本文主要是介绍AI助力智慧农业,基于SSD模型开发构建田间作物场景下庄稼作物、杂草检测识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
智慧农业随着数字化信息化浪潮的演变有了新的定义,在前面的系列博文中,我们从一些现实世界里面的所见所想所感进行了很多对应的实践,感兴趣的话可以自行移步阅读即可:
《自建数据集,基于YOLOv7开发构建农田场景下杂草检测识别系统》
《轻量级目标检测模型实战——杂草检测》
《激光除草距离我们实际的农业生活还有多远,结合近期所见所感基于yolov8开发构建田间作物杂草检测识别系统》
《基于yolov5的农作物田间杂草检测识别系统》
《AI助力智慧农业,基于YOLOv3开发构建农田场景下的庄稼作物、田间杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv4开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv5全系列模型【n/s/m/l/x】开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv6最新版本模型开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv7【tiny/yolov7/yolov7x】开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《AI助力智慧农业,基于YOLOv8全系列模型【n/s/m/l/x】开发构建不同参数量级的识别系统》
《AI助力智慧农业,基于DETR【DEtection TRansformer】模型开发构建田间作物场景下庄稼作物、杂草检测识别系统》
自动化的激光除草,是未来大面积农业规划化作物种植生产过程中非常有效的技术手段,本文是AI助力智慧农业的第八篇系列博文,主要的目的就是想要基于SSD来开发构建检测模型,助力智能检测分析。
首先看下实例效果:
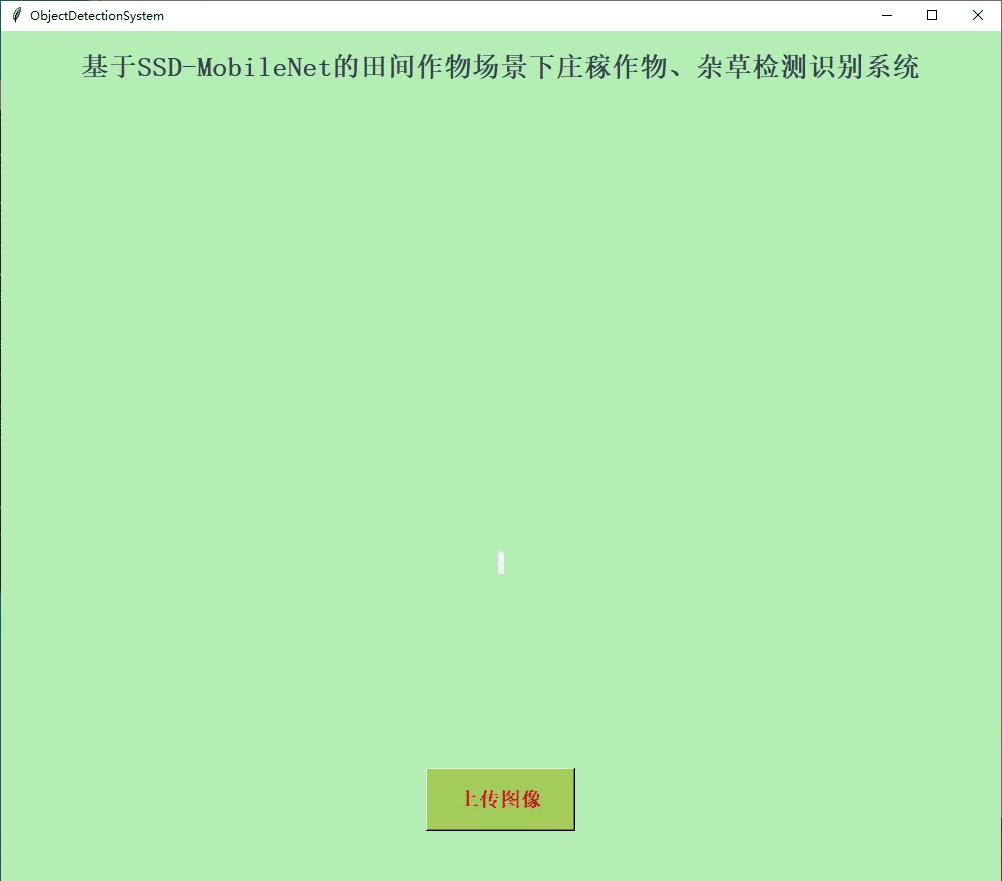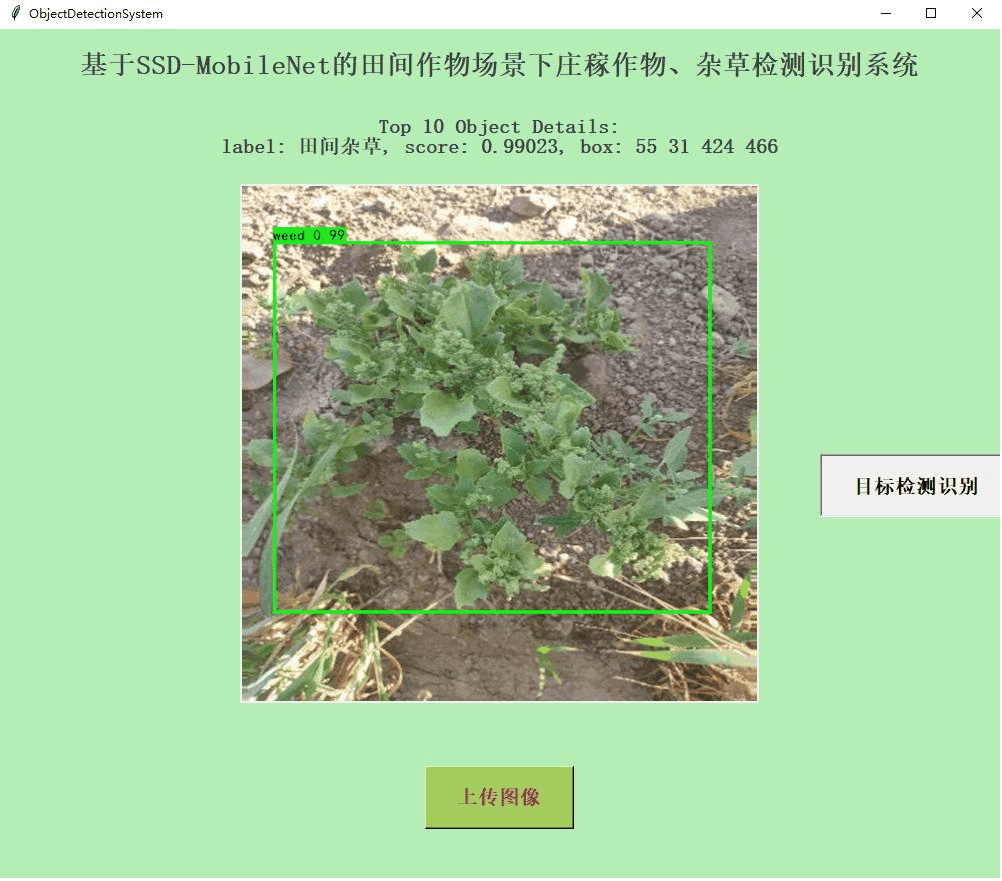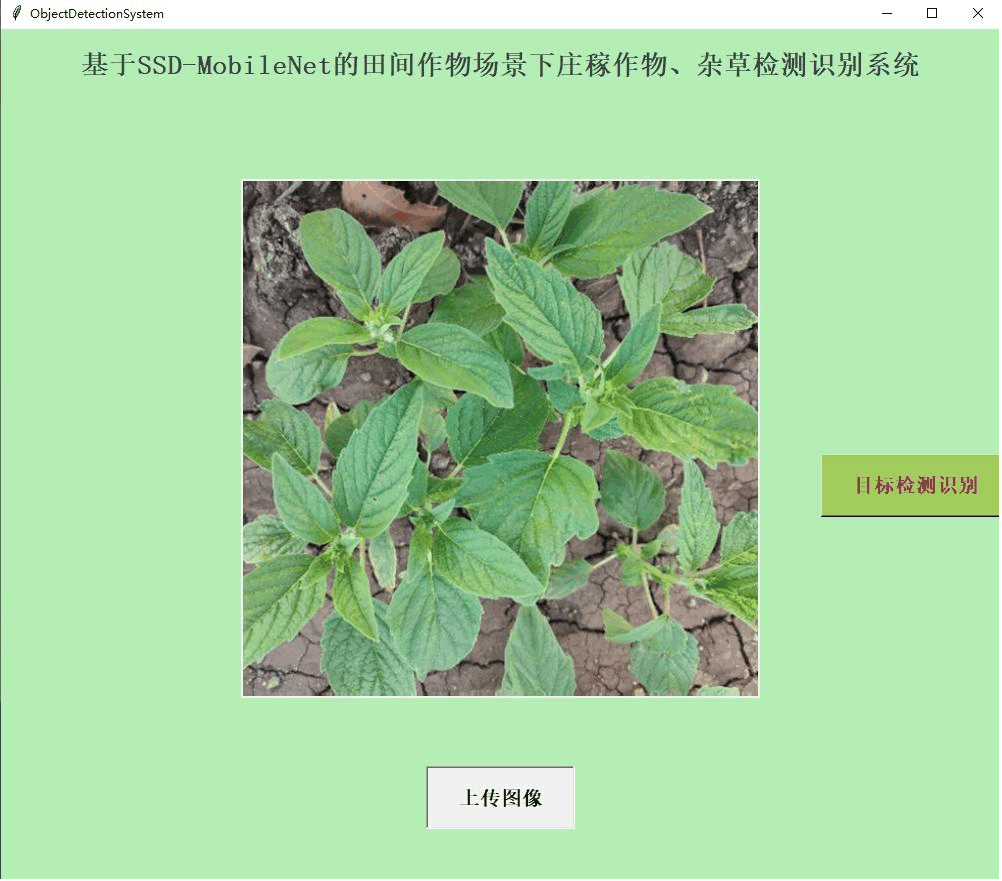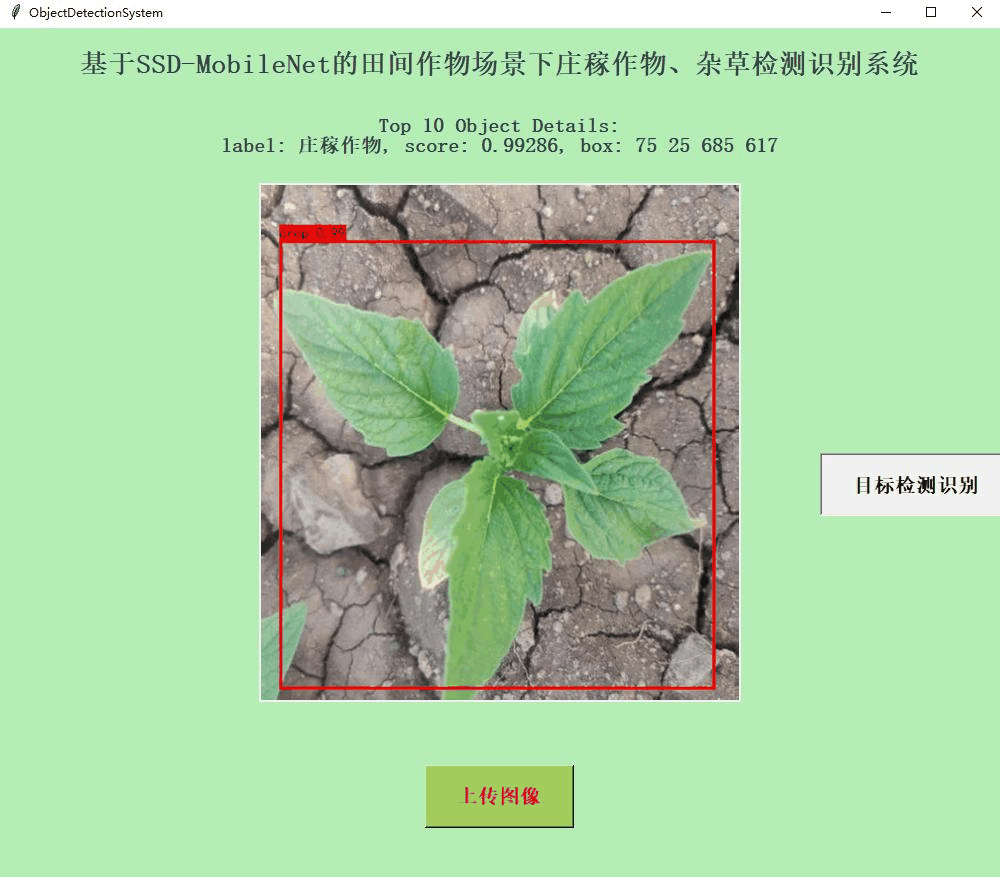
目标检测模型SSD(Single Shot Multibox Detector)是一种端到端的目标检测模型,能够在单次前向传播中同时预测目标的位置和类别。SSD将回归思想和锚框机制结合,消除了双阶段算法中候选区域生成和随后的像素或特征重采样阶段,并将所有计算封装在一个网络中,使其易于训练,速度较快。它将边界框的输出空间离散化为一组默认边框,这些框在不同层次的特征图上生成,而且有不同的长宽比。在预测时,网络预测每个默认边框中属于每个类别的可能性,使其紧致的包围目标。网络在多个具有不同分辨率的特征图上进行预测,可以处理各种大小的物体。
SSD网络可以分成特征提取和检测框生成两部分,特征提取采用的基础网络是从分类网络借鉴而来的。SSD采用VGG-16作为基础网络结构,使用VGG-16的前5层,将FC6和FC7层转化成两个卷积层。模型额外增加了3个卷积层和一个平均池化层。但是这样变化后,会改变感受野的大小,因此采用了扩张卷积。在裁剪的基础网络之后添加了卷积层,这些层的特征图大小是逐步减小的,从而实现在多尺度下进行预测。多尺度特征图包括conv4-3、conv7、conv8-2、conv9-2、conv10-2、conv11-2共6种尺度。SSD在每个添加的特征层上使用小的卷积核,预测一系列边框偏置。预测部分用于预测物体类别的置信度,并通过在特征图上使用小尺寸的卷积核来直接预测物体的边框坐标,因为预测是在6种不同的尺度下进行的,且每种尺度具有不同长宽比的锚框,所以能够提高目标检测的精度,而且整个算法可以进行端到端的训练,在检测速度上也有较大的优势。
SSD的算法构建原理如下:
-
提取特征:SSD首先使用一个卷积神经网络(CNN)如VGG或ResNet来提取输入图像的特征。这些特征图包含了不同层级的语义信息,能够帮助模型对不同尺寸和类别的目标进行检测。
-
多尺度检测:SSD在不同层级的特征图上应用了一系列卷积层和池化层,用于在不同尺度下检测目标。这种多尺度检测能够使模型更好地适应不同大小的目标。
-
预测边界框和类别:在每个特征图中,SSD使用卷积神经网络来预测边界框的位置和目标类别。针对每个位置和大小的锚框,SSD预测出与之匹配的目标边界框和对应的类别概率。
-
匹配策略:SSD通过匹配预测边界框和真实目标边界框之间的IoU(交并比)来确定哪些预测是有效的,并使用损失函数进行优化。
SSD的优点包括:
- 高效性:SSD能够在单次前向传播中完成目标检测,速度较快。
- 多尺度检测:SSD能够有效地检测不同大小的目标,适应多尺度目标检测的需求。
- 简单直接:SSD采用了单一模型完成检测,简化了模型的复杂度。
SSD的缺点包括:
- 定位精度较低:在小目标的定位上,SSD的精度可能受限。
- 目标排斥问题:SSD中的锚框预设可能会导致多个检测结果之间的相互排斥,需要额外的处理来解决。
论文地址在这里,如下所示:


进一步的详情可以自行阅读论文。
官方项目地址在这里,如下所示:
项目提供了三种不同的Backbone网络可供使用,这里我们使用的是mobilenetv3,如下所示:
"""
Creates a MobileNetV3 Model as defined in:
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam. (2019).
Searching for MobileNetV3
arXiv preprint arXiv:1905.02244.@ Credit from https://github.com/d-li14/mobilenetv3.pytorch
@ Modified by Chakkrit Termritthikun (https://github.com/chakkritte)"""import torch.nn as nn
import mathfrom ssd.modeling import registry
from ssd.utils.model_zoo import load_state_dict_from_urlmodel_urls = {'mobilenet_v3': 'https://github.com/d-li14/mobilenetv3.pytorch/raw/master/pretrained/mobilenetv3-large-1cd25616.pth',
}def _make_divisible(v, divisor, min_value=None):"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py:param v::param divisor::param min_value::return:"""if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_v < 0.9 * v:new_v += divisorreturn new_vclass h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)class SELayer(nn.Module):def __init__(self, channel, reduction=4):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, _make_divisible(channel // reduction, 8)),nn.ReLU(inplace=True),nn.Linear(_make_divisible(channel // reduction, 8), channel),h_sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * ydef conv_3x3_bn(inp, oup, stride):return nn.Sequential(nn.Conv2d(inp, oup, 3, stride, 1, bias=False),nn.BatchNorm2d(oup),h_swish())def conv_1x1_bn(inp, oup):return nn.Sequential(nn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),h_swish())class InvertedResidual(nn.Module):def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):super(InvertedResidual, self).__init__()assert stride in [1, 2]self.identity = stride == 1 and inp == oupif inp == hidden_dim:self.conv = nn.Sequential(# dwnn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),nn.BatchNorm2d(hidden_dim),h_swish() if use_hs else nn.ReLU(inplace=True),# Squeeze-and-ExciteSELayer(hidden_dim) if use_se else nn.Identity(),# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)else:self.conv = nn.Sequential(# pwnn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),nn.BatchNorm2d(hidden_dim),h_swish() if use_hs else nn.ReLU(inplace=True),# dwnn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),nn.BatchNorm2d(hidden_dim),# Squeeze-and-ExciteSELayer(hidden_dim) if use_se else nn.Identity(),h_swish() if use_hs else nn.ReLU(inplace=True),# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)def forward(self, x):if self.identity:return x + self.conv(x)else:return self.conv(x)class MobileNetV3(nn.Module):def __init__(self, mode='large', num_classes=1000, width_mult=1.):super(MobileNetV3, self).__init__()# setting of inverted residual blocksself.cfgs = [# k, t, c, SE, HS, s[3, 1, 16, 0, 0, 1],[3, 4, 24, 0, 0, 2],[3, 3, 24, 0, 0, 1],[5, 3, 40, 1, 0, 2],[5, 3, 40, 1, 0, 1],[5, 3, 40, 1, 0, 1],[3, 6, 80, 0, 1, 2],[3, 2.5, 80, 0, 1, 1],[3, 2.3, 80, 0, 1, 1],[3, 2.3, 80, 0, 1, 1],[3, 6, 112, 1, 1, 1],[3, 6, 112, 1, 1, 1],[5, 6, 160, 1, 1, 2],[5, 6, 160, 1, 1, 1],[5, 6, 160, 1, 1, 1]]assert mode in ['large', 'small']# building first layerinput_channel = _make_divisible(16 * width_mult, 8)layers = [conv_3x3_bn(3, input_channel, 2)]# building inverted residual blocksblock = InvertedResidualfor k, t, c, use_se, use_hs, s in self.cfgs:output_channel = _make_divisible(c * width_mult, 8)exp_size = _make_divisible(input_channel * t, 8)layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))input_channel = output_channel# building last several layerslayers.append(conv_1x1_bn(input_channel, exp_size))self.features = nn.Sequential(*layers)self.extras = nn.ModuleList([InvertedResidual(960, _make_divisible(960 * 0.2, 8), 512, 3, 2, True, True),InvertedResidual(512, _make_divisible(512 * 0.25, 8), 256, 3, 2, True, True),InvertedResidual(256, _make_divisible(256 * 0.5, 8), 256, 3, 2, True, True),InvertedResidual(256, _make_divisible(256 * 0.25, 8), 64, 3, 2, True, True),])self.reset_parameters()def forward(self, x):features = []for i in range(13):x = self.features[i](x)features.append(x)for i in range(13, len(self.features)):x = self.features[i](x)features.append(x)for i in range(len(self.extras)):x = self.extras[i](x)features.append(x)return tuple(features)def reset_parameters(self):for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))if m.bias is not None:m.bias.data.zero_()elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()elif isinstance(m, nn.Linear):n = m.weight.size(1)m.weight.data.normal_(0, 0.01)m.bias.data.zero_()@registry.BACKBONES.register('mobilenet_v3')
def mobilenet_v3(cfg, pretrained=True):model = MobileNetV3()if pretrained:model.load_state_dict(load_state_dict_from_url(model_urls['mobilenet_v3']), strict=False)return model
按照README操作即可基于自己的数据集来实现模型的开发流程,这里就不再赘述了,前面的文章中都有比较详细的介绍了。
训练完成后得到可用于推理的权重文件,可视化推理实例如下所示:

结果图像如下所示:

这里对其进行了格式化存储,如下所示:
{"crop": [[0.9846513271331787,[23,2,496,503]],[0.7338884472846985,[275,346,512,508]],[0.4537461996078491,[207,1,511,319]]]
}方便后续后端业务系统进行解析使用,感兴趣的话也都可以动手实践下!
这篇关于AI助力智慧农业,基于SSD模型开发构建田间作物场景下庄稼作物、杂草检测识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





