本文主要是介绍C#,机器学习的KNN(K Nearest Neighbour)算法与源代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
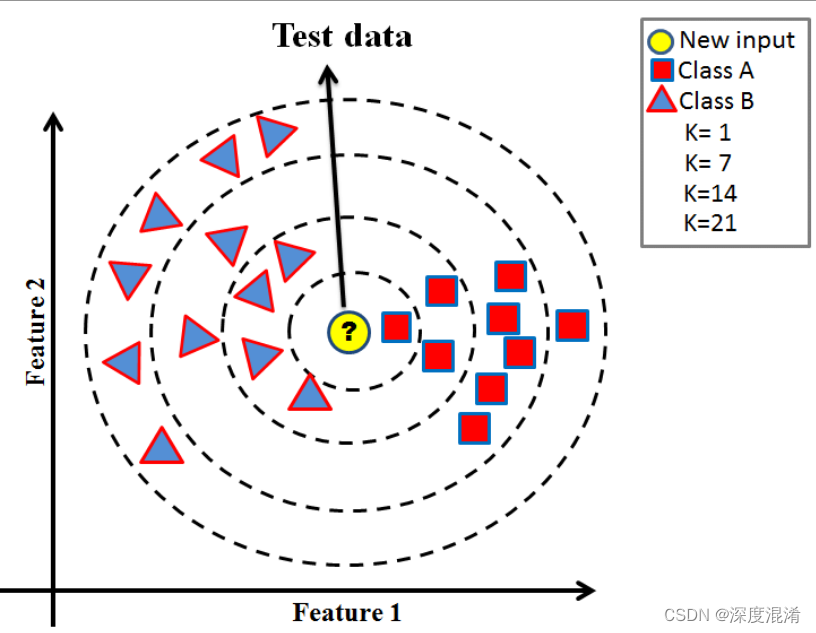
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
该方法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最邻近点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。另外还有一种 Reverse KNN法,它能降低KNN算法的计算复杂度,提高分类的效率。
KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
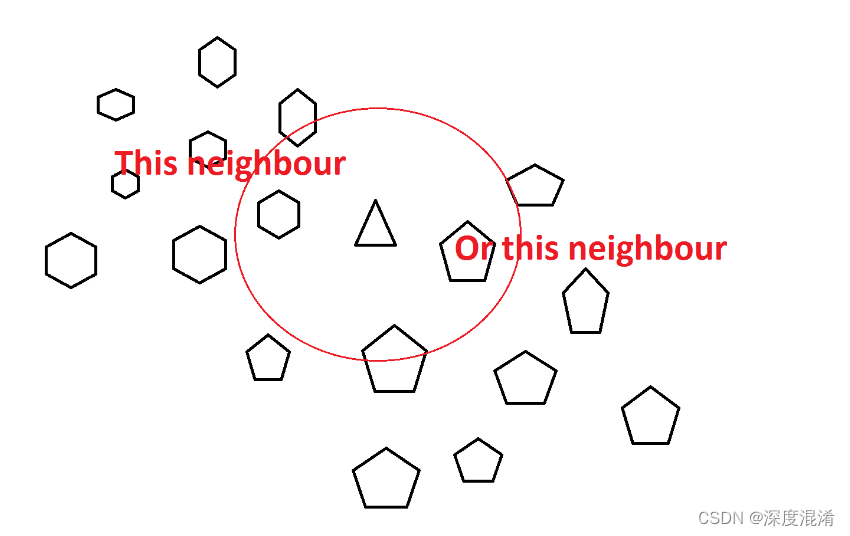
k-最近邻(KNN)算法是一种数据分类方法,用于根据最近的数据点所属的组来估计数据点成为一个组或另一个组的成员的可能性。
k-最近邻算法是一种用于解决分类和回归问题的有监督机器学习算法。然而,它主要用于分类问题。
KNN是一种延迟学习的非参数算法。
它被称为懒惰学习算法或懒惰学习者,因为当您提供训练数据时,它不会执行任何训练。相反,它只存储训练期间的数据,不执行任何计算。在对数据集执行查询之前,它不会构建模型。这使KNN成为数据挖掘的理想选择。
它被认为是一种非参数方法,因为它不对底层数据分布进行任何假设。简而言之,KNN试图通过查看数据点周围的数据点来确定数据点属于哪个组。
假设有两组,A和B。
为了确定一个数据点是在a组还是在B组中,该算法会查看其附近数据点的状态。如果大多数数据点都在A组中,则很可能所讨论的数据点在A组中,反之亦然。
简而言之,KNN涉及通过查看最近的带注释数据点(也称为最近邻点)对数据点进行分类。
不要混淆K-NN分类和K-means聚类。KNN是一种监督分类算法,它基于最近的数据点对新数据点进行分类。另一方面,K-means聚类是一种无监督聚类算法,它将数据分组为K个聚类。
 源程序
源程序
using System;
using System.Linq;
using System.Text;
using System.Collections.Generic;namespace Legalsoft.Truffer.Algorithm
{public class Sample{public double SepalLength { get; set; } = 0.0;public double SepalWidth { get; set; } = 0.0;public double PetalLength { get; set; } = 0.0;public double PetalWidth { get; set; } = 0.0;public string Species { get; set; } = "";}public class KNN_Algorithm{/// <summary>/// 样本数据/// </summary>public List<Sample> Samples { get; set; } = new List<Sample>();/// <summary>/// 未分类数据/// </summary>public List<Sample> Unclassify { get; set; } = new List<Sample>();/// <summary>/// K值/// </summary>public int K { get; set; } = 0;/// <summary>/// 构造函数/// </summary>/// <param name="sampleList">样本数据</param>/// <param name="unclassifyList">未分类数据</param>/// <param name="k">k值</param>public KNN_Algorithm(List<Sample> sampleList, List<Sample> unclassifyList, int k){Samples = sampleList;Unclassify = unclassifyList;K = k;}/// <summary>/// 分类/// </summary>public void Classify(){int sampleCount = Samples.Count;int unclassifyCount = Unclassify.Count;for (int i = 0; i < unclassifyCount; i++){Tuple<string, double>[] tupleArray = new Tuple<string, double>[sampleCount];for (int j = 0; j < sampleCount; j++){double distance = CalculateDistance(Samples[j], Unclassify[i]);string species = Samples[j].Species;tupleArray[j] = Tuple.Create(species, distance);}IEnumerable<Tuple<string, double>> selector = tupleArray.OrderBy(t => t.Item2).Take(K);Dictionary<string, int> dictionary = new Dictionary<string, int>();foreach (Tuple<string, double> tuple in selector){if (dictionary.ContainsKey(tuple.Item1)){dictionary[tuple.Item1]++;}else{dictionary.Add(tuple.Item1, 1);}}IEnumerable<KeyValuePair<string, int>> keyValuePair = dictionary.OrderByDescending(t => t.Value).Take(1);foreach (KeyValuePair<string, int> kvp in keyValuePair){Unclassify[i].Species = kvp.Key;}Samples.Add(Unclassify[i]);sampleCount++;}}/// <summary>/// 计算欧氏距离/// </summary>/// <param name="sample">样本数据</param>/// <param name="unclassify">未分类数据</param>/// <returns>两者欧氏距离</returns>public double CalculateDistance(Sample sample, Sample unclassify){double delta_SepalLength = unclassify.SepalLength - sample.SepalLength;double delta_SepalWidth = unclassify.SepalWidth - sample.SepalWidth;double delta_PetalLength = unclassify.PetalLength - sample.PetalLength;double delta_PetalWidth = unclassify.PetalWidth - sample.PetalWidth;double ds = delta_SepalLength * delta_SepalLength + delta_SepalWidth * delta_SepalWidth +delta_PetalLength * delta_PetalLength + delta_PetalWidth * delta_PetalWidth;if (ds <= float.Epsilon) return 0.0;return Math.Sqrt(ds);}}
}
POWER BY 315SOFT.COM
大约50年前被发现以来,K-最近邻方法已经发展了很长时间。现在它主要被用于文本挖掘和预测问题,并且在农业、金融和医疗等行业领域得到了应用。
1951年,Fix和Hodges设想了最近邻规则,这也是KNN的最早设想之一。随后,1962年,Sebestyen将这样KNN称作邻近算法(proximity algorithm)。1965年,KNN当时被Nilsson称作最小距离分类器(minimum distance classifier)。1967年,Cover和Hart在论文《Nearest neighbor pattern classification》中正式介绍了KNN,也是KNN的首次正式的提出。
kNN算法因其提出时间较早,随着其他技术的不断更新和完善,kNN算法的诸多不足之处也逐渐显露,因此许多kNN算法的改进算法也应运而生。针对以上算法的不足,算法的改进方向主要分成了分类效率和分类效果两方面。
分类效率:事先对样本属性进行约简,删除对分类结果影响较小的属性,快速的得出待分类样本的类别。KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分,如2006年,Zhang, H., Berg, A. C., Maire, M., & Malik, J. j.基于SVM和KNN区分最近邻分类的视觉类别。在2007年,Zhang, M. L., & Zhou, Z. H.在有限的数据中设计了对多标签数据的KNNs算法《ML-KNN: A lazy learning approach to multi-label learning》。2009年,《Fast Approximate kNN Graph Construction for High Dimensional Data via Recursive Lanczos Bisection》利用两种divide and conquer方法来近似KNN的计算。
分类效果:Stanfill和Waltz采用价值距离指标(Value Distance Metric/VDM);采用权值的方法(和该样本距离小的邻居权值大)来改进,Han等人于2001年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。2005,NCA(Neighbourhood components analysis)是将马氏距离应用于KNN算法来实现降维的效果,它主要目的是通过找到一个线性变化矩阵,来最大化leave-one-out (LOO)分类精确度。算法的关键点在于可以通过可微的目标函数f(A)来找出线性变化矩阵A,比如说使用共轭梯度法。因此,NCA被普遍应用于模型的选择,降维,结构预测,异常分析,强化学习的神经网络中。
这篇关于C#,机器学习的KNN(K Nearest Neighbour)算法与源代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




