本文主要是介绍【考研复习】二叉树的特殊存储|三叉链表存储二叉树、一维数组存储二叉树、线索二叉树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 三叉链表存储二叉树
- 三叉链表的前序遍历(不使用栈)法一
- 三叉链表的前序遍历(不使用栈)法二
- 一维数组存储二叉树
- 一维数组存储二叉树的先序遍历
- 线索二叉树的建立
- 中序线索二叉树的遍历
- 真题演练
三叉链表存储二叉树
三叉链表结构体表示如下图所示:
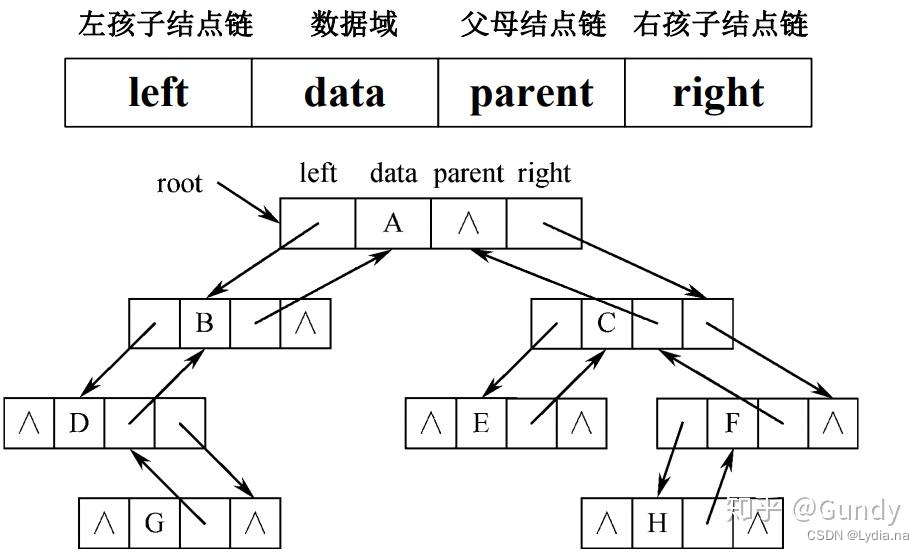
构造三叉链表方式:
typedef struct node{char data;struct node*parent,*lchild,*rchild;
}BTNode,*BiTree;
BTNode * creattree(BiTree &t){ // 易错点:树的引用char ch;cin>>ch;if(ch=='#'){t=NULL;}else{t=(BTNode*)malloc(sizeof(BTNode));// 易错点:忘记重新创建新结点t->data=ch;t->parent=NULL;t->lchild=NULL;t->rchild=NULL;if(t->lchild) t->lchild->parent=t;if(t->rchild) t->rchild->parent=t;creattree(t->lchild);creattree(t->rchild);}return t;
}
另外设计一个填充函数,函数功能是将所有结点的parent结点填充正确。
void FillParent(BiTree &root){if(root==NULL) return;if(root->lchild) {root->lchild->parent=root;FillParent(root->lchild);}if(root->rchild){root->rchild->parent=root;FillParent(root->rchild);}
}
三叉链表的前序遍历(不使用栈)法一
void PreOrder(BiTree t){ //访问顺序:根左右BTNode *p;while(t){visit(t);//访问根if(t->lchild) t=t->lchild;//找到左下结点,下一次就循环访问左else if(t->rchild) t=t->rchild;//下一次循环访问右else{//如果当前结点既没有左孩子也没有有孩子while(1){//一直往上回溯到有非空的父亲结点、同时找到二叉树的那个“叉”p=t;//p指向根tt=t->parent;//t指向父亲结点if(!t) break;//如果t为空,则说明该节点是空结点,排除这种情况if(t->lchild==p&&t->rchild) break;//如果t的左孩子是p且t的右孩子不为空,跳出while之后到右结点}if(t)t=t->rchild;//往右边访问}}
}
三叉链表的前序遍历(不使用栈)法二
// 【题目】二叉树采用三叉链表的存储结构,试编写
// 不借助栈的非递归中序遍历算法。
// 三叉链表类型定义:
typedef struct TriTNode
{char data;struct TriTNode *parent, *lchild, *rchild;
} TriTNode, *TriTree;void InOrder(TriTree PT, void (*visit)(char))
/* 不使用栈,非递归中序遍历二叉树PT, */
/* 对每个结点的元素域data调用函数visit */
{TriTree p = PT, pr;while (p){if (p->lchild)p = p->lchild; // 寻找最左下结点else{visit(p->data); // 找到最左下结点并访问if (p->rchild){p = p->rchild; // 若有右子树,转到该子树,继续寻找最左下结点}else{pr = p; // 否则返回其父亲p = p->parent;while (p && (p->lchild != pr || !p->rchild)){ // 若其不是从左子树回溯来的,或左结点的父亲并没有右孩子if (p->lchild == pr) // 若最左结点的父亲并没有右孩子visit(p->data); // 直接访问父亲(不用转到右孩子)pr = p; // 父亲已被访问,故返回上一级p = p->parent; // 该while循环沿双亲链一直查找,若无右孩子则访问,直至找到第一个有右孩子的结点为止(但不访问该结点,留给下步if语句访问)}if (p){ // 访问父亲,并转到右孩子(经上步while处理,可以确定此时p有右孩子)visit(p->data);p = p->rchild;}}}}
}一维数组存储二叉树
// 动态输入
void CreateTreeArray(int a[], int n)
{char ch;for (int i = 0; i < n; i++){cin >> ch;a[i] = ch;}
}
一维数组存储二叉树的先序遍历
// 前序遍历
#define Maxsize 50
typedef struct BTNodeArray
{int data[Maxsize];int length;
} BTNodeArray;
void PreOrderArray(BTNodeArray t, int i)
{if (i >= t.length)return;printf("%d", t.data[i]);PreOrderArray(t, i * 2); // 遍历左子树PreOrderArray(t, i * 2 + 1); // 遍历右子树
}
线索二叉树的建立
线索二叉的的基本结构:


使用中序遍历的顺序进行线索化。代码中有一个难以理解的点,为什么不用p直接找后继,而是使用了前驱结点找后继。实际上,不是不用p找后继,而是从p找不到后继,所以只能间接地找前驱的后继,这样的方式找后继,明白了这点,代码就不难懂了。
//中序遍历线索化
void InOrder(ThreadTree &p,ThreadTree &pre){if(p!=NULL){InOrder(p->lchild,pre);if(p->lchild==NULL){ //只能通过当前结点找前驱p->lchild=pre;p->ltag=1;}if(pre!=NULL&&pre->rchild==NULL){ //只能通过前驱结点找后继pre->rchild=p;pre->rtag=1;}pre=p;InOrder(p->rchild,pre);}return;
}
void InOrderThread(ThreadTree t){ThreadNode *pre=NULL;if(t!=NULL){InOrder(t,pre);pre->rchild=NULL;pre->rtag=1;}
}
中序线索二叉树的遍历
//中序线索二叉树的遍历
//--最左下的结点
ThreadTree FirstNode(ThreadTree p){while(p->ltag==0) p=p->lchild;return p;
}
//--结点的后继
ThreadTree NextNode(ThreadTree p){if(p->rtag==0) p=p->rchild;else FirstNode(p->rchild);
}
//--开始遍历
void InOrderThreadCount(ThreadTree t){for(ThreadNode *p=FirstNode(t);p!=NULL;p=NextNode(p)) cout<<p->data<<endl;
}
真题演练

//建立三叉链表,
//删除每一个元素为x的结点,以及以他为根的子树且释放相应存储空间
#include<iostream>
using namespace std;void BuildTree(BiTree &t){char ch;cin>>ch;if(ch=='#'){t=NULL;}else{t=(BTNode *)malloc(sizeof(BTNode));t->data=ch;t->parent=NULL;t->lchild=NULL;t->rchild=NULL;if(t->lchild) t->lchild->parent=t;if(t->rchild) t->rchild->parent=t;BuildTree(t->lchild);BuildTree(t->rchild);}
}
void Destory(BiTree t){if(t==NULL) return;if(t->lchild) Destory(t->lchild);if(t->rchild) Destory(t->rchild);free(t); //释放根节点t=NULL; //空指针赋值0
}
void DeleteX(BiTree &t,char x){if(t==NULL) return;if(t->data==x) Destory(t);DeleteX(t->lchild,x);DeleteX(t->rchild,x);
}
这篇关于【考研复习】二叉树的特殊存储|三叉链表存储二叉树、一维数组存储二叉树、线索二叉树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




