本文主要是介绍AI助力智慧农业,基于YOLOv6最新版本模型开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
智慧农业随着数字化信息化浪潮的演变有了新的定义,在前面的系列博文中,我们从一些现实世界里面的所见所想所感进行了很多对应的实践,感兴趣的话可以自行移步阅读即可:
《自建数据集,基于YOLOv7开发构建农田场景下杂草检测识别系统》
《轻量级目标检测模型实战——杂草检测》
《激光除草距离我们实际的农业生活还有多远,结合近期所见所感基于yolov8开发构建田间作物杂草检测识别系统》
《基于yolov5的农作物田间杂草检测识别系统》
自动化的激光除草,是未来大面积农业规划化作物种植生产过程中非常有效的技术手段,本文的核心思想就是基于YOLOv6模型来开发构建智能检测识别模型,首先看下实例效果:
这里是基于实验性的想法做的实践项目,数据集由自主构建,主要包含:作物和杂草两类目标对象,在后续的实际开发中,可以根据实际的业务需求来不断地增加和细化对应类别下的数据规模。
简单看下数据集:


训练数据配置文件如下所示:
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR
train: ./dataset/images/train # train images
val: ./dataset/images/test # val images
test: ./dataset/images/test # test images (optional)# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False# Classes
nc: 2 # number of classes# class names
names: ['crop', 'weed']默认我先选择的是yolov6n系列的模型,基于finetune来进行模型的开发:
# YOLOv6s model
model = dict(type='YOLOv6n',pretrained='weights/yolov6n.pt',depth_multiple=0.33,width_multiple=0.25,backbone=dict(type='EfficientRep',num_repeats=[1, 6, 12, 18, 6],out_channels=[64, 128, 256, 512, 1024],fuse_P2=True,cspsppf=True,),neck=dict(type='RepBiFPANNeck',num_repeats=[12, 12, 12, 12],out_channels=[256, 128, 128, 256, 256, 512],),head=dict(type='EffiDeHead',in_channels=[128, 256, 512],num_layers=3,begin_indices=24,anchors=3,anchors_init=[[10,13, 19,19, 33,23],[30,61, 59,59, 59,119],[116,90, 185,185, 373,326]],out_indices=[17, 20, 23],strides=[8, 16, 32],atss_warmup_epoch=0,iou_type='siou',use_dfl=False, # set to True if you want to further train with distillationreg_max=0, # set to 16 if you want to further train with distillationdistill_weight={'class': 1.0,'dfl': 1.0,},)
)solver = dict(optim='SGD',lr_scheduler='Cosine',lr0=0.0032,lrf=0.12,momentum=0.843,weight_decay=0.00036,warmup_epochs=2.0,warmup_momentum=0.5,warmup_bias_lr=0.05
)data_aug = dict(hsv_h=0.0138,hsv_s=0.664,hsv_v=0.464,degrees=0.373,translate=0.245,scale=0.898,shear=0.602,flipud=0.00856,fliplr=0.5,mosaic=1.0,mixup=0.243,
)
终端执行:
python tools/train.py --batch-size 16 --conf configs/yolov6n_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6n --epochs 100 --workers 2即可启动训练。
日志输出如下所示:
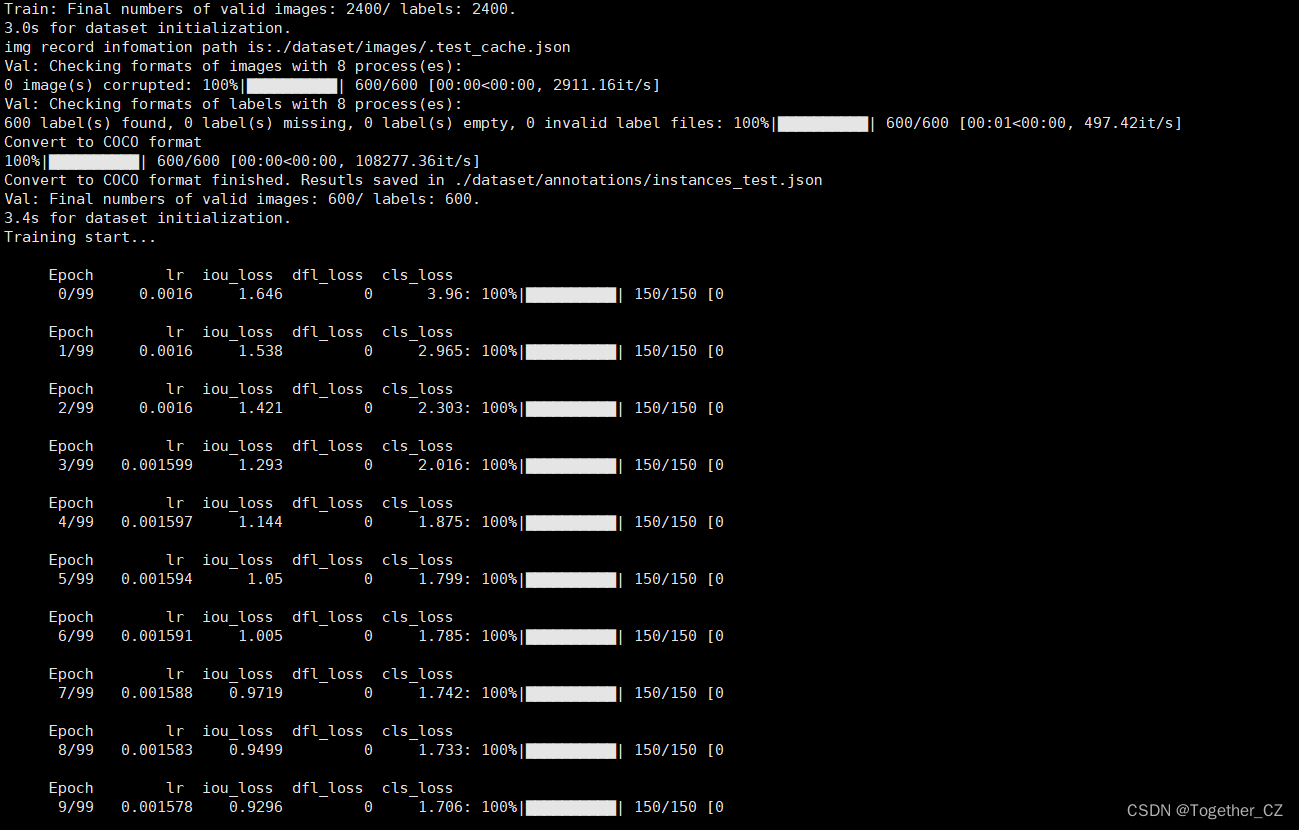
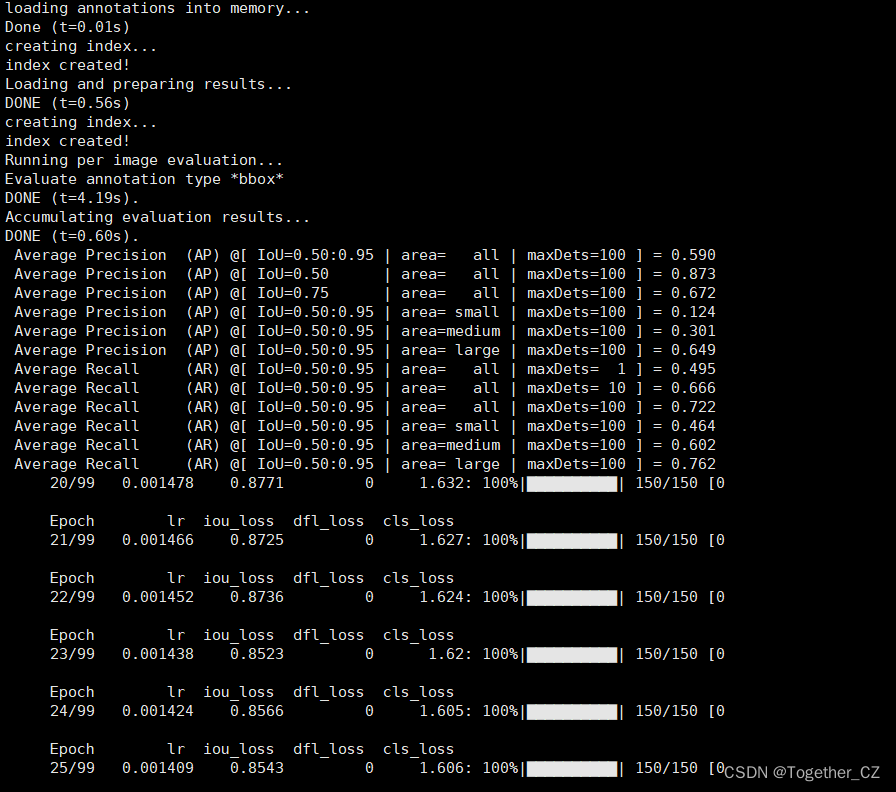
等待训练完成之后,我们来整体看下结果详情:
Training completed in 1.585 hours.
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
Loading and preparing results...
DONE (t=0.21s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=2.20s).
Accumulating evaluation results...
DONE (t=0.31s).Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.657Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.924Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.749Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.177Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.303Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.717Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.527Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.714Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.758Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.391Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.653Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.798
args详情如下:
data_path: data/self.yaml
conf_file: configs/yolov6n_finetune.py
img_size: 640
rect: false
batch_size: 16
epochs: 100
workers: 2
device: '0'
eval_interval: 20
eval_final_only: false
heavy_eval_range: 50
check_images: false
check_labels: false
output_dir: ./runs/train
name: yolov6n
dist_url: env://
gpu_count: 0
local_rank: -1
resume: false
write_trainbatch_tb: false
stop_aug_last_n_epoch: 15
save_ckpt_on_last_n_epoch: -1
distill: false
distill_feat: false
quant: false
calib: false
teacher_model_path: null
temperature: 20
fuse_ab: true
bs_per_gpu: 32
specific_shape: false
height: null
width: null
cache_ram: false
rank: -1
world_size: 1
save_dir: runs/train/yolov6n
结果文件如下所示:
可视化推理实例如下所示:
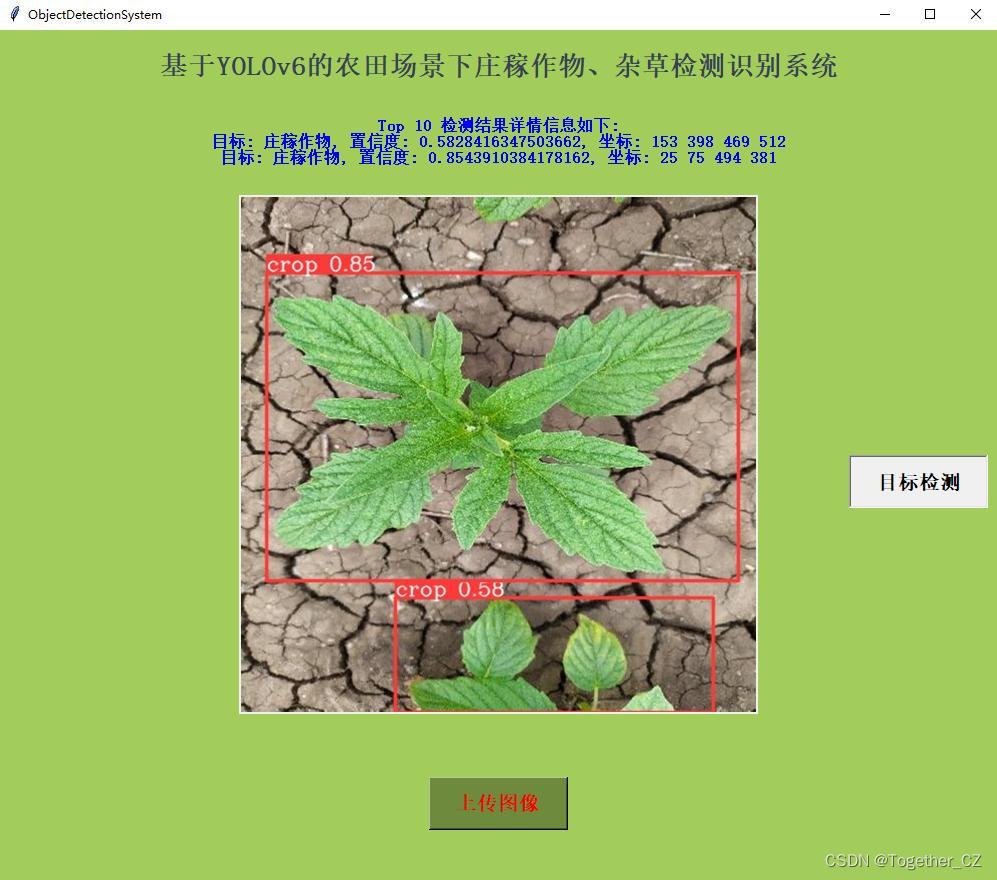
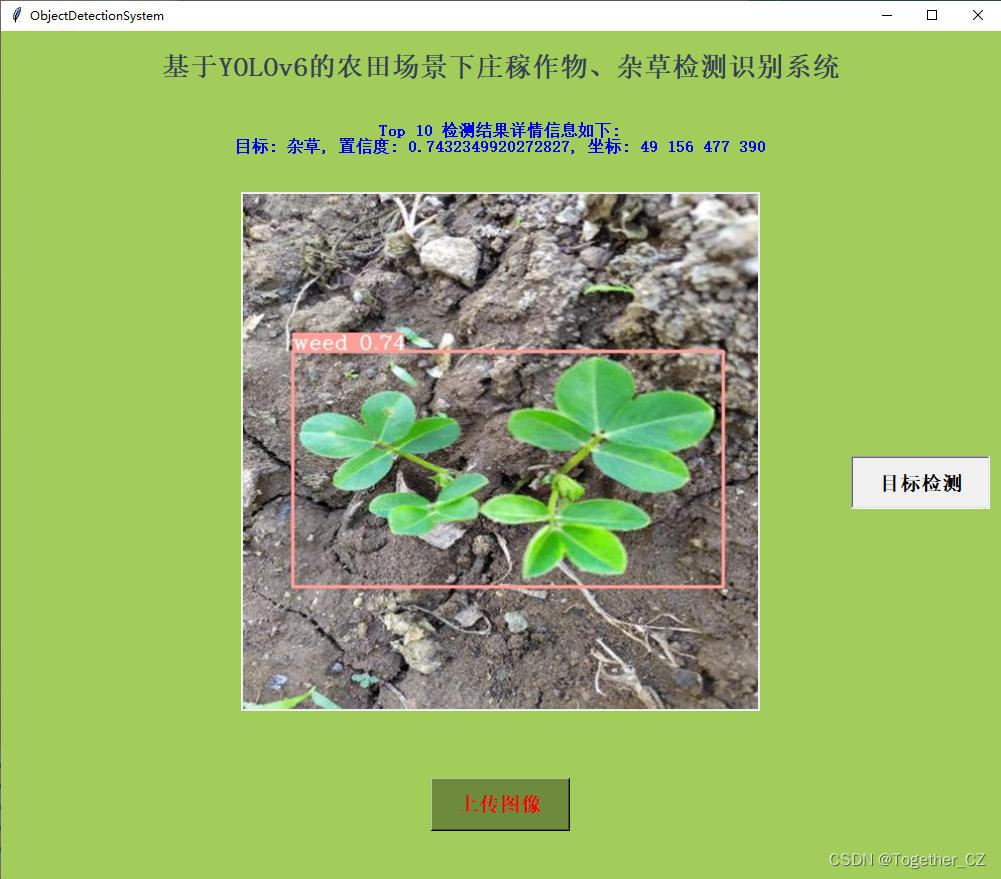
感兴趣的话也都可以自行尝试一下!
这篇关于AI助力智慧农业,基于YOLOv6最新版本模型开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





