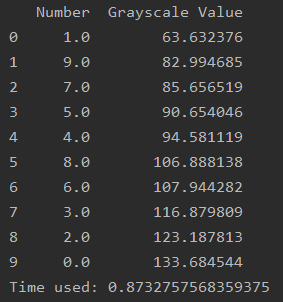
输出:
最费墨水的竟然是0……
整篇代码很多冗余操作,只是为了多涉及几个Pandas的基础用法,仅供参考使用方法,编程思路不建议学习,其实很多操作可以几行搞定。
预处理过后的数据样本“sample1.csv”很小,就几百K,只包含数据集中前300个数字。
https://pan.baidu.com/s/1S-uqxWLiGzyerUlfzzWDNg
提取码:og2b
更新:
网盘麻烦,我直接上传到主页资源了
有空整理一篇用Spark.sql的,因为其实原本就是Spark.sql做的。。
这篇关于MNIST简单数据处理:哪个数字最费墨水?——Pandas入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







