本文主要是介绍d1-nezha-rtthread与rtthread的cv1800b反汇编文件分析,及测试是否进入os.bin,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
(1)PLCT实验室实习生长期招聘:招聘信息链接
(2)因为根据教程,我一直Milkv-duo的rtthread一直没有进展,据我所知,一般只有entry函数前面部分有差异,然后是entry—>rtthread_startup—>rt_hw_board_init函数中系统时钟配置内容不同。然后调整一下Flash,SRAM即可。
(3)因为第一次做操作系统的移植工作,因此只能走一步看一步了。我先对比研究一下d1-nezha-rtthread和rtthread的cv1800b反汇编文件。大概分析一下我的问题到底出现在哪里再尝试开始一步一步的做测试工作。
(4)阅读本文前,请先看:
<1>生成fip.bin在Milkv-duo上跑rtthread的相关尝试,及其问题分析;
<2>如何自己生成fip.bin在Milkv-duo上跑freertos;
研究反汇编
前期准备
(1)首先,我们先准备好
d1-nezha-rtthread和rtthread的cv1800b反汇编文件。
rtthread反汇编文件生成
(1)这里的
PATH=路径是你交叉编译工具链的路径。
export PATH=/opt/riscv64-linux-musleabi_for_x86_64-pc-linux-gnu/bin:$PATH
riscv64-unknown-elf-objdump -d rtthread.elf > rtthread_disassembly.txt
d1-nezha-rtthread反汇编文件生成
riscv64-unknown-elf-objdump -d rtthread.elf > d1s_disassembly.txt
反汇编对比分析
d1-nezha-rtthread反汇编分析
(1)d1-nezha-rtthread的反汇编非常好研究,极其简单。
_start前期工作,可能包括设置特定的控制寄存器(CSRs),关闭机器级中断,生成相对地址,并将生成的地址存储在寄存器 t0 中。trap_entry,应该是设置中断处理入口地址为t0,初始化栈指针。clear_bss,清除bss。entry,之后的内容一致。
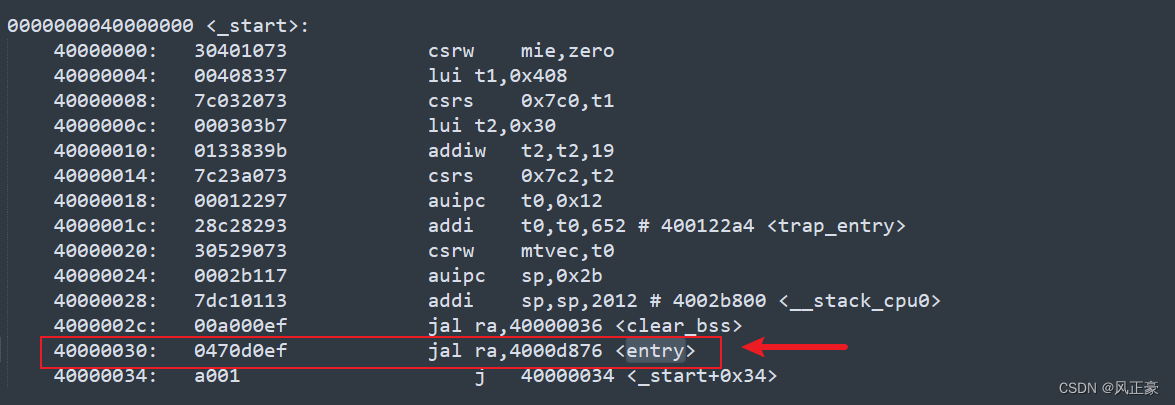
rtthread反汇编分析
(1)
RT-Thread的反汇编就略微的复杂一点点
<1>首先是跳转到g_wake_up函数中。
boot_hartid,应该是对中断的相关寄存器进行配置。trap_entry,清空ra到t0这32个寄存器。__global_pointer,应该是栈分配吧。init_bss,清除bss,这部分RT-Thread仓库和D1S仓库对bss操作不一样。sbi_init,RT-Thread仓库中有这个函数,但是D1S仓库中没有进行这个函数调用。
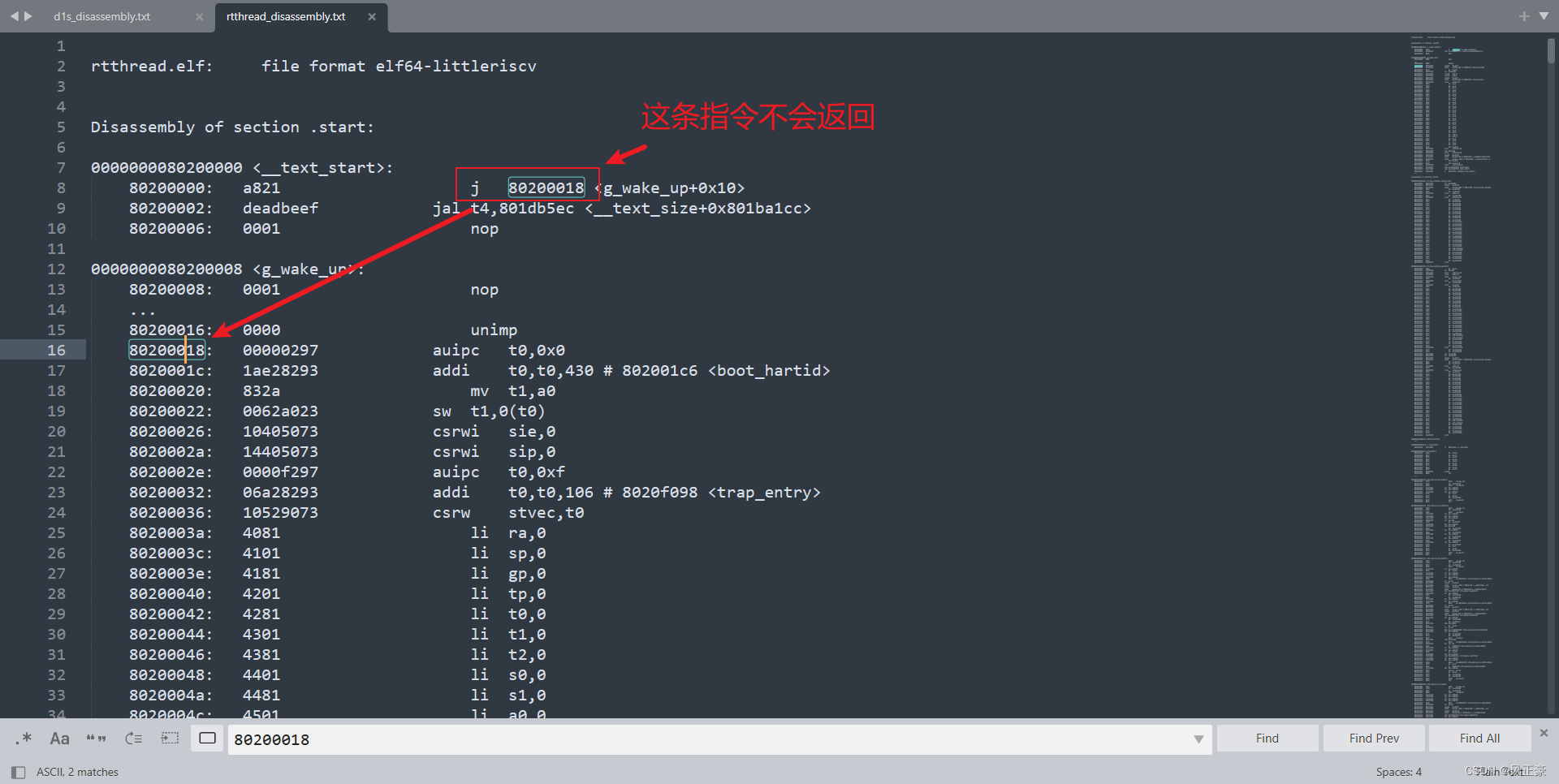
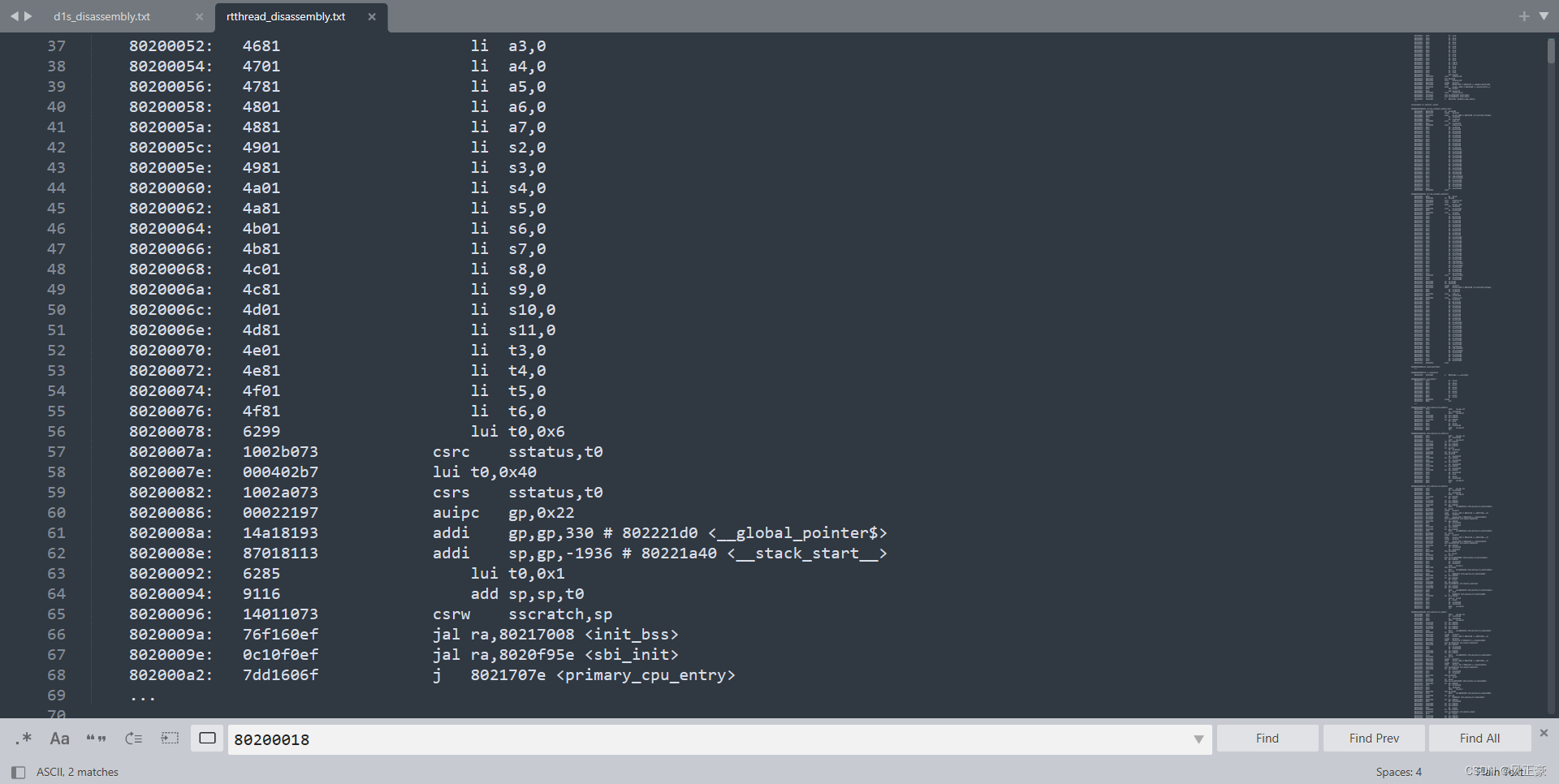
<2>
g_wake_up函数执行完成之后,会跳转到primary_cpu_entry中执行。
rt_hw_interrupt_disable,关闭了全局中断。__rt_assert_handler,应该是进行一些检查和断言吧。rt_assert_set_hook,进行一些寄存器值的保存和加载,并且与栈操作相关。entry,之后的内容一致。
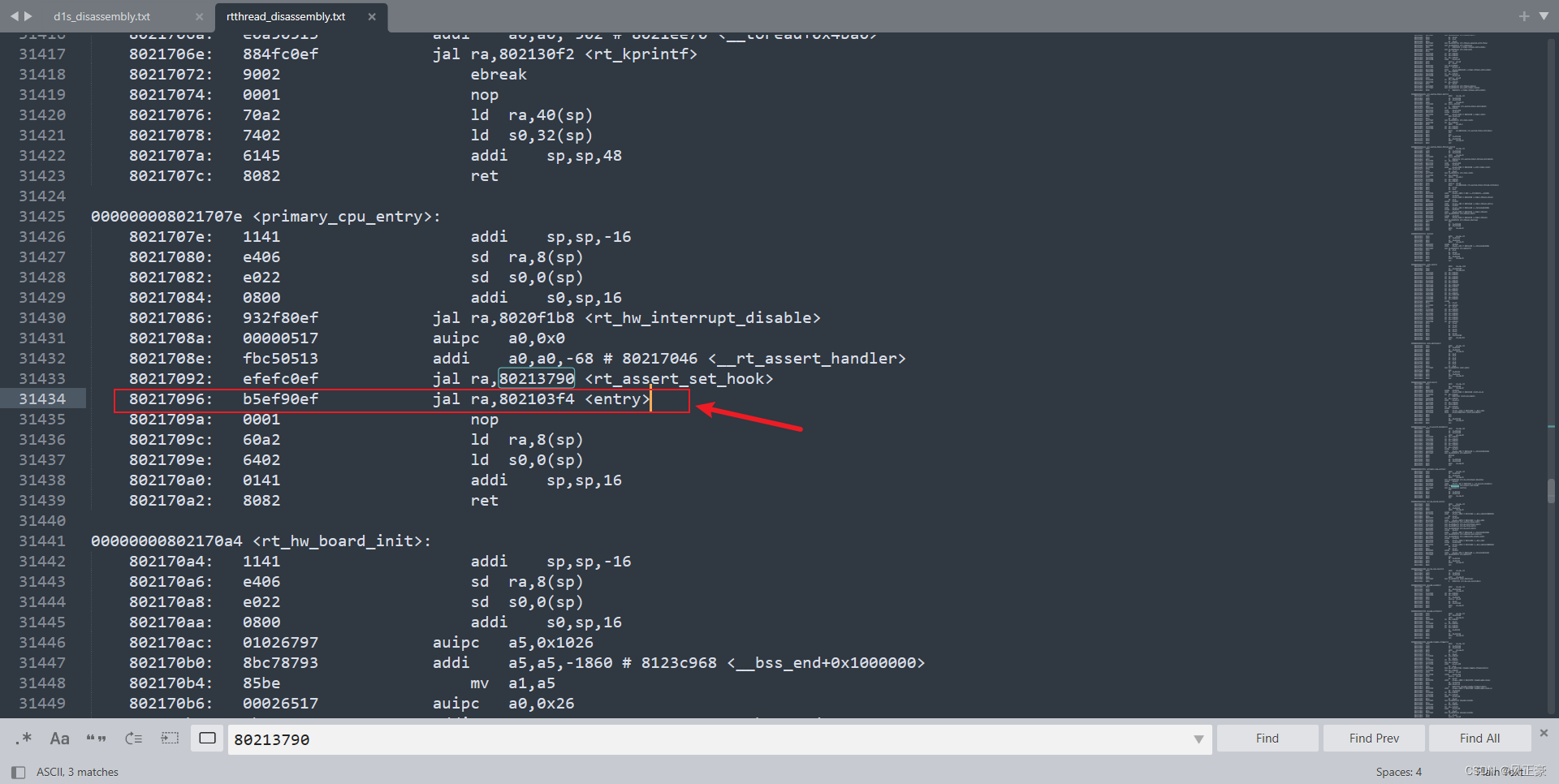
测试是否进入了rtos.bin
找到第一个执行文件
(1)既然知道问题所在了,对启动流程有了一个初步认识之后,那么我们是不是可以在进入
rtos.bin之前加一个打印信息呢?
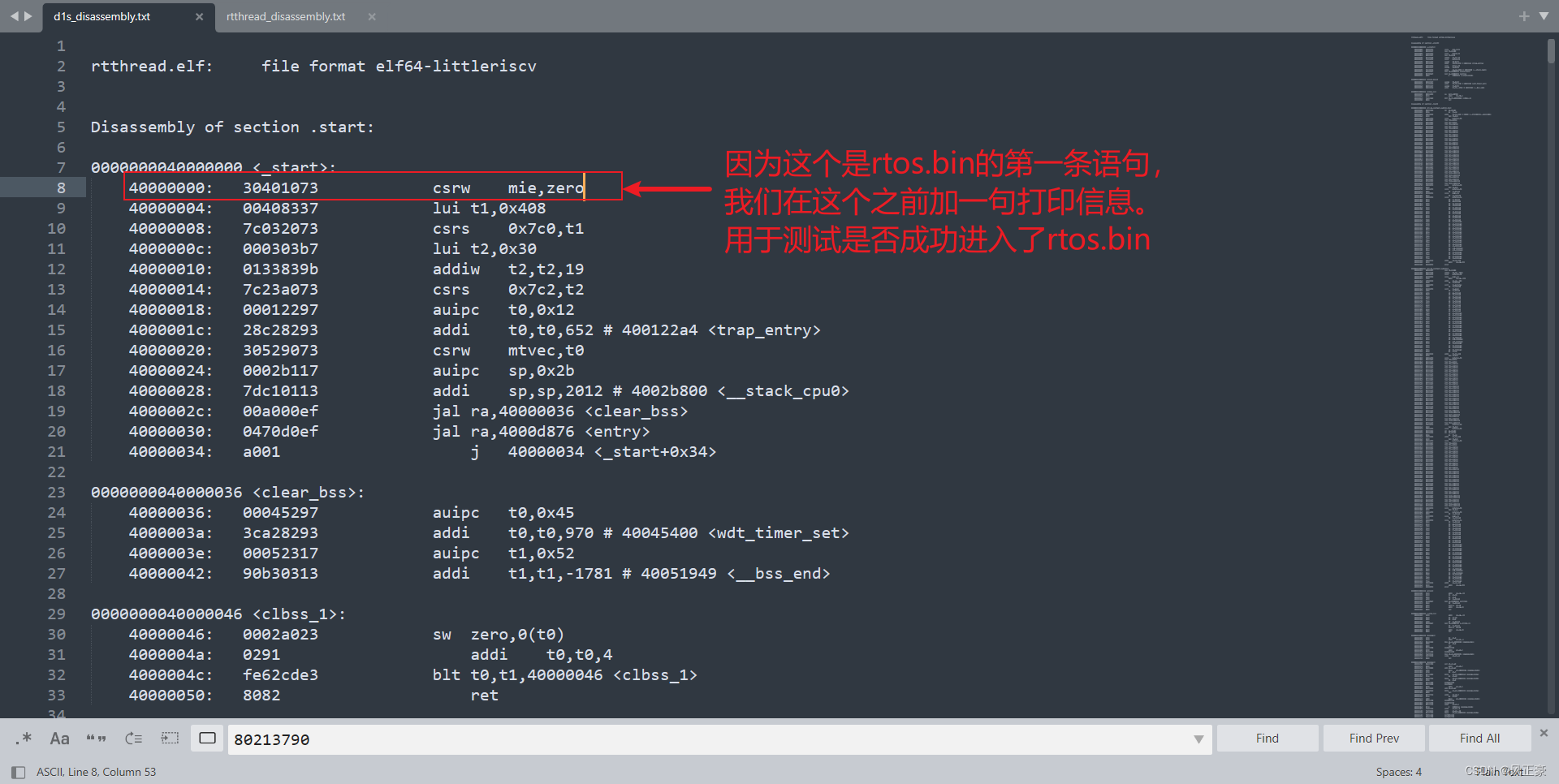
(2)既然有了这个想法,那么就马上开干。我们知道
_start中会调用trap_entry,__stack_cpu0,clear_bss,entry这几个函数。于是我们可以尝试使用grep命令,查看这几个函数分别在哪几个文件中出现。
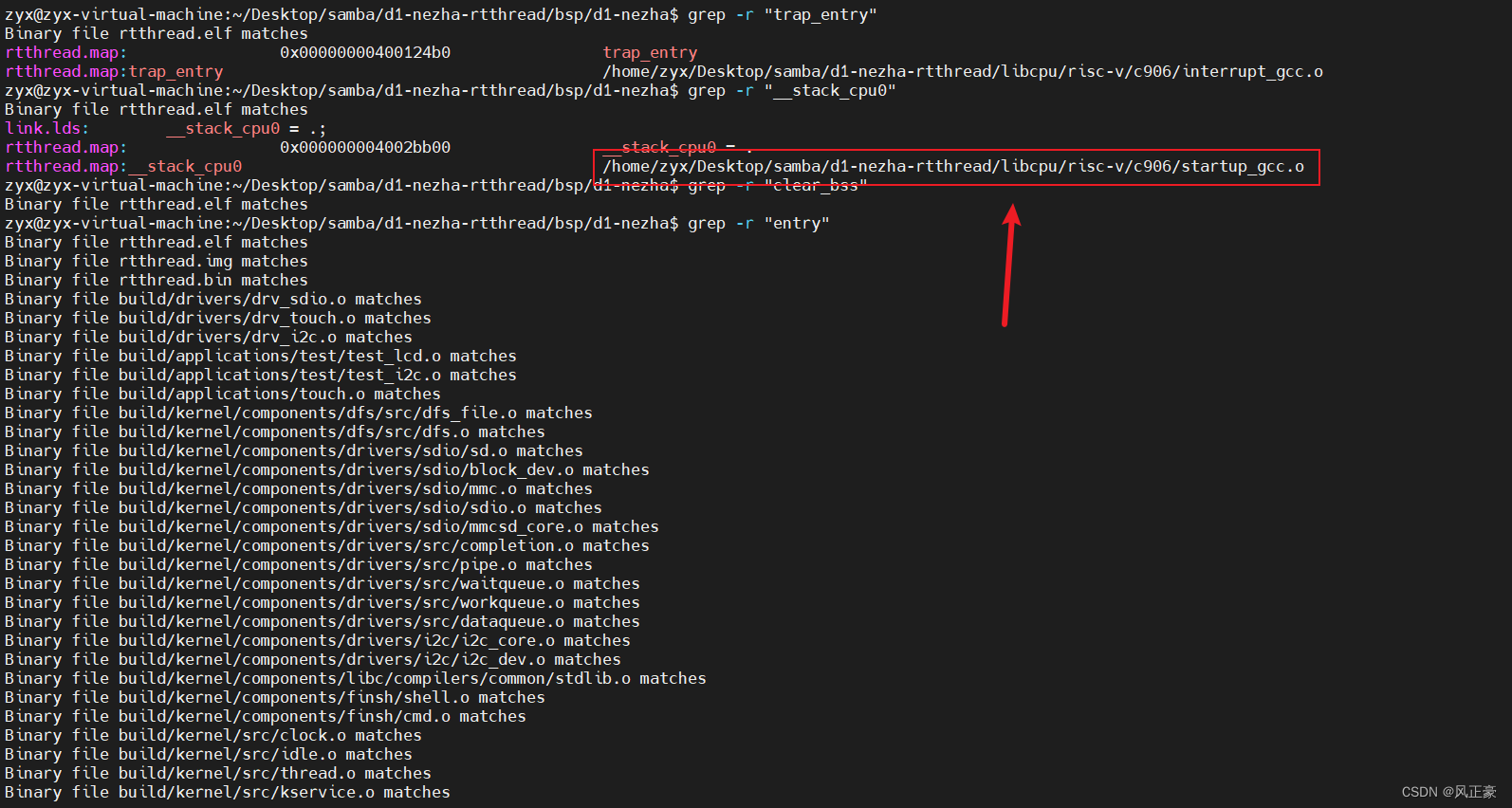
grep -r "trap_entry"
grep -r "__stack_cpu0"
grep -r "clear_bss"
grep -r "entry"
(3)通过查找的信息,我们很明显可以知道,大概率是在
_start大概率是在startup_gcc.c或者是startup_gcc.S中出现。
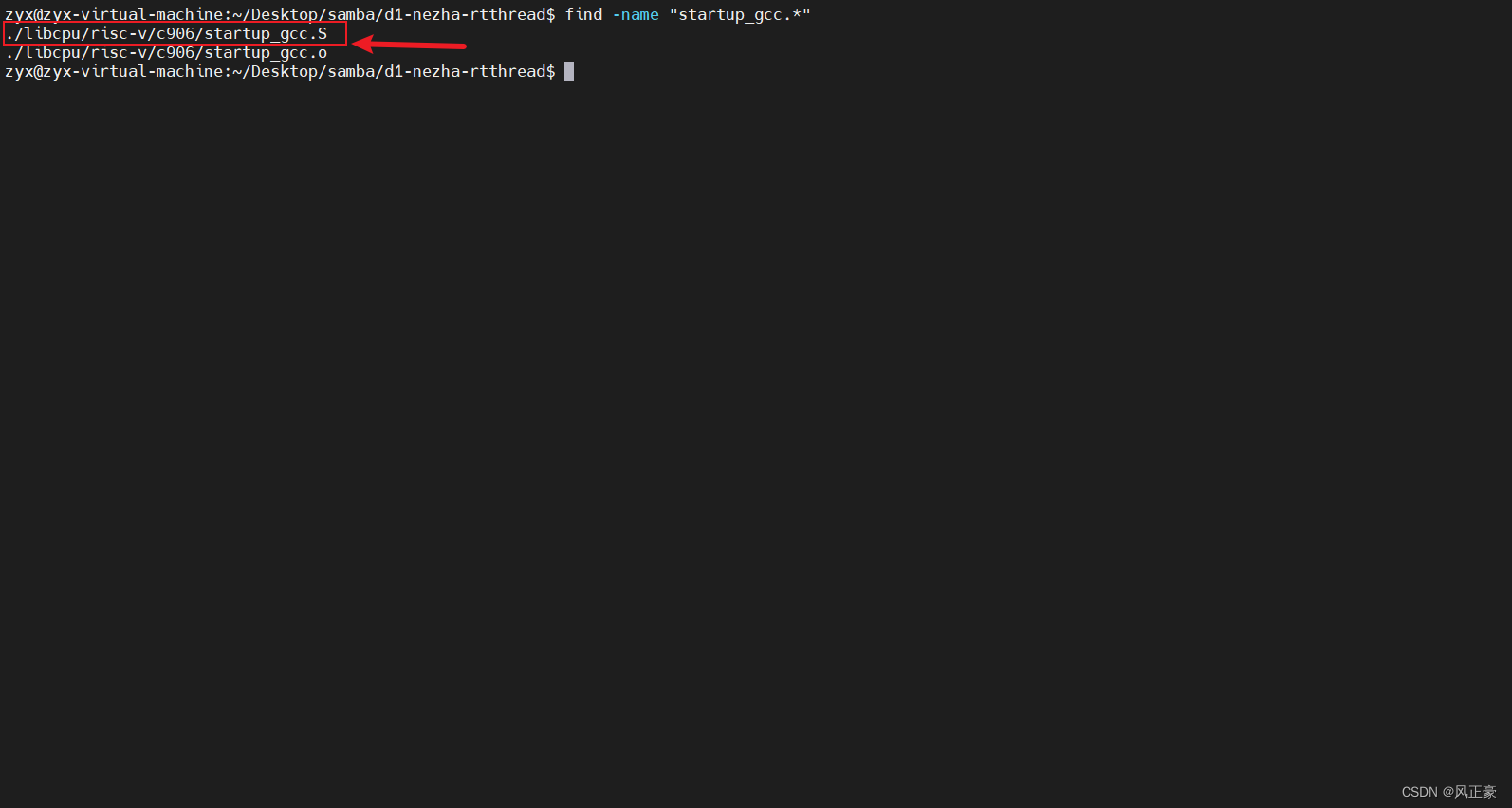
(4)此时我们需要移动到仓库的根目录。然后执行如下查找指令,就可以找到
startup_gcc.S文件。
cd ../..
find -name "startup_gcc.*"
修改文件内容
(1)这里我们需要将如何自己生成fip.bin在Milkv-duo上跑freertos这篇博客修改好的串口驱动程序移植过来。
(2)因为我这边反正是做测试使用,就大胆的把串口驱动文件放在了存放RT-Thread内核源码的src目录下了。这样就不会出现找不到文件的情况,减少麻烦。
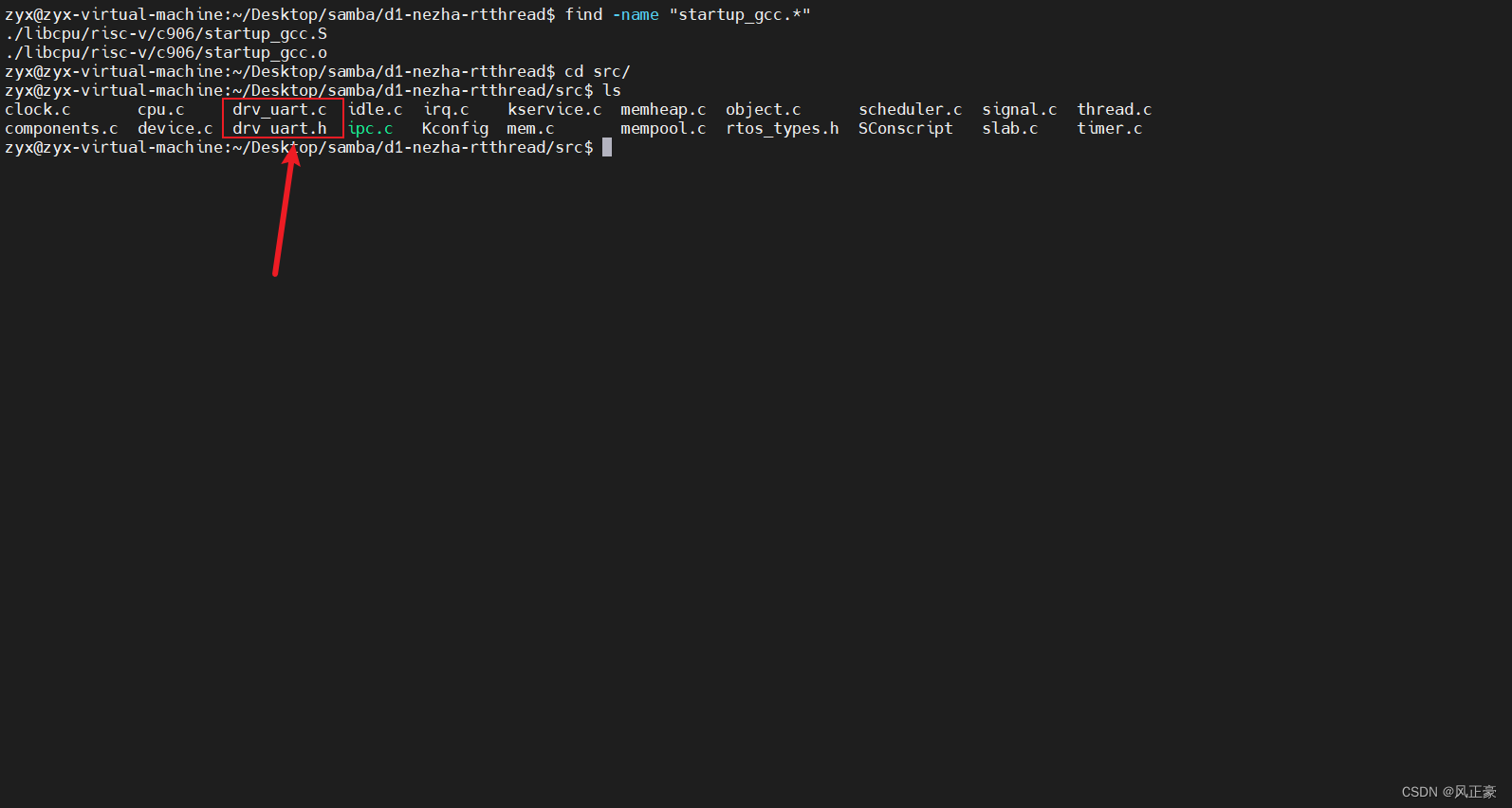
(3)这里我们就在
drv_uart中加入一个打印的测试函数print_zyx。
/* --- drv_uart.h --- */
void print_zyx(void);
/* --- drv_uart.c --- */
void print_zyx(void)
{dw8250_uart_init();dw8250_uart_putc('z');dw8250_uart_putc('y');dw8250_uart_putc('x');
}
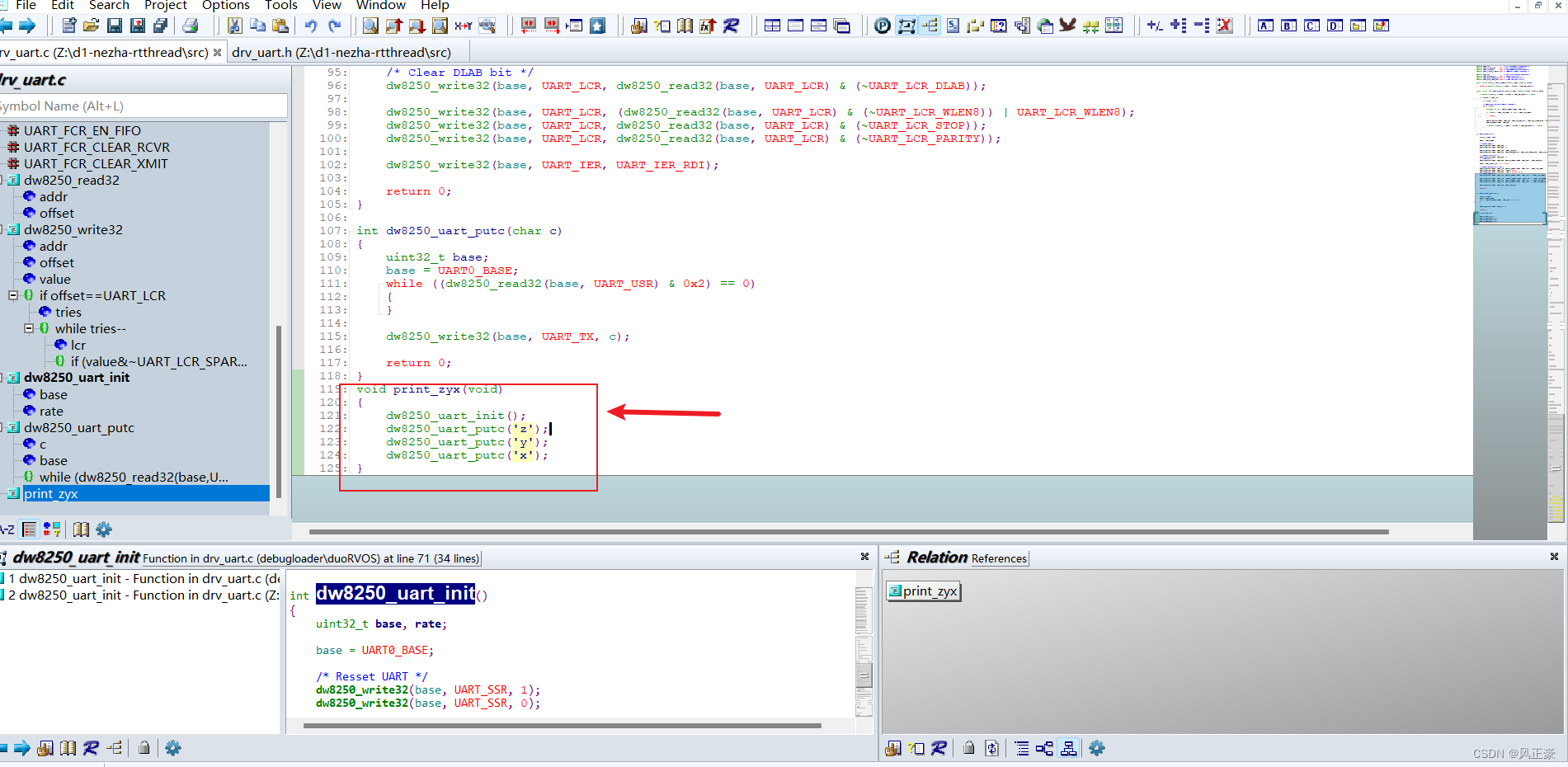
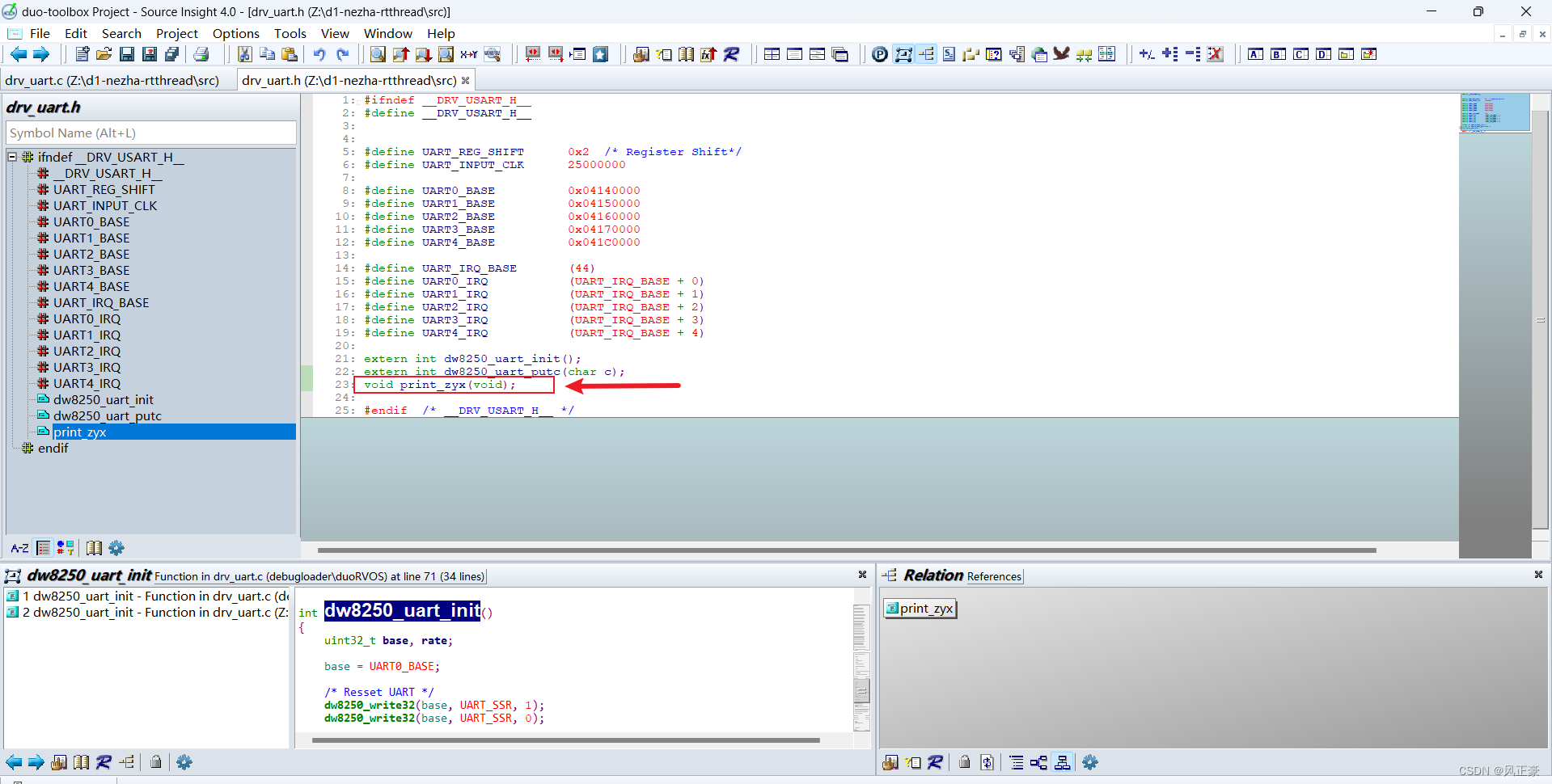
(4)在
libcpu/risc-v/c906/startup_gcc.S中调整
_start:jal print_zyx/*disable interrupt*/csrw mie, zero
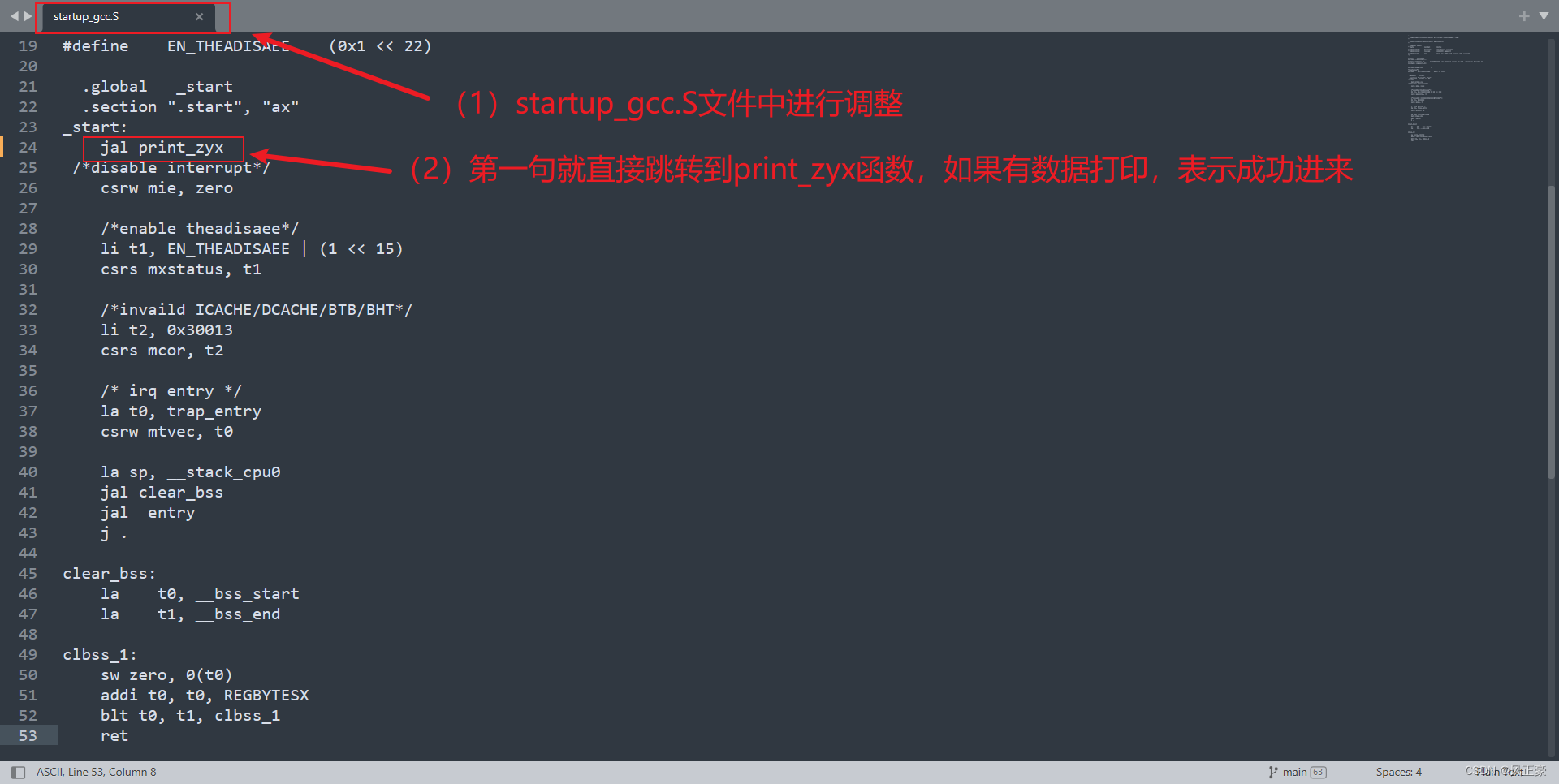
(4)在
bsp/d1-nezha中编译,然后使用grep命令查找print_zyx是否被编译进来。
scons -c
scons -j10
grep -r "print_zyx"
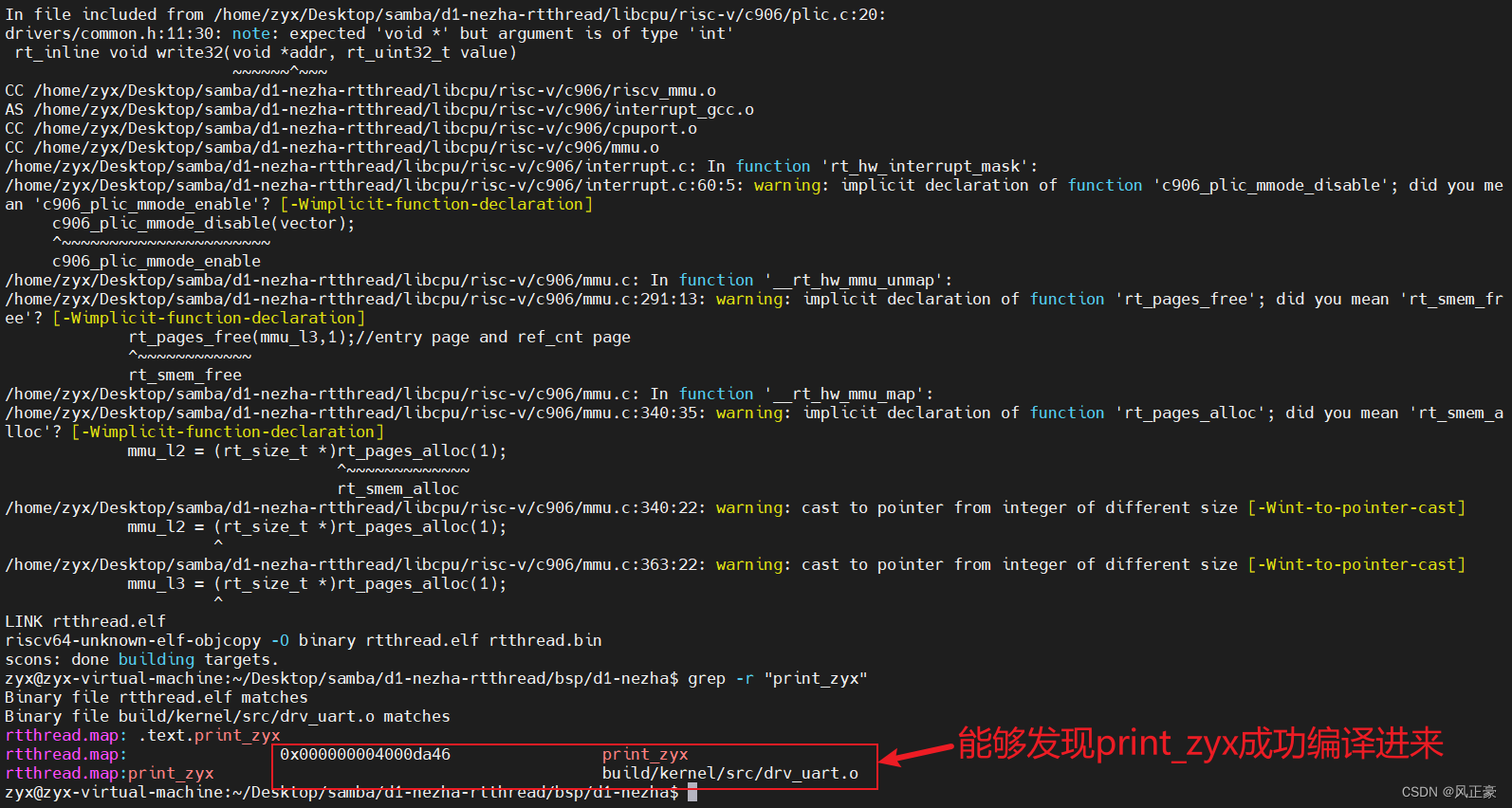
生成fip.bin
(1)执行如下命令,生成fip.bin,生成的fip.bin在build目录下。
# d1-nezha-rtthread仓库中
cd ${d1-nezha-rtthread_DIR}/bsp/d1-nezha
cp rtthread.bin rtos.bin
mv rtos.bin ${duo-toolbox_DIR}/debugloader/duoRVOS
# 进入duo-toolbox仓库路径
cd ${duo-toolbox_DIR}/debugloader/
export PATH=`pwd`/../host-tools/gcc/riscv64-linux-musl-x86_64/bin:$PATH
export PATH=`pwd`/../host-tools/gcc/riscv64-elf-x86_64/bin:$PATH
cd duoRVOS/
make clean
make
cd ../../fip/
cp ../debugloader/duoRVOS/os.bin .
make fsbl-build
(2)最终会出现一个乱码,具体原因不清楚。
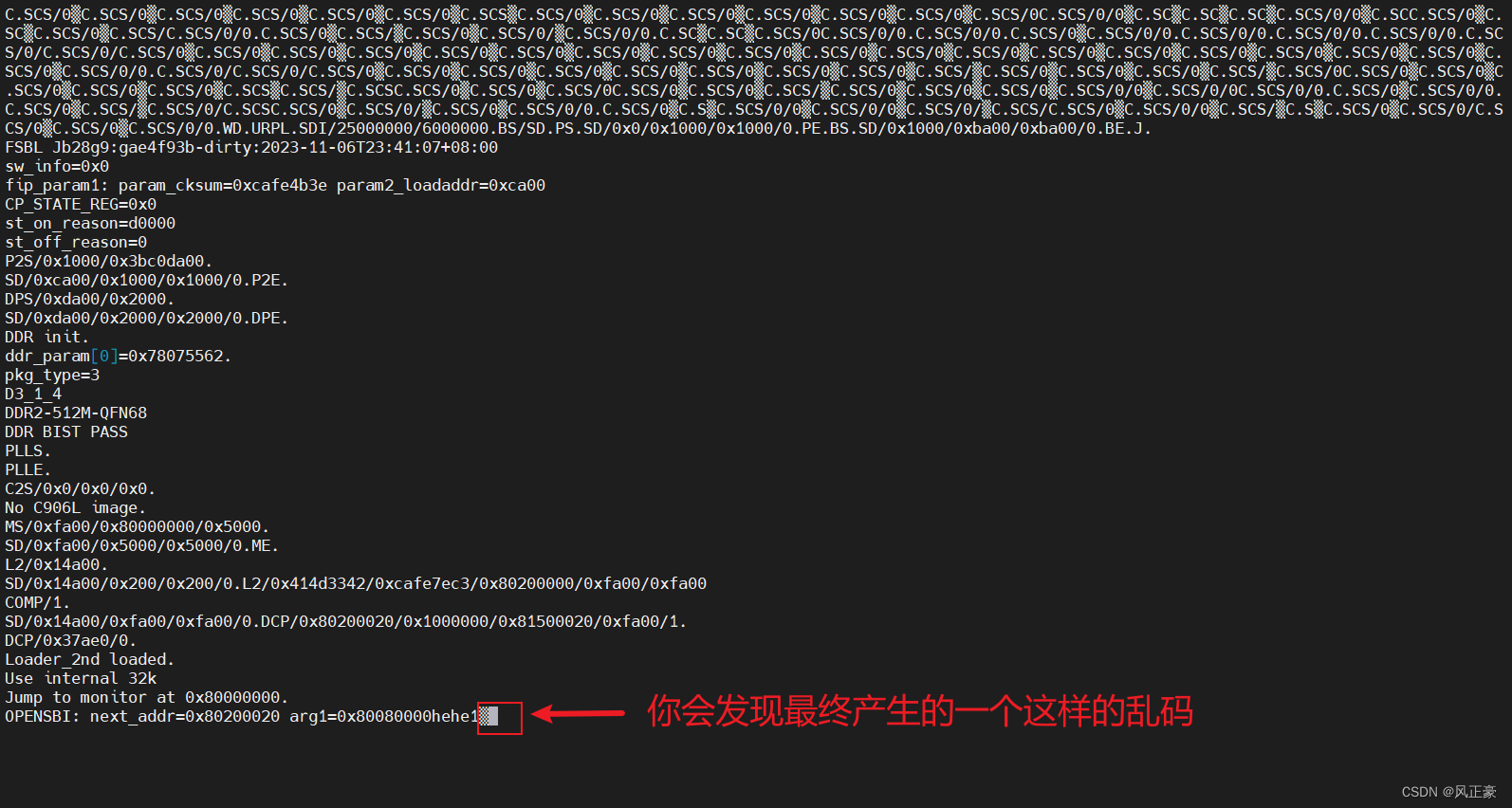
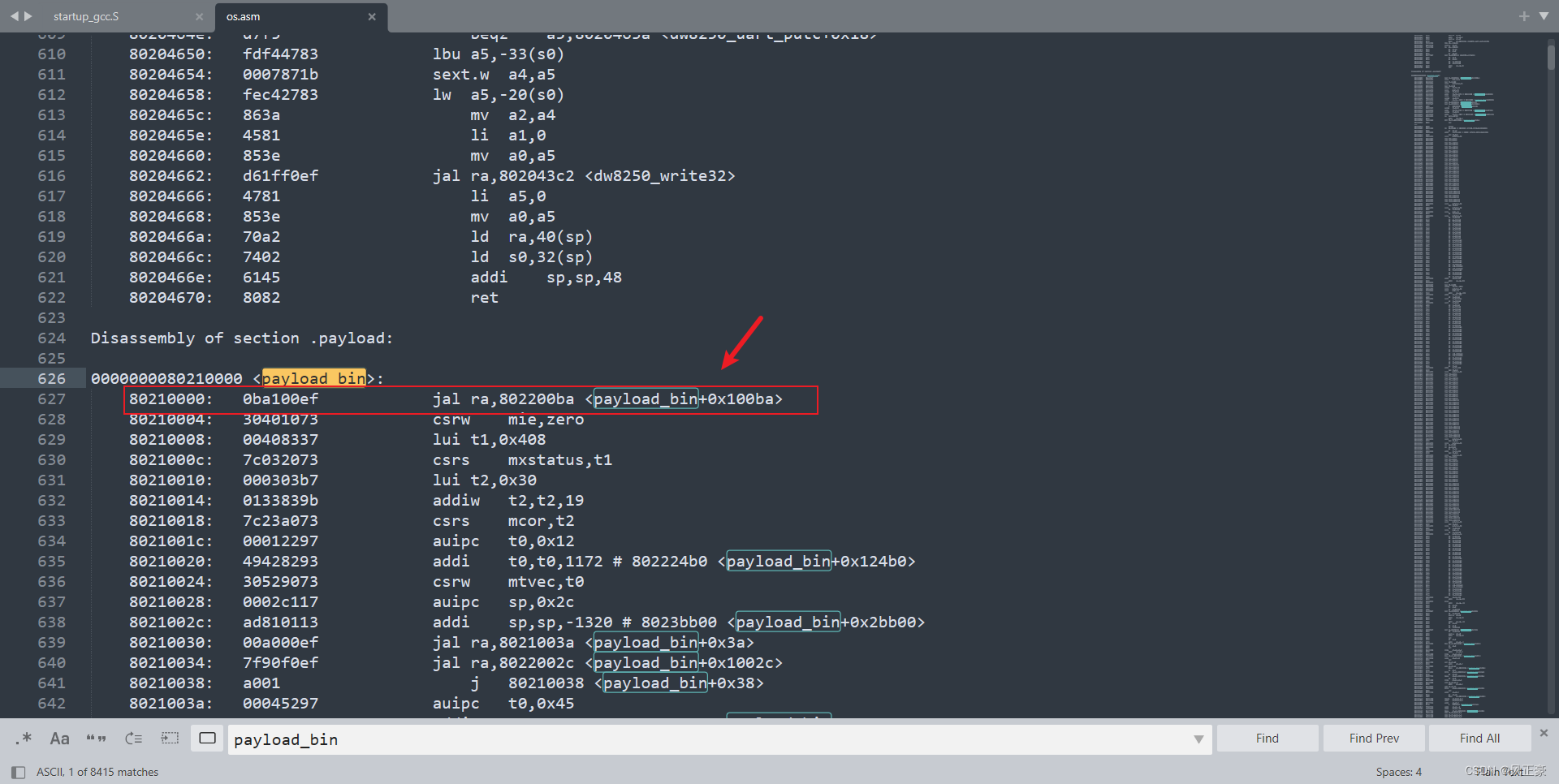
(3)为了确保
print_zyx是否编译进入了os.bin,我们可以看看os.asm文件,找到payload_bin。我们能够发现csrw mie,zero指令前面有一个jal的跳转指令,说明是成功将print_zyx是否编译进入了os.bin。至于为什么会出现乱码打印,还在研究中。
参考文章
(1)面包板社区:教你动手移植RT-Thread到国产MCU
(2)C站:生成fip.bin在Milkv-duo上跑rtthread的相关尝试,及其问题分析;
(3)C站:如何自己生成fip.bin在Milkv-duo上跑freertos;
这篇关于d1-nezha-rtthread与rtthread的cv1800b反汇编文件分析,及测试是否进入os.bin的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






