本文主要是介绍redis:四、双写一致性的原理和解决方案(延时双删、分布式锁、异步通知MQ/canal)、面试回答模板,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
双写一致性
场景导入
如果现在有个数据要更新,是先删除缓存,还是先操作数据库呢?当多个线程同时进行访问数据的操作,又是什么情况呢?
以先删除缓存,再操作数据库为例
多个线程运行的正常的流程应该如下:
线程1先访问数据,它首先删除缓存,然后更新数据库。之后线程2来查询缓存,未命中后查询数据库,随后写入缓存。
也就是说,线程1负责删除缓存并更新数据库,线程2负责查询数据库并写入缓存。
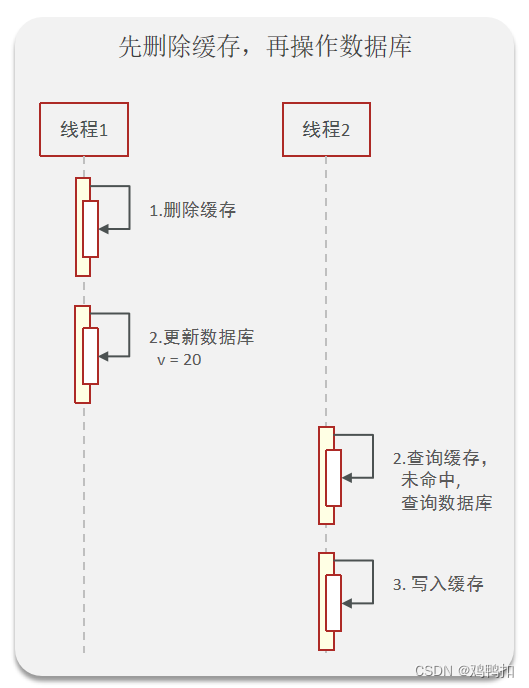
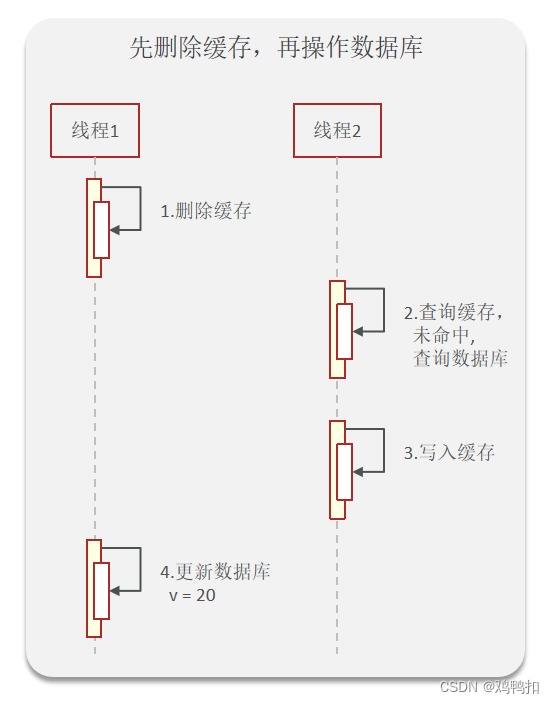
但如果线程2在线程1还未更新数据库的时候,就查询数据库了,那么就会出问题。
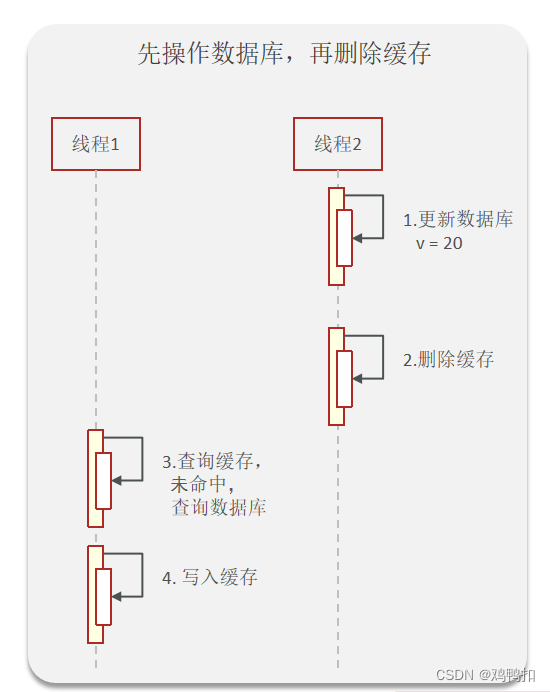
以先操作数据库,再删除缓存为例。
正常流程应该如下:
线程2负责更新数据库并删除缓存。线程1负责查询数据库,并写入缓存。
其实也可以说
线程1负责更新数据库并删除缓存。线程2负责查询数据库,并写入缓存。
我把上面的“以先删除缓存,再操作数据库为例”搬过来了,可以对比一下。
也就是说,线程1负责删除缓存并更新数据库,线程2负责查询数据库并写入缓存。
发现就是前半部分顺序颠倒了而已。
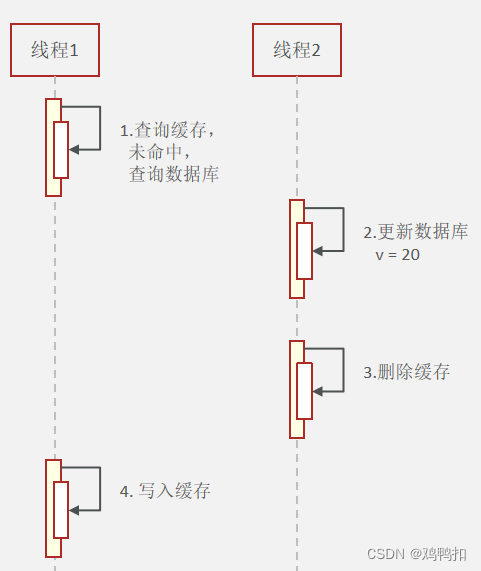
同样的,
但如果线程1在线程2还更新数据库的时候,就查询数据库了,那么就会出问题。
我同样把上面的异常情况搬过来对比。
但如果线程2在线程1还未更新数据库的时候,就查询数据库了,那么就会出问题。
定义
当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
解决方案
能保障强一致性:延时双删、分布式锁
不能保障强一致性,只能保障最终的一致性:异步通知
延时双删(强一致性)
延时双删就是正常删除缓存、修改数据库后还要延时一会再次删除缓存。

因为从上面的场景导入,我们发现,无论是先删除缓存还是先修改数据库,都会有数据不一致,即脏数据的风险。
再次把先删除缓存,再修改数据库的异常流程图拿过来,我们发现整个流程走完后,线程1更新数据库,拿到的是正确的值。而线程2拿到的是错误的值,这时只要我们以数据库为主,删除缓存,再写入数据库的值,那么就能拿到正确的值。
此外,延时一会是因为一般数据库都是主从分离,读写分离的。延时是为了让主库有时间通知到从库,所有数据库的更新操作全部走完。
延时双删极大程度上避免了脏数据的风险,但因为有延时的存在,延时时间不好控制,所以也不能说百分百避免。
分布式锁(强一致性)
互斥锁
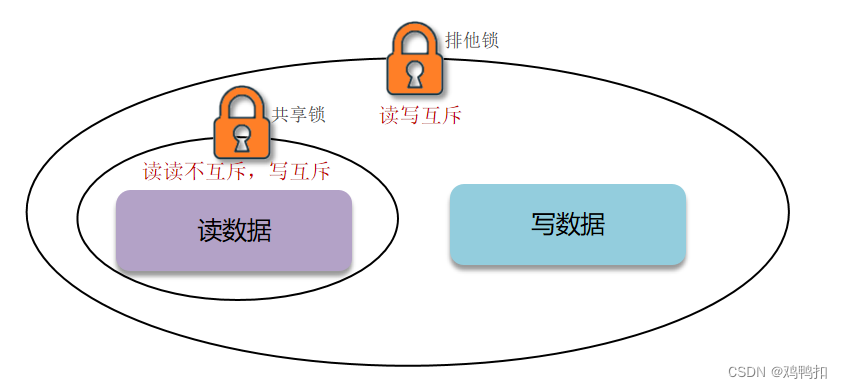
直接加互斥锁能保障数据的强一致性,但是性能较低。此时我们就需要优化一下互斥锁。因为存入缓存的数据,一般都是读多写少。为此我们引入两个单独的锁,分别叫共享锁和排他锁。
共享锁/读锁
共享锁,又叫读锁(readLock),加锁之后,其他线程可以共享读操作。
排他锁/独占锁
排他锁,又叫独占锁(writeLock),加锁之后,阻塞其他线程读和写操作。
混合使用的流程和代码
我们想要拿到共享锁或者排他锁,都需要先拿到读写锁。
通过固定代码可以拿到读写锁。
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");
随后分别拿到共享锁和排他锁。(注意两个锁需要是同一把读写锁)
RLock readLock = readWriteLock.readLock();
RLock writeLock = readWriteLock.writeLock();
读操作的代码
public void getById(Integer id){RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");RLock readLock = readWriteLock.readLock();try{readLock.lock();System.out.println("readLock...");Item item = (Item) redisTemplate.opsForValue().get("item"+id);if(item != null){return item;}item = new Item(id, "华为手机", "华为手机", 5999.00);redisTemplate.opsForValue().set("item"+id, item);return item;}finally{readLock.unlock();}
}
写操作的代码
public void updateById(Integer id){RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("ITEM_READ_WRITE_LOCK");RLock writeLock = readWriteLock.writeLock();try{writeLock.lock();System.out.println("writeLock...");Item item = new Item(id, "华为手机", "华为手机", 5299.00);try{Thread.sleep(10000);}catch(InterruptedException e){e.printStackTrace();}redisTemplate.delete("item"+id);}finally{writeLock.unlock();}
}
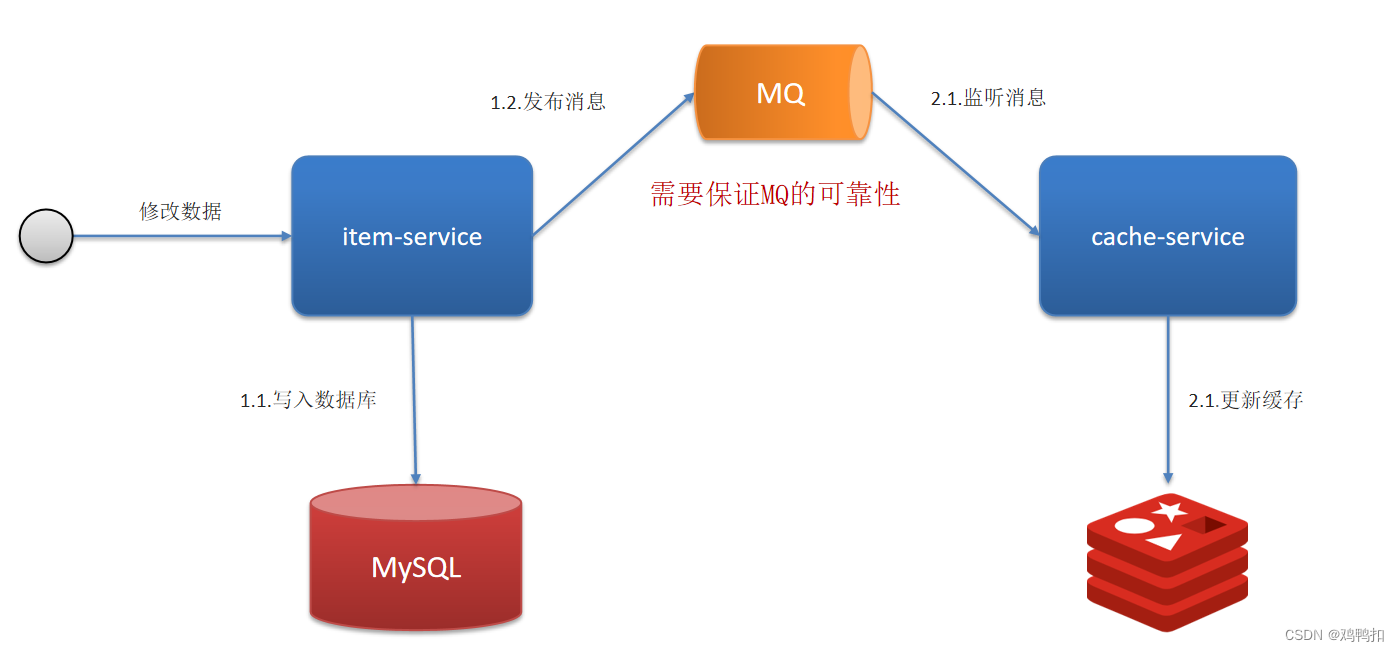
异步通知
异步通知的也有两个主流方案:MQ、Canal
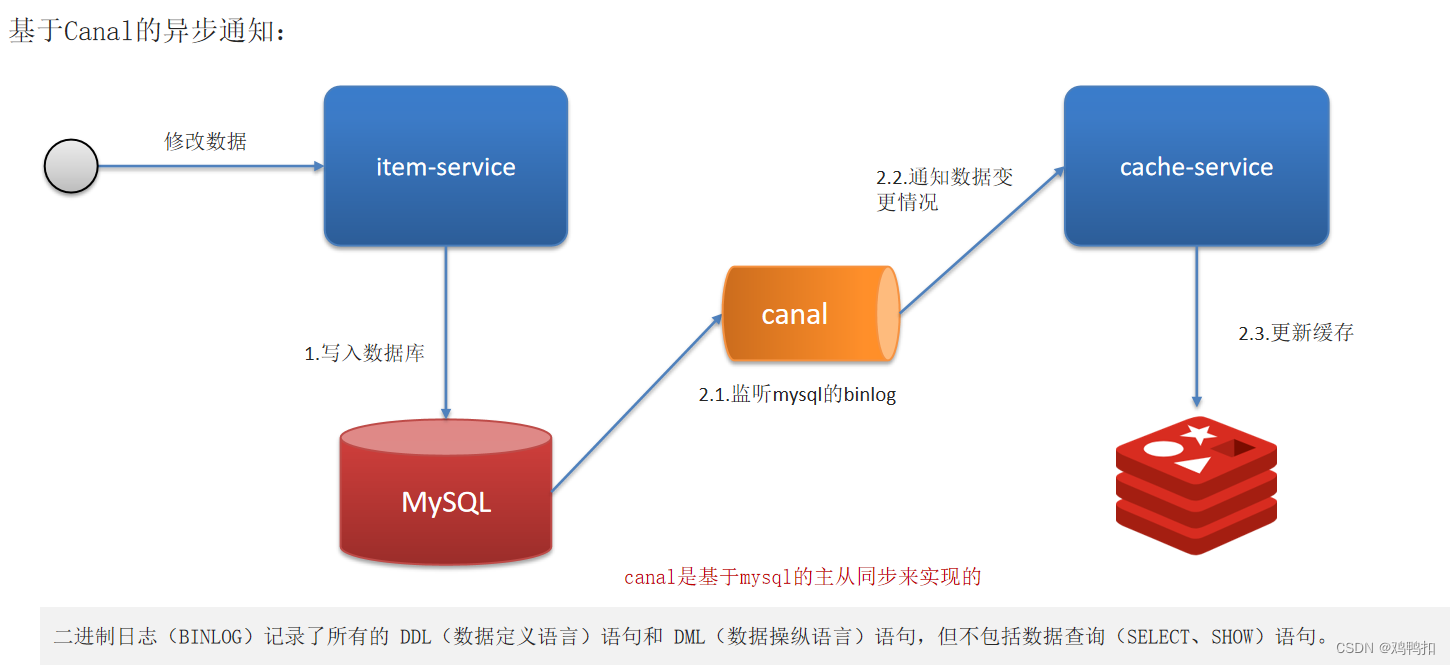
canal的方案对于业务代码几乎是零侵入的。
面试回答模板
redis为缓存,mysql的数据如何与redis进行同步呢?
背熟以下回答,大概用时1min。
这个要看业务需求,如果要求数据的强一致性,那么一般使用读写锁来实现。读写锁是一种分布式锁机制,里面包括两种锁,一个叫共享锁,在读的时候添加共享锁,可以保证读读不互斥,读写互斥。一个叫排他锁,在写的时候添加排他锁,可以保证读写都互斥,避免脏数据的风险。
如果不要求数据的强一致性,那么就可以用基于MQ或者canal中间件的异步通知,来实现redis和mysql的双写一致性。
你的项目中用到了redis,那你mysql的数据如何与redis进行同步呢?
——————————————强一致性策略——————————————————
以我最近做的这个项目为例,里面有xxxx(根据自己的简历上写)的功能,需要让数据库与redis高度保持一致,因为要求时效性比较高,我们当时采用的读写锁保证的强一致性。
读写锁是一种分布式锁机制,里面包括两种锁,一个叫共享锁,在读的时候添加共享锁,可以保证读读不互斥,读写互斥。一个叫排他锁,在写的时候添加排他锁,可以保证读写都互斥,避免脏数据的风险。这里面需要注意的是读方法和写方法上需要使用同一把锁才行。
面试官:那这个排他锁是如何保证读写、读读互斥的呢?
候选人:其实排他锁底层使用也是setnx,保证了同时只能有一个线程操作锁住的方法
面试官:你听说过延时双删吗?为什么不用它呢?
候选人:延迟双删,如果是写操作,我们先把缓存中的数据删除,然后更新数据库,最后再延时删除缓存中的数据,其中这个延时多久不太好确定,在延时的过程中可能会出现脏数据,并不能保证强一致性,所以没有采用它。
——————————————非强一致性策略——————————————————
面试官:redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
候选人:嗯!就说我最近做的这个项目,里面有xxxx(根据自己的简历上写)的功能,数据同步可以有一定的延时(符合大部分业务)
我们当时采用的阿里的canal组件实现数据同步:不需要更改业务代码,部署一个canal服务。canal服务把自己伪装成mysql的一个从节点,当mysql数据更新以后,canal会读取binlog数据,然后在通过canal的客户端获取到数据,更新缓存即可。
这篇关于redis:四、双写一致性的原理和解决方案(延时双删、分布式锁、异步通知MQ/canal)、面试回答模板的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









