本文主要是介绍基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(一)——创建Glue,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 通过Athena查询s3中的数据
此实验使用s3作为数据源
ETL:
E extract 输入
T transform 转换
L load 输出
大纲
- 1 通过Athena查询s3中的数据
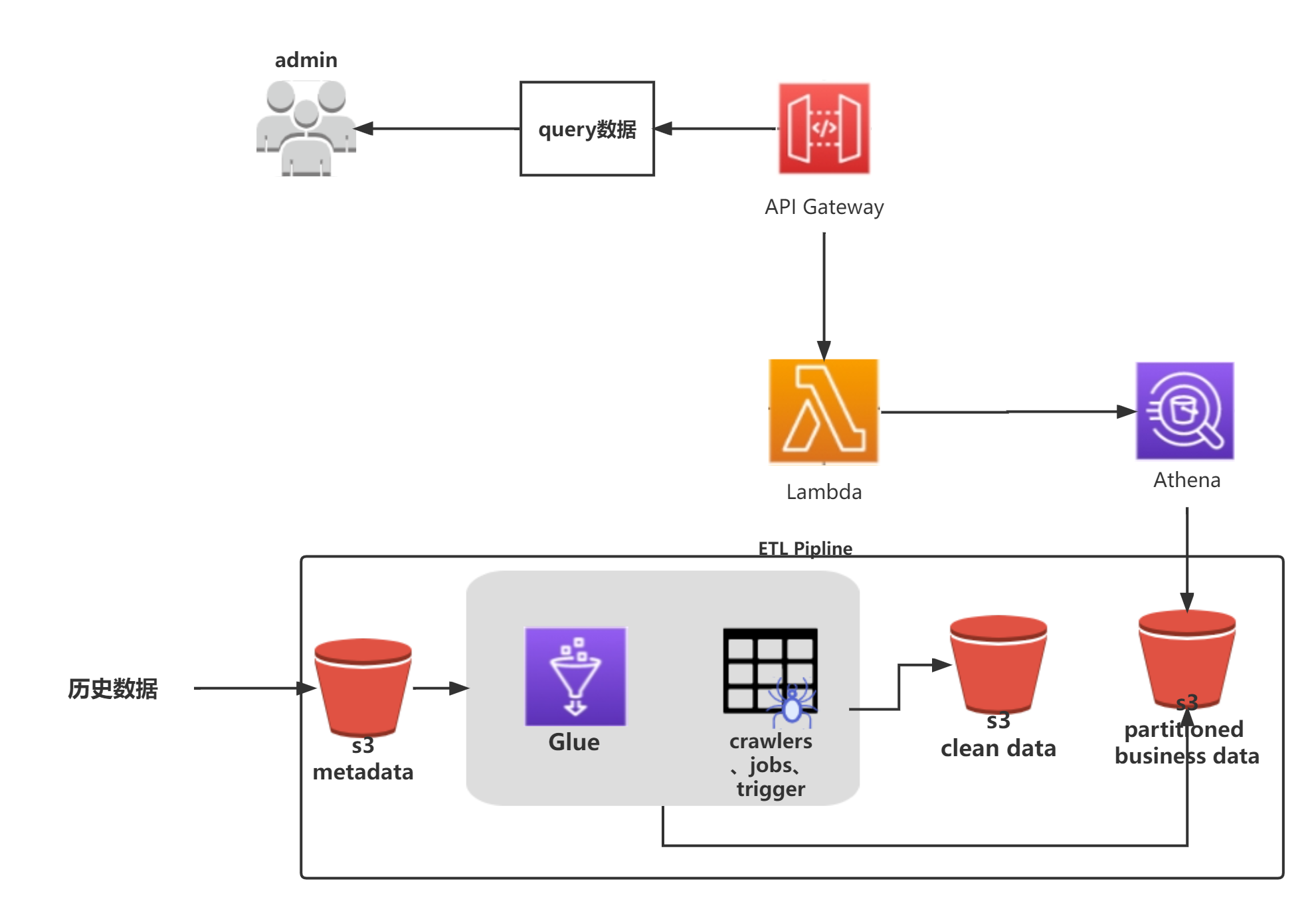
- 1.1 架构图
- 1.2 创建Glue数据库
- 1.3 创建爬网程序
- 1.4 创建表
- 1.4.1 爬网程序创建表
- 1.4.2 手动创建表
- 1.5 Athena查询
- 1.6 总结
1.1 架构图
1.2 创建Glue数据库
首先我们需要创建一个数据库。我们将会使用爬网程序来填充我们的数据目录。
| 步骤 | 图例 |
|---|---|
| 1、入口 |  |
| 2、创建数据库 只需输入一个数据库名称即可 | 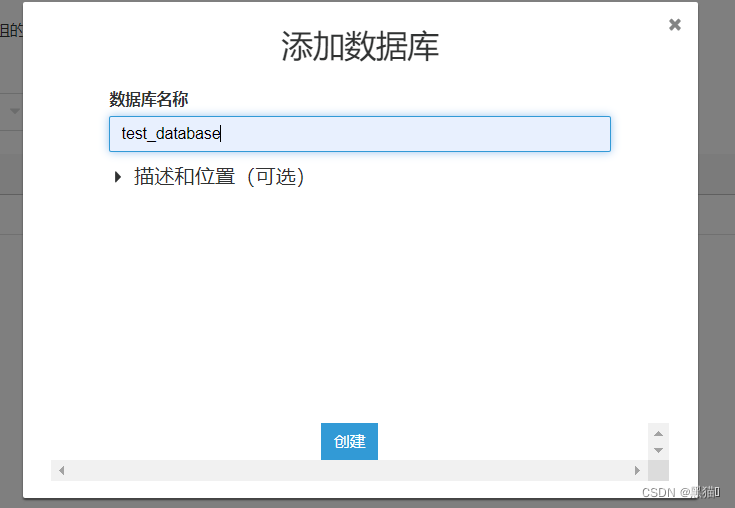 |
| 3、结果 |  |
1.3 创建爬网程序
在任务中,我们经常会使用Glue爬网程序来填充我们的数据目录。
爬虫可以在一次运行中爬取多个数据存储。在爬取完成后,我们会在数据目录中看到由爬虫创建的一个或多个表。
创建表后,我们就可以在接下来的Athena查询或ETL作业中使用表来作为源或目标了。
| 步骤 | 图例 |
|---|---|
| 1、入口 | 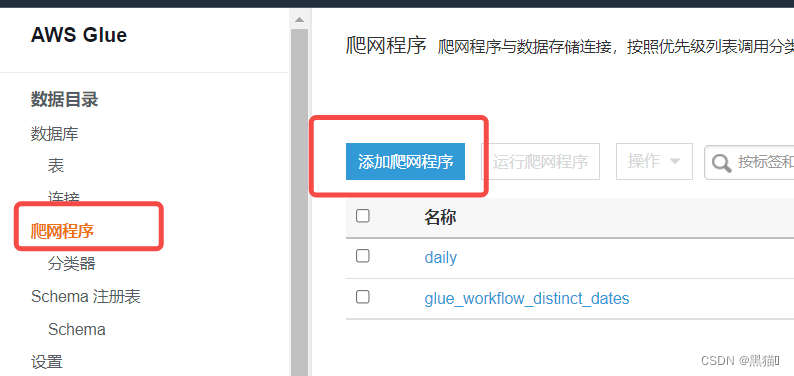 |
| 2、输入爬虫名称 | 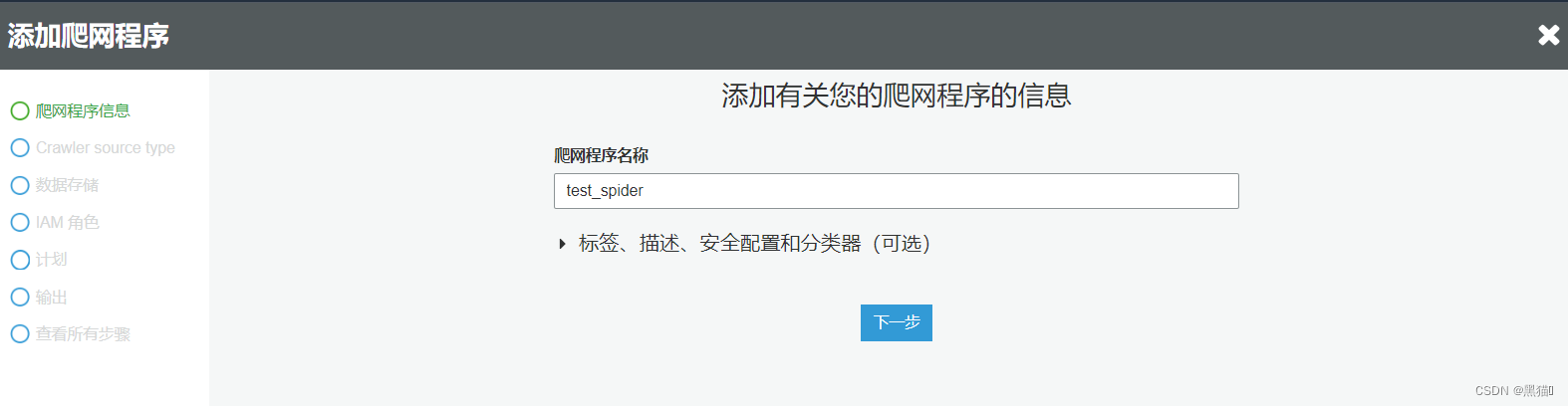 |
| 3、选择数据源类型(Data Stores:创建,Existing catalog tables:更新) 选择爬取类型(Crawl all folders:爬取全部文件夹,Crawl new folders only:只爬取新文件夹,Crawl changed folders indentified by Amazon S3 Event Notifications:只爬取S3事件通知的有变更的文件夹) | 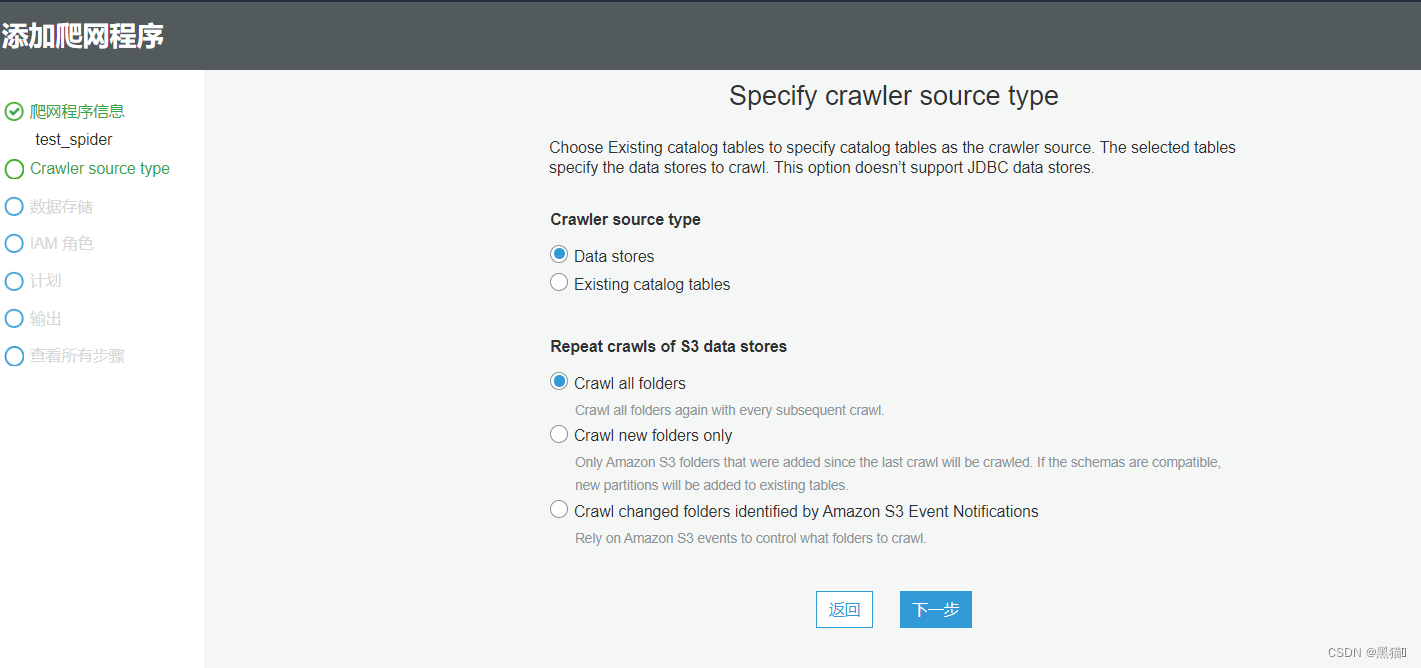 |
| 4、选择s3 (可对s3中的需要爬取的数据进行筛选) | 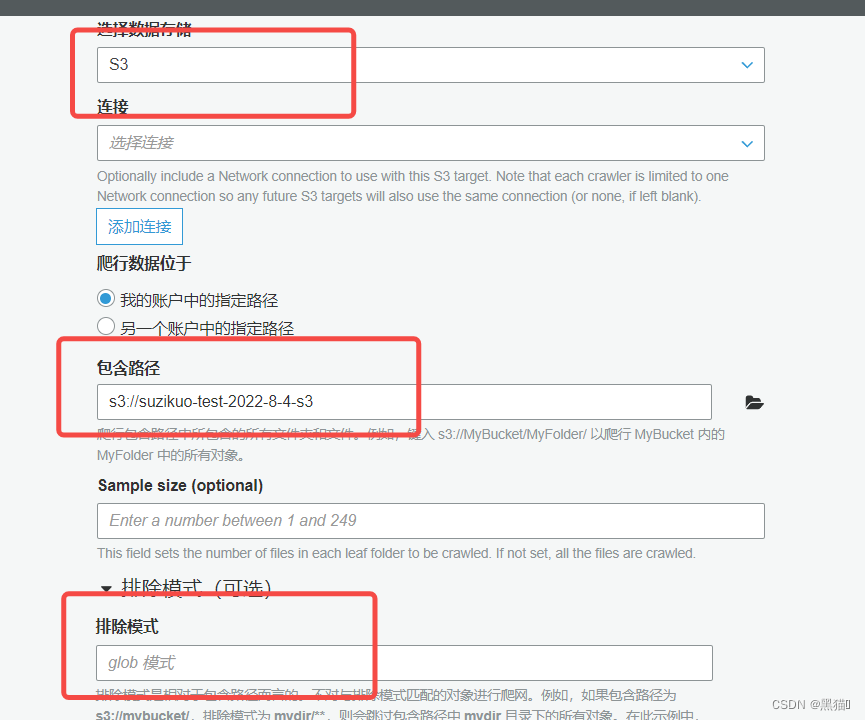 |
| 5、创建或选择爬网程序IAM角色(需要有对应S3与Glue的权限) | 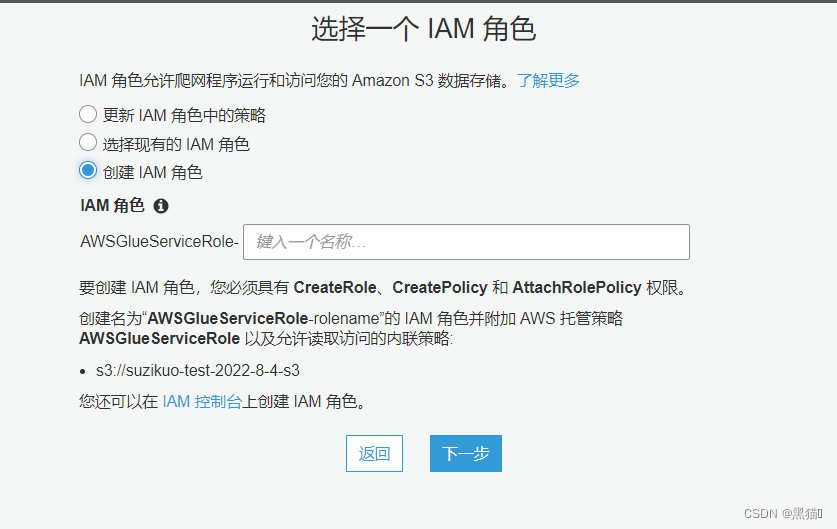 |
| 6、对于不确定的实时数据或许要定时更新的数据,可按需选择频率;若只需创建表结构,可选择按需运行 | 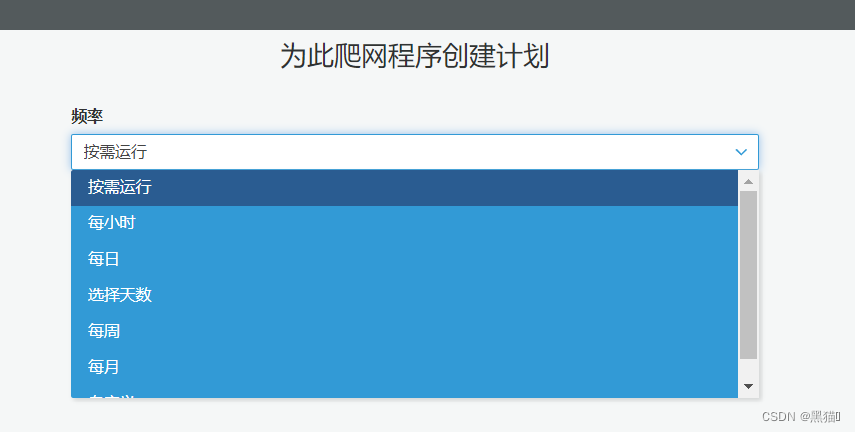 |
| 7、确认 |  |
此时,数据库与爬网程序已准备完毕。
我们将会运行爬网程序自动分析数据结构并创建表。
1.4 创建表
如果对待爬取数据结构未知,或者结构复杂、字段繁杂,则使用“爬网程序创建表”;对于对待爬取数据结构清晰明了的,可以使用“手动创建表”模式。
1.4.1 爬网程序创建表
| 步骤 | 图例 |
|---|---|
| 1、运行 |  |
| 2、运行中 | 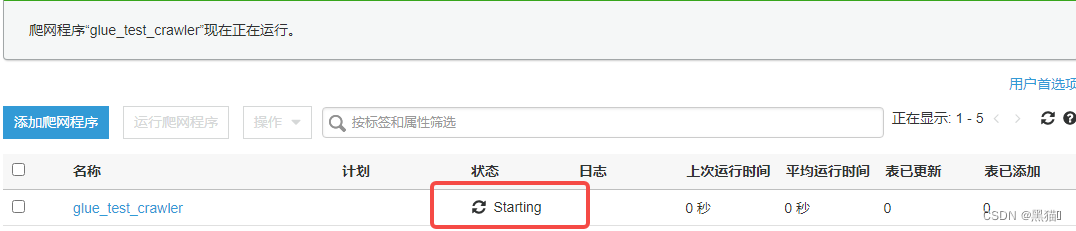 |
| 3、运行完毕 |  |
| 4、运行结果 | 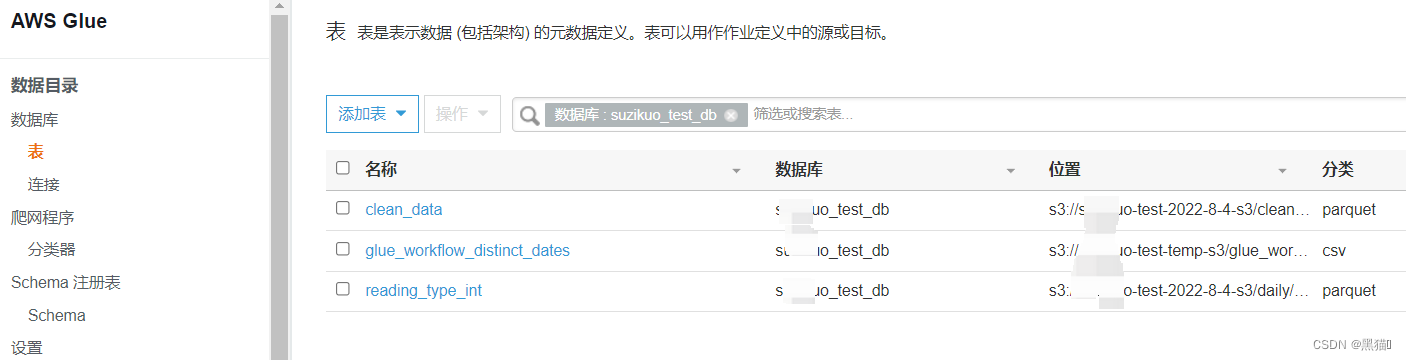 |
| 5、表结构 | 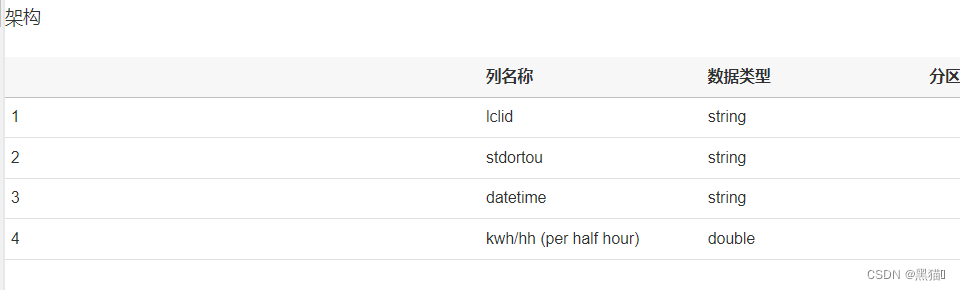 |
1.4.2 手动创建表
| 步骤 | 图例 |
|---|---|
| 1、入口 | 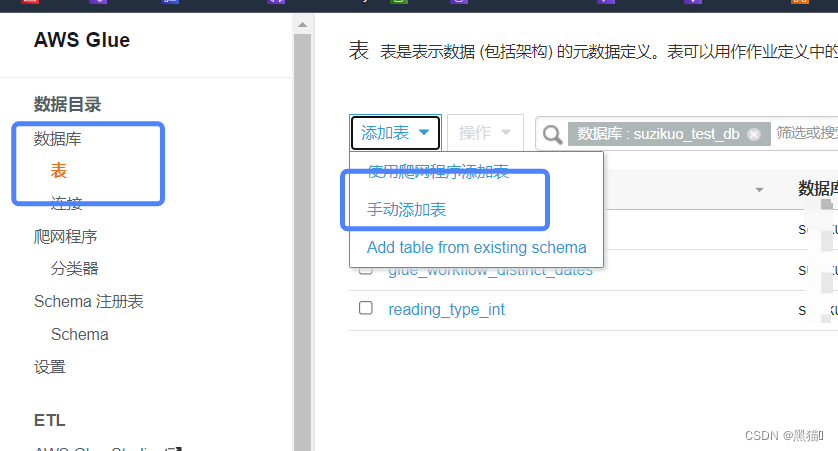 |
| 2、表名 | 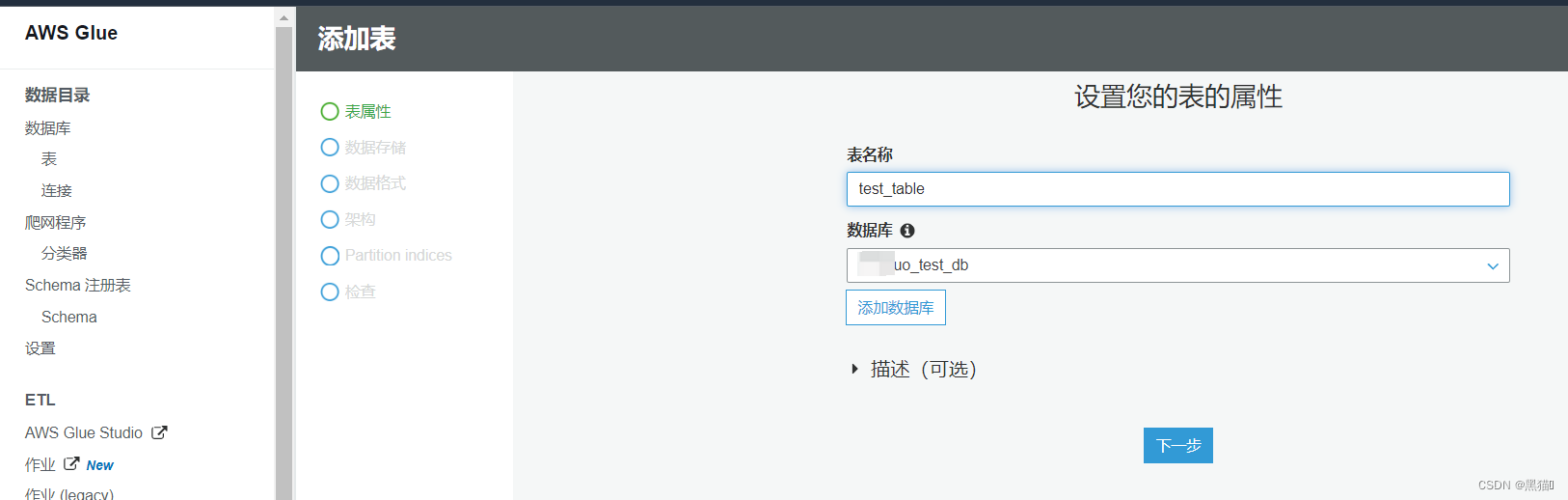 |
| 3、数据源 | 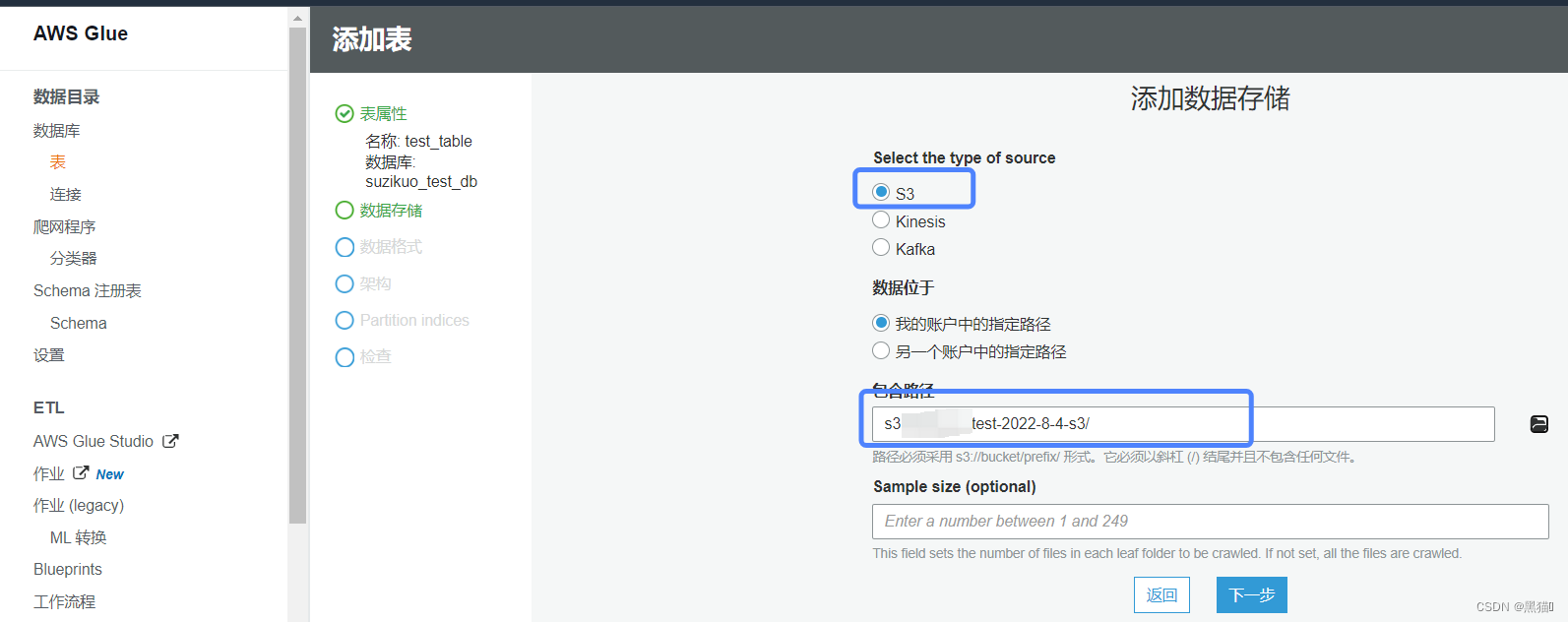 |
| 4、选择文件类型 | 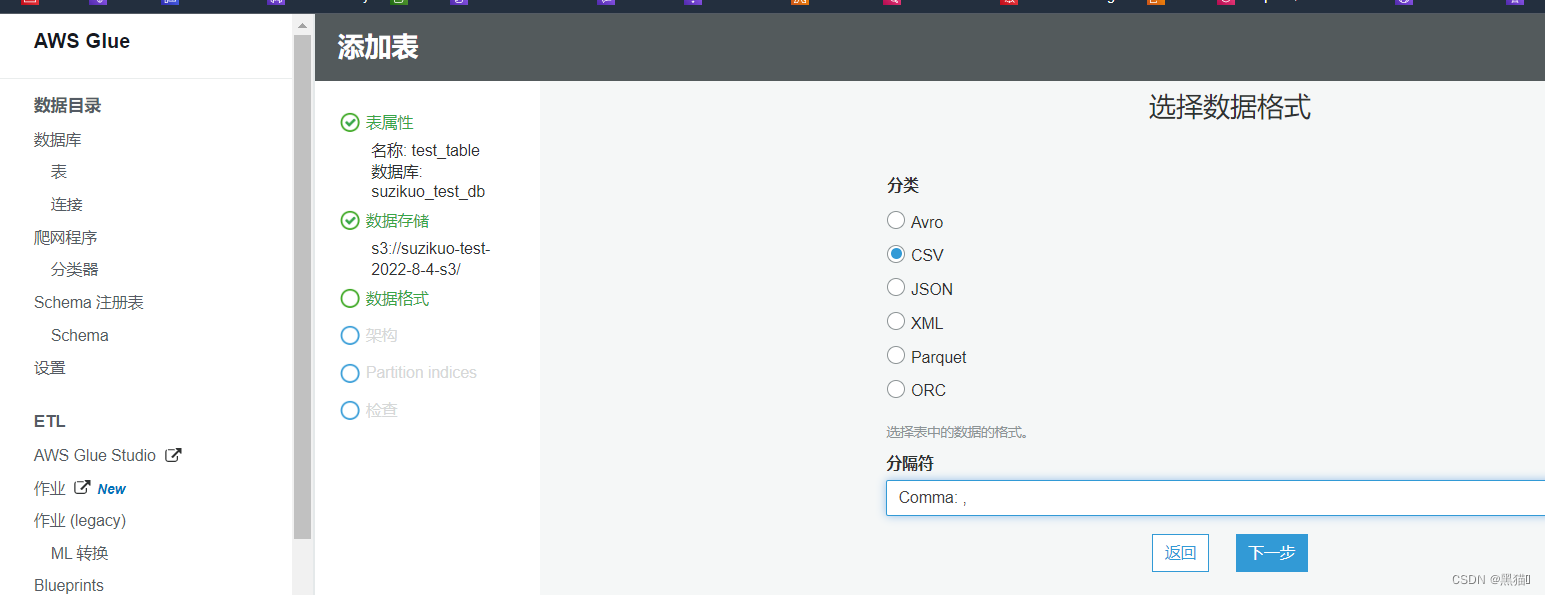 |
| 5、手动创建表需要自定义列;请根据提示创建 | 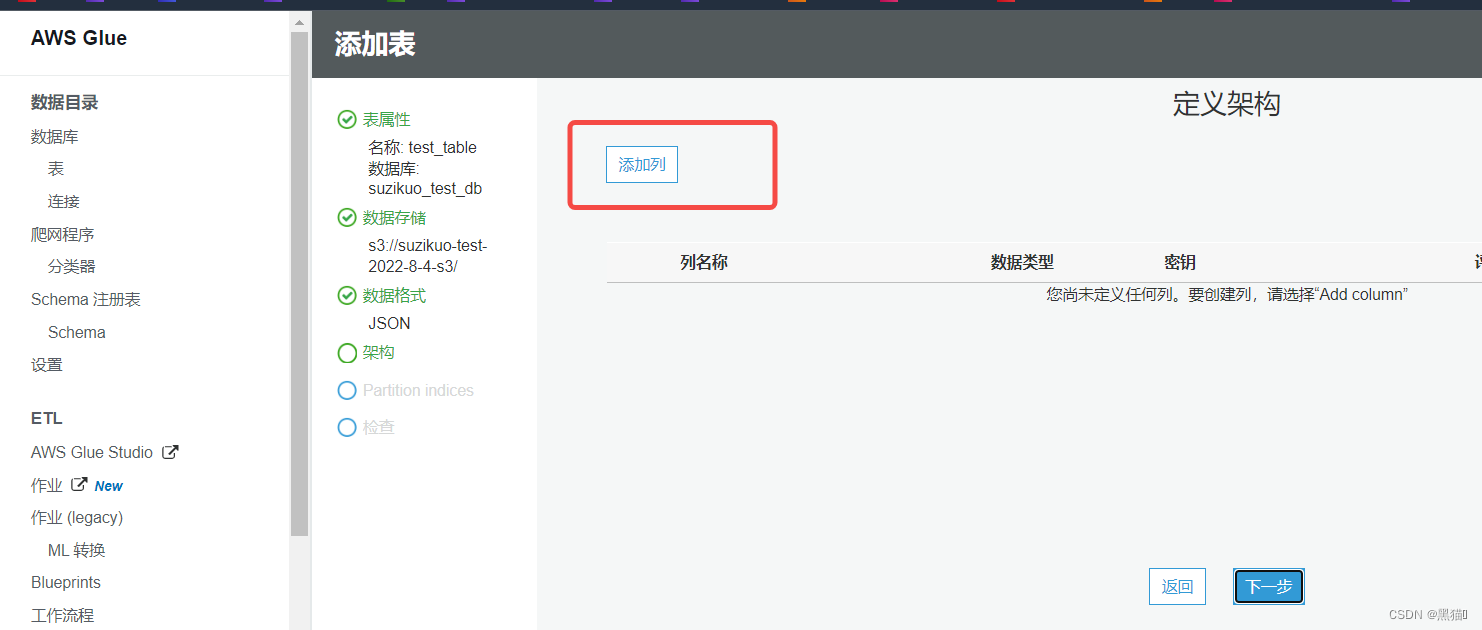 |
| 6、一直下一步即可 |
1.5 Athena查询
Athena是一种交互式查询服务(不是数据库)。并且Athena可以使用标准SQL直接查询S3中的数据,前提是需要使用Glue连接S3源。Athena还支持查询如DynamoDB、Redshift、MySQL等数据库。
| 步骤 | 图例 |
|---|---|
| 1、入口 | 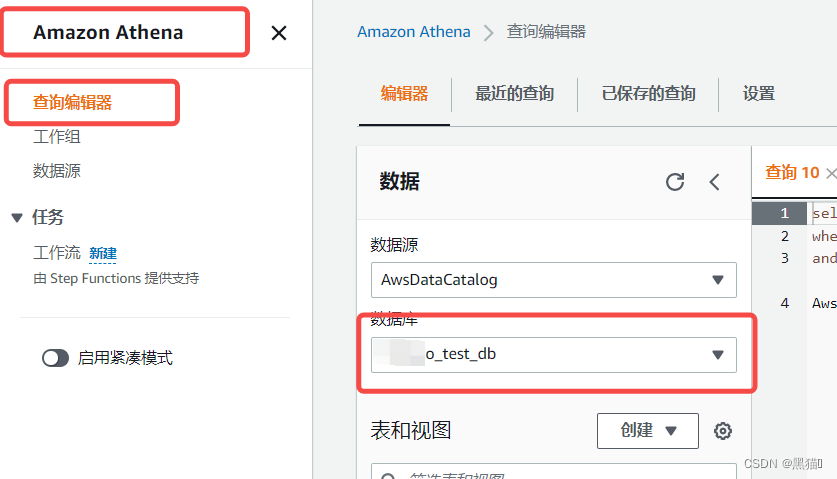 |
| 2、设置查询结果存储位置:s3 | 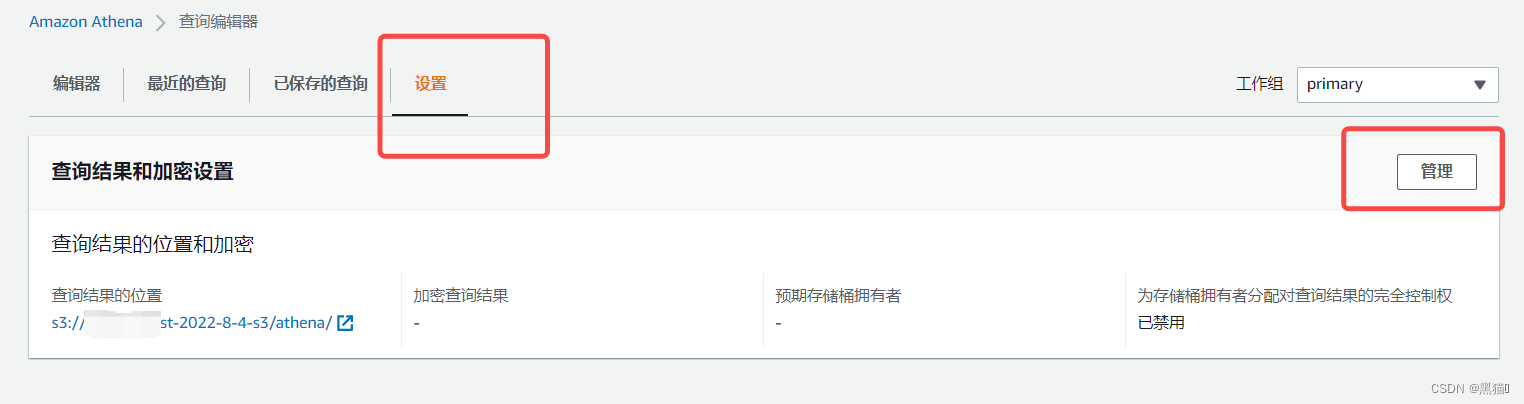 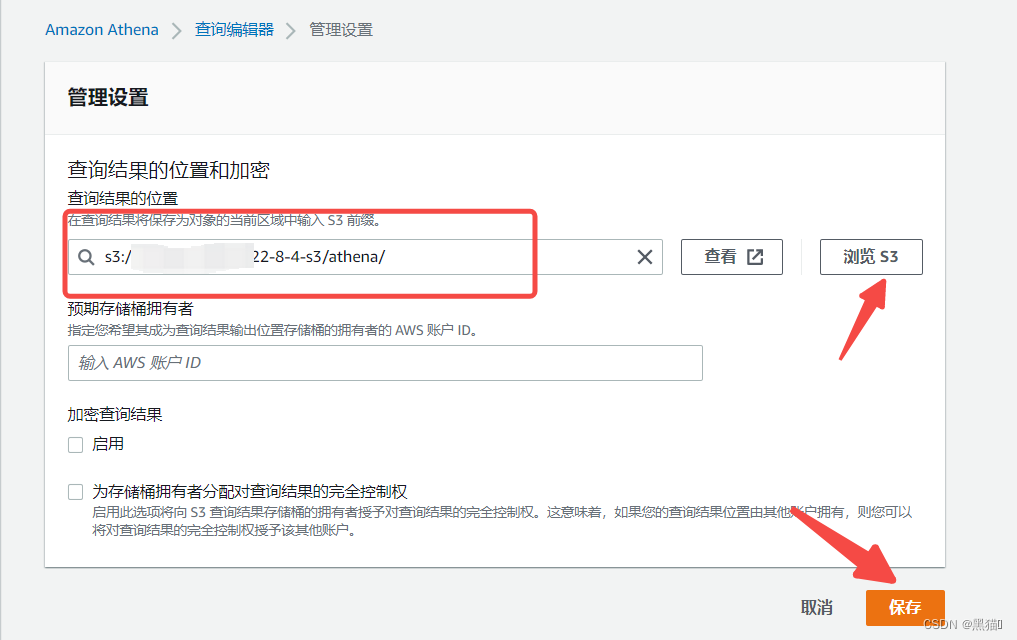 |
| 3、查看表,可查看数据库以及其中的表 | 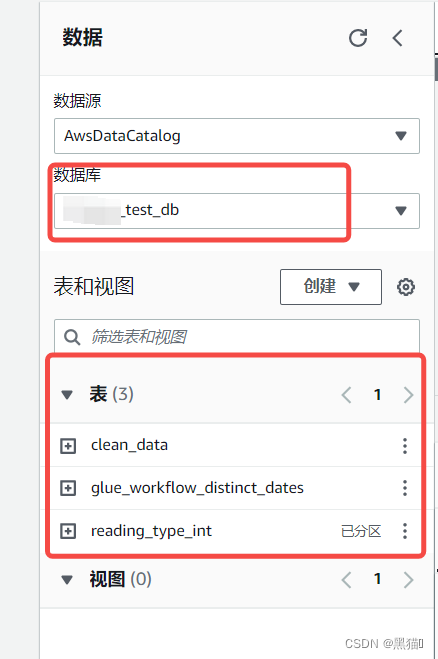 |
| 4、查询结果:使用sql查询 | 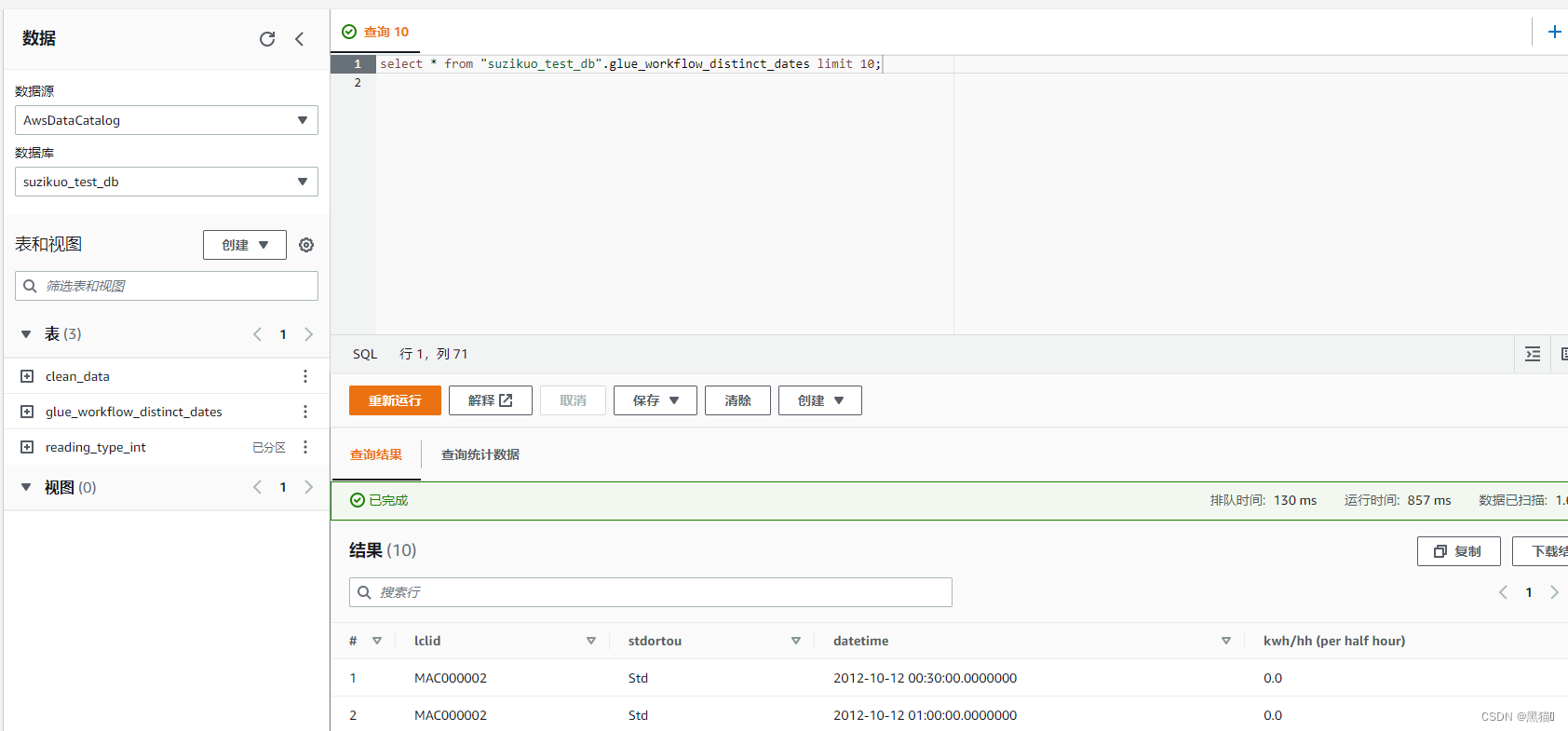 |
1.6 总结
在此实验中,我们使用Glue 的爬网程序自动解析存储在s3桶中的原始数据,自动创建了表。通过Glue数据库中的表,我们可以使用Athena对表进行查询(Athena每次检索表对应的s3桶数据,按检索量收费)。接下来我们会对原始数据进行转换、清洗以及分区操作,以及使用API Gateway+Lambda实现一个无服务架构,通过API查询数据。
这篇关于基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(一)——创建Glue的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





