本文主要是介绍轮盘赌算法原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
轮盘赌算法的基本思想是:各个个体被选中的概率与其适应度函数值大小成正比,它是为了防止适应度数值较小的个体被直接淘汰而提出的。
为了弄清轮盘赌算法,我搜集了相关的文献和教材,发现很多文章都喜欢把轮盘赌算法与遗传算法、蚁群算法、蜂群算法等混入一起来解释,这样轮盘赌算法中就会冒出什么染色体、遗传下一代、信息正反馈、信息素、雇佣蜂等词语,看起来“高大上”,这样也使得简单实用的轮盘赌算法在理解和实现上都变得复杂。话说,轮盘赌算法是可以应用到遗传算法、蚁群算法中去,但其算法的机理和遗传算法、蚁群算法是相互独立的,它的实现机理和遗传算法、蚁群算法、蜂群算法等没有任何关系,也没有什么染色体、遗传下一代、信息正反馈等高大上的词汇。
轮盘赌算法的核心在于两个概率和个体选择策略:
(1)个体选择概率
(2)累积概率
(3)如何选择某个个体
1、个体个体选择概率比较好理解,适应度数值越高,它被选中的概率就越大,使用以下公式来表示。
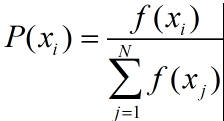
其中,xi为某个个体。
2、累积概率把各个个体的概率使用不同长度的线段来表示,这些线段组合成一条直线,直线的长度为1(各个个体概率之和),这样在该直线中,某段的线段最长,就代表该个体被选中的概率越大。它的机理为:
(一)任意选择所有个体的一个排列序列(这个序列可以随便排,因为是某线段之间的长度为代表某个体的选择概率)
(二)任意个体的累积概率为该个体对应的前几项数据的累加和。
某个个体的累加概率公式如下:
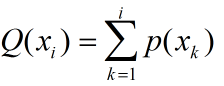
这样,如果某个个体的适应度数值高,它所对应的个体选择概率就会越大,通过累积概率转换后对应的线段会越长。
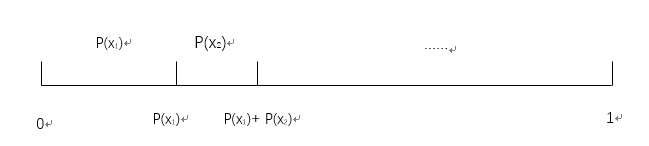
3、选择某个个体策略为在区间[0 1]中随机产生一个数,看看该数字落在那个区间,很明显,对于适应度值较大的个体,对应的线段长度会长,这样随机产生的数字落在此区间的概率就大,该个体被选中的概率也大。同时,对于适应度较小的个体,线段长度会相对较短,随机数字在该区间的概率相对较小,但是也有被选中的可能,避免了适应度数值较小的个体被直接淘汰的问题。
综上,轮盘赌算法的实现步骤为
(i)初始化各个个体的适应度值(适应度值就是某个数值,什么数据都可以,只是对于不同的问题,这个适应度值代表的意义不一样)
(ii)根据公式计算各个个体的个体选择概率和累积概率
(iii)在区间[0 1]之间随机生成一个数,判断该数落在哪个区间内,如果落在某个区间,则该区间被选中。
例子:使用轮盘赌算法根据各个个体被选中的概率与其适应度函数值大小成正比原理,使用了[0.23 0.65 0.38 0.96 0.14 0.76 0.99 0.76 0.56 0.77];%10个模拟适应度值做了实验,计算了3次,每次循环100次。根据算法思想应该为适应度值越大,该个体被选择的概率也就越大,也就是说这100次中该个体被选中的次数应该越多。
第一次: 3 8 8 16 3 17 19 9 3 14
第二次: 2 10 8 15 1 8 18 12 11 15
第三次: 4 15 3 19 6 8 14 13 9 9
可以看到,对于适应度值为0.14的个体,这3次中选中的次数分别为:3、1、6,而对于适应度为0.99的个体,这3次中选中的次数分别为:19,18,14。基本满足了轮盘赌算法的原理。轮盘赌算法matlab实现的代码如下,由于每次的判断数都是随机的,大家使用的该算法得到的测试结果肯定和上面3次的效果不一样,每次但是适应度大的个体被选中的次数一般都会多于适应度较小的个体。
这篇关于轮盘赌算法原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








