本文主要是介绍以csv为源 flink 创建paimon 临时表相关 join 操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 概述
- 配置
- 关键配置
- 测试
- 启动 kyuubi
- 执行配置中的命令
- bug解决
- bug01
- bug02
- 结束
概述
目标:生产中有需要外部源数据做paimon的数据源,生成临时表,以使用与现有正式表做相关统计及 join 操作。
环境:各组件版本如下
- kyuubi 1.8.0
- flink 1.17.1
- paimon 0.5 正式版本
- hive 3.1.3
阅读此文前,需涉及前置的知识点如下
- kyuubi整合flink yarn application model
配置
概述:临时表 paimon 此版本仅 Flink支持。与外部表一样,临时表只是记录的,而不是由当前Flink SQL会话管理的。如果删除临时表,则不会删除其资源。当 Flink SQL 会话关闭时,临时表也会被丢弃。
如果您想将 Paimon catalog与其他表一起使用,但不想将它们存储在其他的 catalog 中,可以创建一个临时表。下面的关键配置 Flink SQL 创建了一个 Paimon catalog 和一个临时表,并进行了测试。
关键配置
来看一些关键配置,其它配置如有疑问,请参考 kyuubi整合flink yarn application model
CREATE CATALOG paimon_hive WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://10.xx.xx.22:9083','warehouse' = 'hdfs:///data/hive/warehouse/paimon','default-database'='tmp'
);CREATE TEMPORARY TABLE test (UnitId STRING,WorkOrder STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs:///data/hive/warehouse/tmp/Small.csv','format' = 'csv'
);SET execution.runtime-mode=batch;select * from test;
使用的 csv 文件如下,学习时,可以自己创建测试内容

测试
启动 kyuubi

执行配置中的命令
执行配置中的命令,几条命令依次执行如下图:
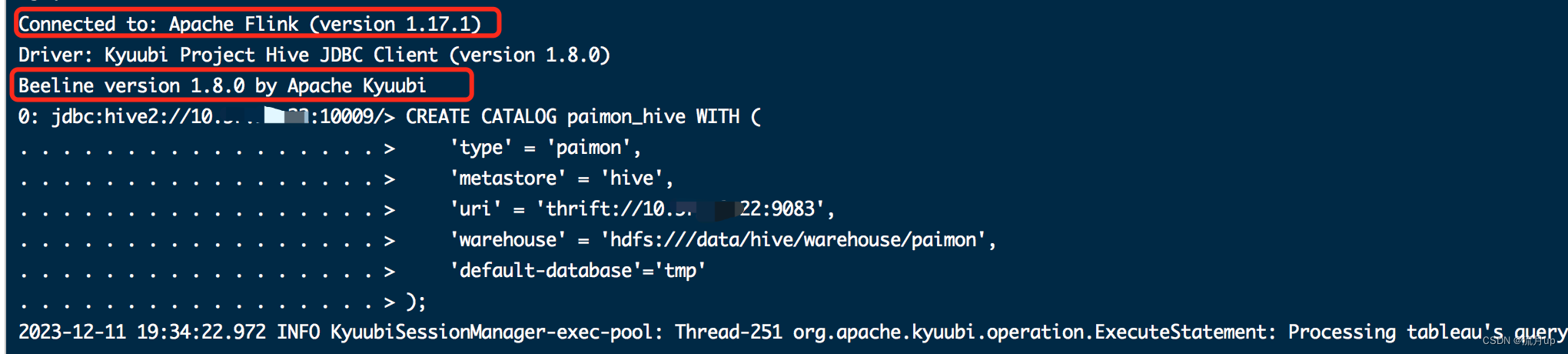
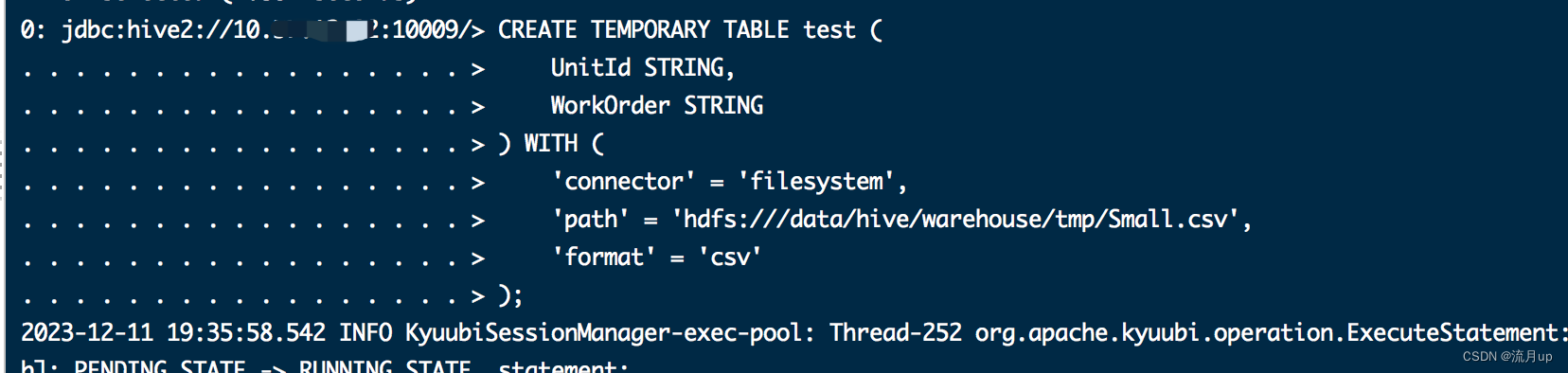


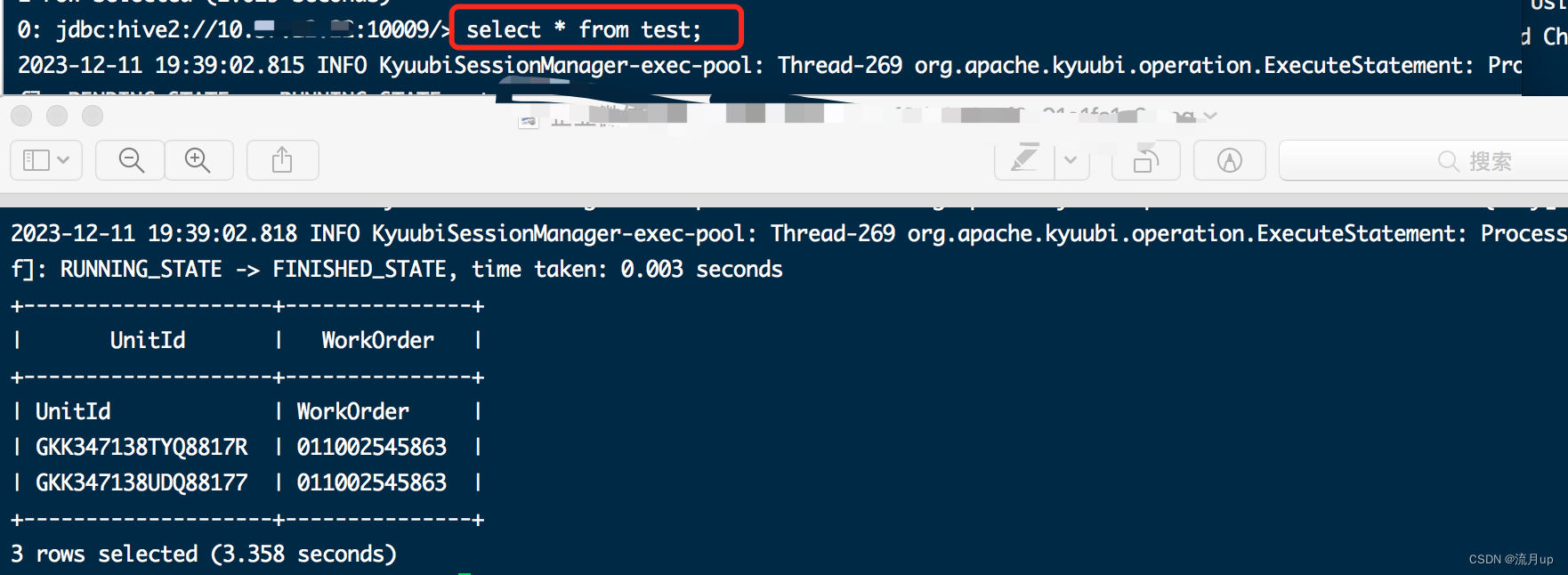
bug解决
坑随时都有,下面解决一下测试过程的bug。
bug01
来图如下:
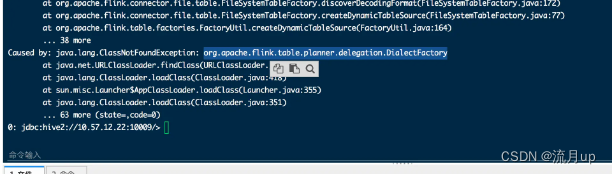
一看缺失类,老套路,看看是哪个包下的,添加至 flink 1.17.1 下面的 lib 下。

bug02
重新启动时,报有重复类,冲突了
这个以前解决过,直接上解决方案。如下图:

这两个解决之后,就按上文中 测试 流程走就可以了。
结束
以csv为源 flink 创建paimon 临时表相关 join 操作 ,至此就结束了。如有疑问,欢迎评论区留言。
这篇关于以csv为源 flink 创建paimon 临时表相关 join 操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







