本文主要是介绍数据结构与算法之美学习笔记:33 | 字符串匹配基础(中):如何实现文本编辑器中的查找功能?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- BM 算法的核心思想
- BM 算法原理分析
- BM 算法代码实现
- BM 算法的性能分析及优化
- 解答开篇 & 内容小结
前言

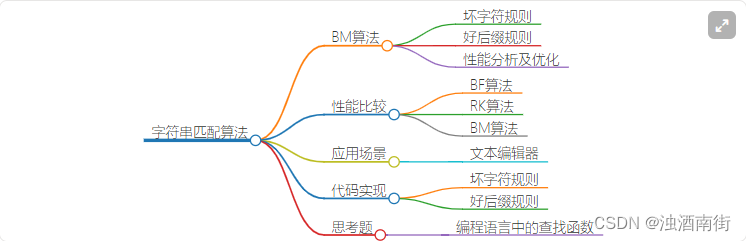
本节课程思维导图:
文本编辑器中的查找替换功能,我想你应该不陌生吧?比如,我们在 Word 中把一个单词统一替换成另一个,用的就是这个功能。你有没有想过,它是怎么实现的呢?
对于查找功能是重要功能的软件来说,比如一些文本编辑器,它们的查找功能都是用哪种算法来实现的呢?有没有比 BF 算法和 RK 算法更加高效的字符串匹配算法呢?今天,我们就来学习 BM(Boyer-Moore)算法。它是一种非常高效的字符串匹配算法。BM 算法的原理很复杂,比较难懂,学起来会比较烧脑,我会尽量给你讲清楚,同时也希望你做好打硬仗的准备。
BM 算法的核心思想
我们把模式串和主串的匹配过程,看作模式串在主串中不停地往后滑动。当遇到不匹配的字符时,BF 算法和 RK 算法的做法是,模式串往后滑动一位,然后从模式串的第一个字符开始重新匹配。
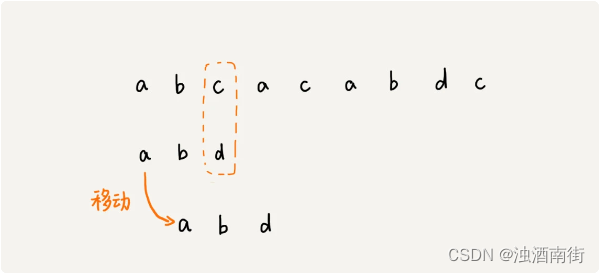
在这个例子里,主串中的 c,在模式串中是不存在的,所以,模式串向后滑动的时候,只要 c 与模式串没有重合,肯定无法匹配。所以,我们可以一次性把模式串往后多滑动几位,把模式串移动到 c 的后面。
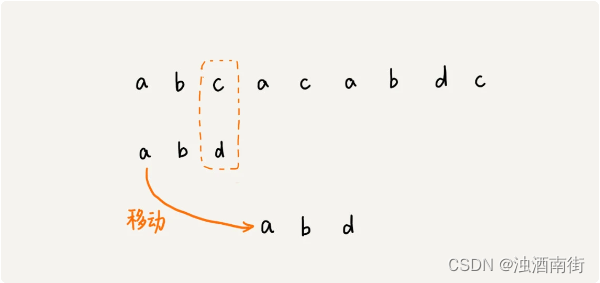
当遇到不匹配的字符时,有什么固定的规律,可以将模式串往后多滑动几位呢?这样一次性往后滑动好几位,那匹配的效率岂不是就提高了?
我们今天要讲的 BM 算法,本质上其实就是在寻找这种规律。借助这种规律,在模式串与主串匹配的过程中,当模式串和主串某个字符不匹配的时候,能够跳过一些肯定不会匹配的情况,将模式串往后多滑动几位。
BM 算法原理分析
BM 算法包含两部分,分别是坏字符规则(bad character rule)和好后缀规则(good suffix shift)。
- 坏字符规则
在匹配的过程中,我们都是按模式串的下标从小到大的顺序,依次与主串中的字符进行匹配的。这种匹配顺序比较符合我们的思维习惯,而 BM 算法的匹配顺序比较特别,它是按照模式串下标从大到小的顺序,倒着匹配的。
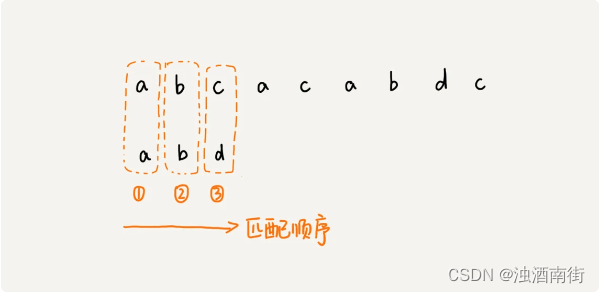
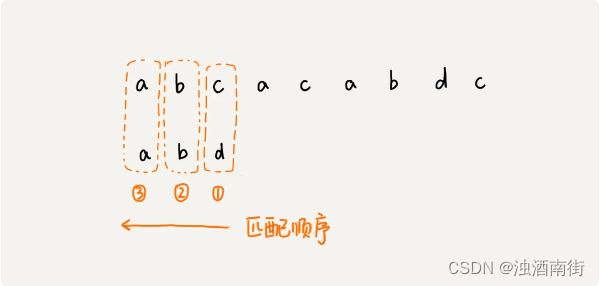
从模式串的末尾往前倒着匹配,当发现某个字符没法匹配的时候,我们把这个没有匹配的字符叫作坏字符(主串中的字符)。
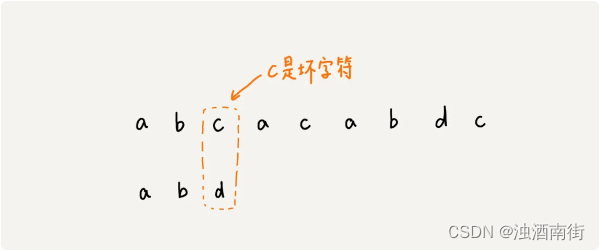
我们拿坏字符 c 在模式串中查找,发现模式串中并不存在这个字符,也就是说,字符 c 与模式串中的任何字符都不可能匹配。这个时候,我们可以将模式串直接往后滑动三位,将模式串滑动到 c 后面的位置,再从模式串的末尾字符开始比较。
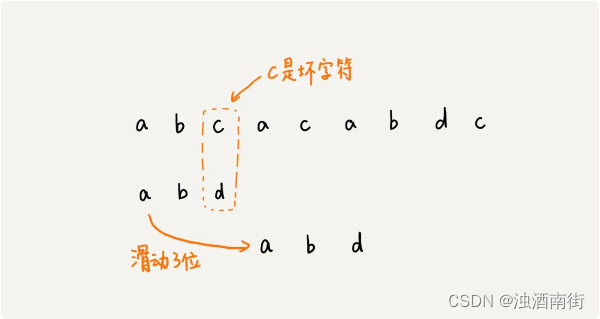
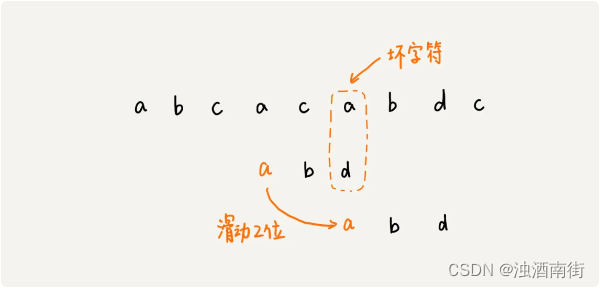
上图我们发现,模式串中最后一个字符 d,还是无法跟主串中的 a 匹配,这个时候,还能将模式串往后滑动三位吗?答案是不行的。因为这个时候,坏字符 a 在模式串中是存在的,模式串中下标是 0 的位置也是字符 a。这种情况下,我们可以将模式串往后滑动两位,让两个 a 上下对齐,然后再从模式串的末尾字符开始,重新匹配。
第一次不匹配的时候,我们滑动了三位,第二次不匹配的时候,我们将模式串后移两位,那具体滑动多少位,到底有没有规律呢?当发生不匹配的时候,我们把坏字符对应的模式串中的字符下标记作 si。如果坏字符在模式串中存在,我们把这个坏字符在模式串中的下标记作 xi。如果不存在,我们把 xi 记作 -1。那模式串往后移动的位数就等于 si-xi(注意,我这里说的下标,都是字符在模式串的下标)。
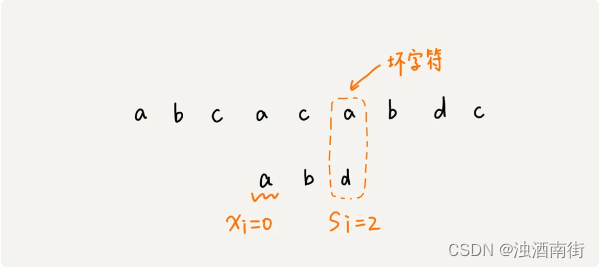
需要说明的是特别说明一点,如果坏字符在模式串里多处出现,那我们在计算 xi 的时候,选择最靠后的那个,因为这样不会让模式串滑动过多,导致本来可能匹配的情况被滑动略过。
利用坏字符规则,BM 算法在最好情况下的时间复杂度非常低,是 O(n/m)。不过,单纯使用坏字符规则还是不够的。因为根据 si-xi 计算出来的移动位数,有可能是负数,所以,BM 算法还需要用到“好后缀规则”。
- 好后缀规则
好后缀规则实际上跟坏字符规则的思路很类似。你看我下面这幅图。当模式串滑动到图中的位置的时候,模式串和主串有 2 个字符是匹配的,倒数第 3 个字符发生了不匹配的情况。
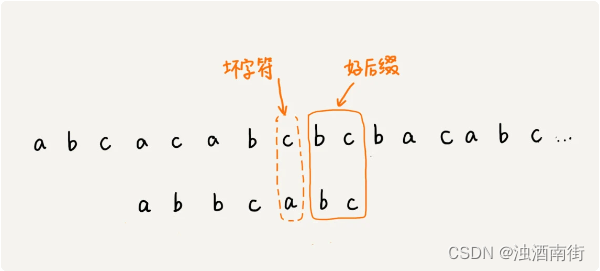
我们把已经匹配的 bc 叫作好后缀,记作{u}。我们拿它在模式串中查找,如果找到了另一个跟{u}相匹配的子串{u*},那我们就将模式串滑动到子串{u*}与主串中{u}对齐的位置。
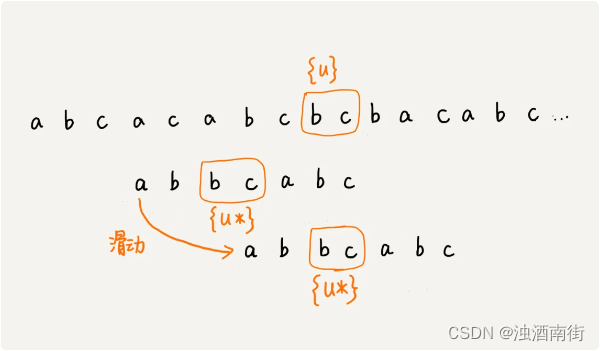
如果在模式串中找不到另一个等于{u}的子串,我们就直接将模式串,滑动到主串中{u}的后面,因为之前的任何一次往后滑动,都没有匹配主串中{u}的情况。
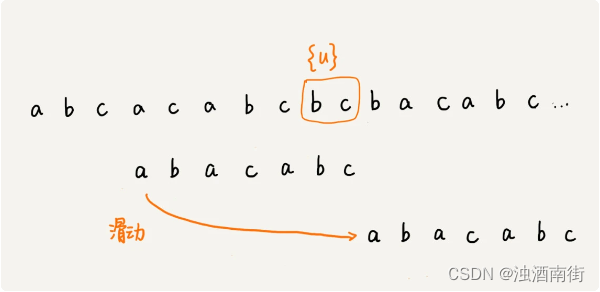
不过,当模式串中不存在等于{u}的子串时,我们直接将模式串滑动到主串{u}的后面。这样做是否有点太过头呢?我们来看下面这个例子。这里面 bc 是好后缀,尽管在模式串中没有另外一个相匹配的子串{u*},但是如果我们将模式串移动到好后缀的后面,如图所示,那就会错过模式串和主串可以匹配的情况。

所以,针对这种情况,我们不仅要看好后缀在模式串中,是否有另一个匹配的子串,我们还要考察好后缀的后缀子串,是否存在跟模式串的前缀子串匹配的。
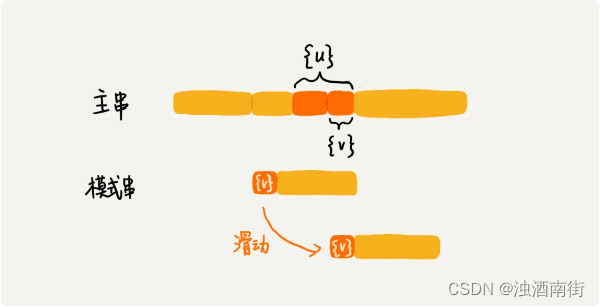
我现在回答一下前面那个问题。当模式串和主串中的某个字符不匹配的时候,如何选择用好后缀规则还是坏字符规则,来计算模式串往后滑动的位数?我们可以分别计算好后缀和坏字符往后滑动的位数,然后取两个数中最大的,作为模式串往后滑动的位数。这种处理方法还可以避免我们前面提到的,根据坏字符规则,计算得到的往后滑动的位数,有可能是负数的情况。
BM 算法代码实现
“坏字符规则”本身不难理解。当遇到坏字符时,要计算往后移动的位数 si-xi,其中 xi 的计算是重点,我们如何求得 xi 呢?或者说,如何查找坏字符在模式串中出现的位置呢?
我们只实现一种最简单的情况,假设字符串的字符集不是很大,每个字符长度是 1 字节,我们用大小为 256 的数组,来记录每个字符在模式串中出现的位置。数组的下标对应字符的 ASCII 码值,数组中存储这个字符在模式串中出现的位置。
private static final int SIZE = 256; // 全局变量或成员变量
private void generateBC(char[] b, int m, int[] bc) {//变量 b 是模式串,m 是模式串的长度,bc 表示散列表。for (int i = 0; i < SIZE; ++i) {bc[i] = -1; // 初始化bc}for (int i = 0; i < m; ++i) {int ascii = (int)b[i]; // 计算b[i]的ASCII值bc[ascii] = i;}
}
public int bm(char[] a, int n, char[] b, int m) {int[] bc = new int[SIZE]; // 记录模式串中每个字符最后出现的位置generateBC(b, m, bc); // 构建坏字符哈希表int i = 0; // i表示主串与模式串对齐的第一个字符while (i <= n - m) {int j;for (j = m - 1; j >= 0; --j) { // 模式串从后往前匹配if (a[i+j] != b[j]) break; // 坏字符对应模式串中的下标是j}if (j < 0) {return i; // 匹配成功,返回主串与模式串第一个匹配的字符的位置}// 这里等同于将模式串往后滑动j-bc[(int)a[i+j]]位i = i + (j - bc[(int)a[i+j]]); }return -1;
}
现在,我们就来看看,如何实现好后缀规则。它的实现要比坏字符规则复杂一些。

// b表示模式串,m表示长度,suffix,prefix数组事先申请好了
private void generateGS(char[] b, int m, int[] suffix, boolean[] prefix) {for (int i = 0; i < m; ++i) { // 初始化suffix[i] = -1;prefix[i] = false;}for (int i = 0; i < m - 1; ++i) { // b[0, i]int j = i;int k = 0; // 公共后缀子串长度while (j >= 0 && b[j] == b[m-1-k]) { // 与b[0, m-1]求公共后缀子串--j;++k;suffix[k] = j+1; //j+1表示公共后缀子串在b[0, i]中的起始下标}if (j == -1) prefix[k] = true; //如果公共后缀子串也是模式串的前缀子串}
}
我们把好后缀规则加到前面的代码框架里,就可以得到 BM 算法的完整版代码实现。
// a,b表示主串和模式串;n,m表示主串和模式串的长度。
public int bm(char[] a, int n, char[] b, int m) {int[] bc = new int[SIZE]; // 记录模式串中每个字符最后出现的位置generateBC(b, m, bc); // 构建坏字符哈希表int[] suffix = new int[m];boolean[] prefix = new boolean[m];generateGS(b, m, suffix, prefix);int i = 0; // j表示主串与模式串匹配的第一个字符while (i <= n - m) {int j;for (j = m - 1; j >= 0; --j) { // 模式串从后往前匹配if (a[i+j] != b[j]) break; // 坏字符对应模式串中的下标是j}if (j < 0) {return i; // 匹配成功,返回主串与模式串第一个匹配的字符的位置}int x = j - bc[(int)a[i+j]];int y = 0;if (j < m-1) { // 如果有好后缀的话y = moveByGS(j, m, suffix, prefix);}i = i + Math.max(x, y);}return -1;
}// j表示坏字符对应的模式串中的字符下标; m表示模式串长度
private int moveByGS(int j, int m, int[] suffix, boolean[] prefix) {int k = m - 1 - j; // 好后缀长度if (suffix[k] != -1) return j - suffix[k] +1;for (int r = j+2; r <= m-1; ++r) {if (prefix[m-r] == true) {return r;}}return m;
}
BM 算法的性能分析及优化
我们先来分析 BM 算法的内存消耗。整个算法用到了额外的 3 个数组,其中 bc 数组的大小跟字符集大小有关,suffix 数组和 prefix 数组的大小跟模式串长度 m 有关。
对于执行效率来说,我们可以先从时间复杂度的角度来分析。实际上,我前面讲的 BM 算法是个初级版本。基于我目前讲的这个版本,在极端情况下,预处理计算 suffix 数组、prefix 数组的性能会比较差。预处理的时间复杂度就是 O(m^2)。当然,大部分情况下,时间复杂度不会这么差。
解答开篇 & 内容小结
今天,我们讲了一种比较复杂的字符串匹配算法,BM 算法。尽管复杂、难懂,但匹配的效率却很高,在实际的软件开发中,特别是一些文本编辑器中,应用比较多。
BM 算法核心思想是,利用模式串本身的特点,在模式串中某个字符与主串不能匹配的时候,将模式串往后多滑动几位,以此来减少不必要的字符比较,提高匹配的效率。BM 算法构建的规则有两类,坏字符规则和好后缀规则。好后缀规则可以独立于坏字符规则使用。因为坏字符规则的实现比较耗内存,为了节省内存,我们可以只用好后缀规则来实现 BM 算法。
这篇关于数据结构与算法之美学习笔记:33 | 字符串匹配基础(中):如何实现文本编辑器中的查找功能?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





