本文主要是介绍【华为数据之道学习笔记】5-4 数据入湖方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据入湖遵循华为信息架构,以逻辑数据实体为粒度入湖,逻辑数据实体在首次入湖时应该考虑信息的完整性。原则上,一个逻辑数据实体的所有属性应该一次性进湖,避免一个逻辑实体多次入湖,增加入湖工作量。
数据入湖的方式主要有物理入湖和虚拟入湖两种,根据数据消费的场景和需求,一个逻辑实体可以有不同的入湖方式。两种入湖方式相互协同,共同满足数据联接和用户数据消费的需求,数据管家有责任根据消费场景的不同,提供相应方式的入湖数据。
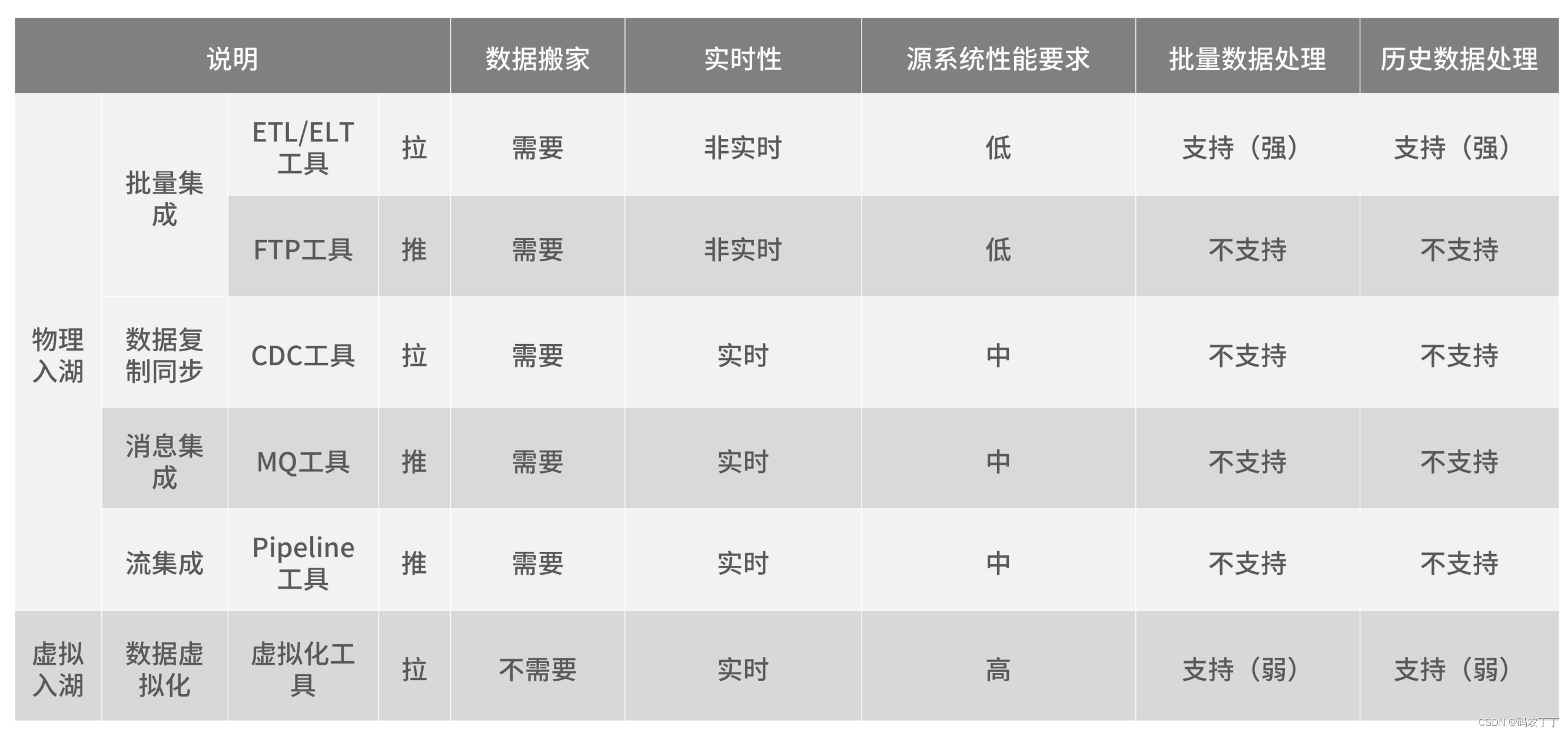
物理入湖是指将原始数据复制到数据湖中,包括批量处理、数据复制同步、消息和流集成等方式。虚拟入湖是指原始数据不在数据湖中进行物理存储,而是通过建立对应虚拟表的集成方式实现入湖,实时性强,一般面向小数据量应用,大批量的数据操作可能会影响源系统。
数据入湖有以下5种主要技术手段。
批量集成(Bulk/Batch Data Movement)
对于需要进行复杂数据清理和转换且数据量较大的场景,批量集成是首选。通常,调度作业每小时或每天执行,主要包含ETL、ELT和FTP等工具。批量集成不适合低数据延迟和高灵活性的场景。
数据复制同步(Data Replication/Data Synchronization)
适用于需要高可用性和对数据源影响小的场景。使用基于日志的CDC捕获数据变更,实时获取数据。数据复制同步不适合处理各种数据结构以及需要清理和转换复杂数据的场景。
消息集成(Message-Oriented Movement of Data)
通常通过API捕获或提取数据,适用于处理不同数据结构以及需要高可靠性和复杂转换的场景。尤其对于许多遗留系统、ERP和SaaS来说,消息集成是唯一的选择。消息集成不适合处理大量数据的场景。
流集成(Stream Data Integration)
主要关注流数据的采集和处理,满足数据实时集成需求,处理每秒数万甚至数十万个事件流,有时甚至数以百万计的事件流。流集成不适合需要复杂数据清理和转换的场景。
数据虚拟化(Data Virtualization)
对于需要低数据延迟、高灵活性和临时模式(不断变化下的模式)的消费场景,数据虚拟化是一个很好的选择。在数据虚拟化的基础上,通过共享数据访问层,分离数据源和数据湖,减少数据源变更带来的影响,同时支持数据实时消费。数据虚拟化不适合需要处理大量数据的场景。
5种数据入湖方式的对比可以参考表。
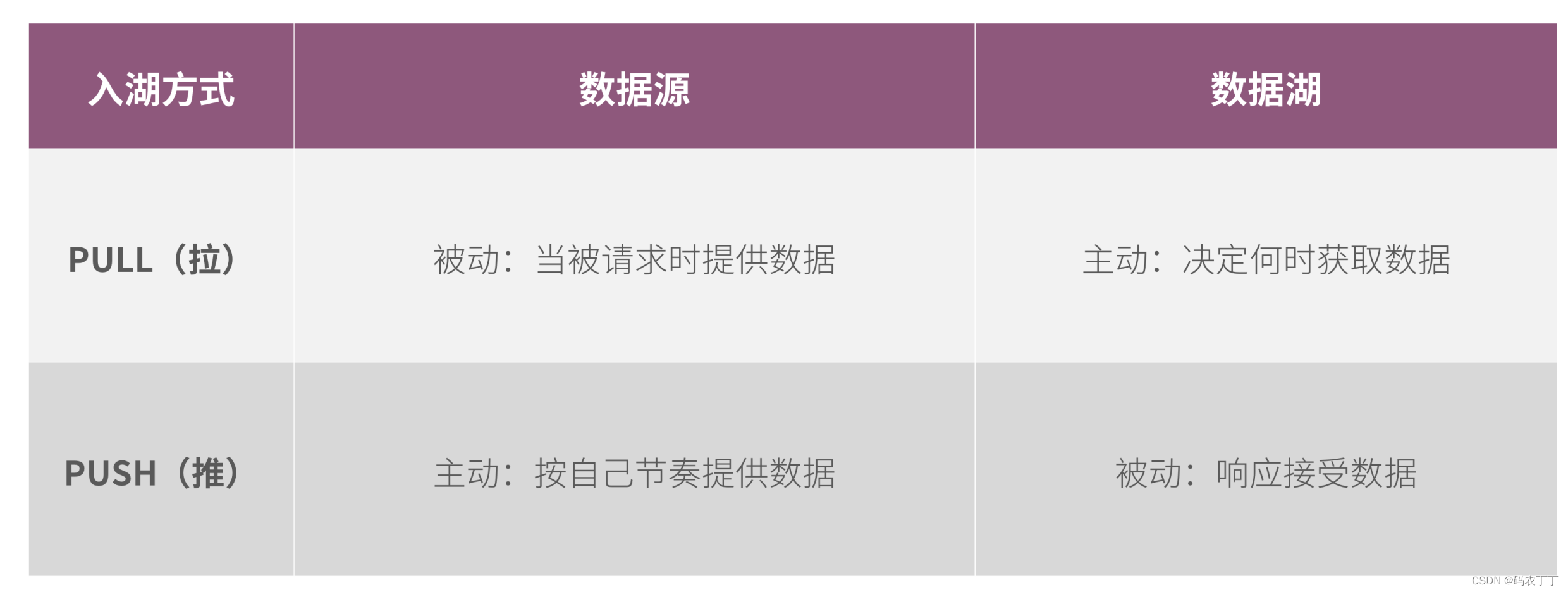
可以通过数据湖主动从数据源PULL(拉)的方式入湖,也可以通过数据源主动向数据湖PUSH(推)的方式入湖。数据复制同步、数据虚拟化以及传统ETL批量集成都属于数据湖主动拉的方式;流集成、消息集成属于数据源主动推送的方式。在特定的批量集成场景下,数据会以CSV、XML等格式,通过FTP推送给数据湖。
这篇关于【华为数据之道学习笔记】5-4 数据入湖方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




