本文主要是介绍Elasitcsearch--解决CPU使用率升高,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文网址:Elasitcsearch--解决CPU使用率升高_IT利刃出鞘的博客-CSDN博客
简介
本文介绍如何解决ES导致的CPU使用率升高的问题。
问题描述
线上环境 Elasticsearch CPU 使用率飙升常见问题如下:

Elasticsearch 使用线程池来管理并发操作的 CPU 资源。Elasticsearch 高 CPU 使用率通常意味着一个或多个线程池不足以支撑业务需求。如果线程池资源耗尽,Elasticsearch 将拒绝与线程池相关的请求。
例如,如果搜索线程池(search thread pool)耗尽,Elasticsearch 将拒绝搜索请求,直到有更多线程可用。
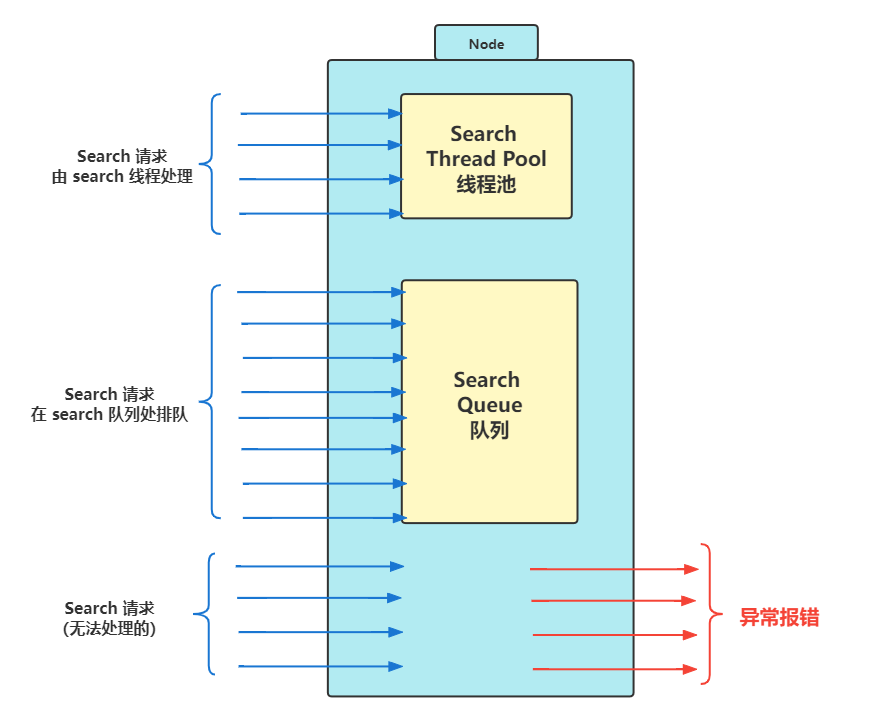
上图更直观的解释了线程池、队列、客户端请求之间的关系,拿检索线程为例:
- 当请求比较少时,线程池完全可以处理过来;
- 当前再多一些时,需要线程池队列排队;
- 如果请求再多,就超出了线程池和队列的最大负载,导致异常报错。
排查 ES 高 CPU 使用率
核查 CPU 使用率
使用 cat nodes API 获取每个节点的当前 CPU 使用率。
GET _cat/nodes?v=true&s=cpu:desc
返回结果:

如上所示,CPU 即为CPU使用率,name为节点的名称。
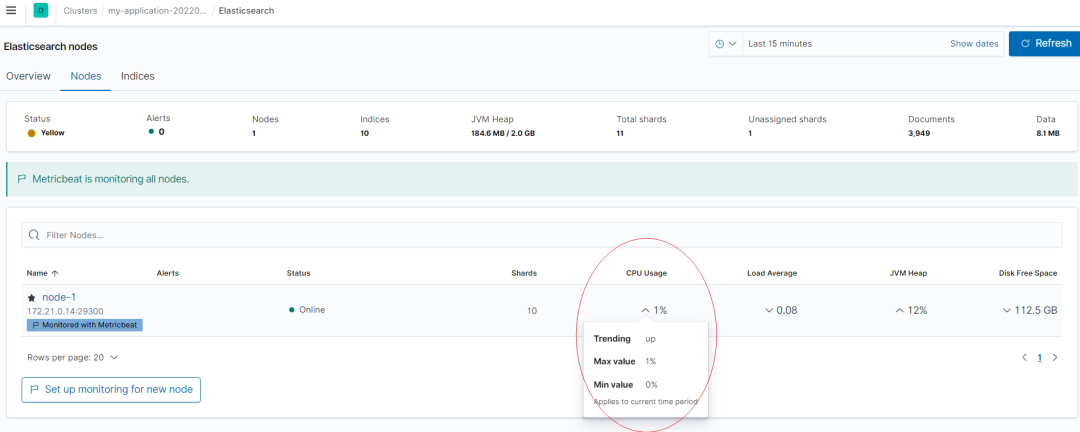
也可以借助 Kibana Stack Monitoring 进行可视化监控,CPU 监控如下红圈所示:
核查热点线程
如果某个节点的 CPU 使用率很高,请使用节点热点线程 API 检查该节点上运行的资源密集型线程。
GET _nodes/my-node,my-other-node/hot_threads
此 API 以纯文本形式返回任何热点线程的细节。
降低 CPU 使用率的方案
1. 扩展集群
繁重的数据写入(indexing)和搜索负载会耗尽较小的线程池。
为了更好地处理繁重的工作负载,向集群添加更多节点或升级(扩容)现有节点以增加容量。
2. 分散批量请求
批量请求虽然比单个请求效率更高,但大型批量写入或多搜索请求需要大量 CPU 资源。
如果可能,提交较小的请求并在它们之间留出更多时间。
这里的较小有多小?需要结合业务实际、结合线程池和队列大小不断调出最优值。
3.取消长时间运行的搜索
长时间运行的搜索会阻塞搜索线程池中的线程。
要检查这些搜索,请使用任务管理 API。
GET _tasks?actions=*search&detailed
上述命令行的响应包含检索请求及其查询细节,其中:running_time_in_nanos 显示搜索运行了多长时间。
{"nodes" : {"oTUltX4IQMOUUVeiohTt8A" : {"name" : "my-node","transport_address" : "127.0.0.1:9300","host" : "127.0.0.1","ip" : "127.0.0.1:9300","tasks" : {"oTUltX4IQMOUUVeiohTt8A:464" : {"node" : "oTUltX4IQMOUUVeiohTt8A","id" : 464,"type" : "transport","action" : "indices:data/read/search","description" : "indices[my-index], search_type[QUERY_THEN_FETCH], source[{\"query\":...}]","start_time_in_millis" : 4081771730000,"running_time_in_nanos" : 13991383,"cancellable" : true}}}}
}
可以使用 _cancel API 取消任务以释放资源:
POST _tasks/oTUltX4IQMOUUVeiohTt8A:464/_cancel
4.避免耗费资源的搜索
举例:前缀匹配的 wildcard 查询、多重聚合或分桶设置过大的单重聚合都会非常耗费资源。
避免策略包含但不限于:
- 避免脚本 script 检索。
- 少使用:fuzzy、regexp、prefix、wildcard检索
- 避免将 range 检索应用到 text 和 keyword 类型。
- 避免多表关联 Join 类型。
- 使用 index.max_result_window 索引设置降低大小限制。
- 使用 search.max_buckets 集群设置降低允许的聚合桶的最大数量。
- 使用 search.allow_expensive_queries 集群设置禁用耗费资源的查询。
这篇关于Elasitcsearch--解决CPU使用率升高的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







