本文主要是介绍数学建模-数据新动能驱动中国经济增长的统计研究-基于数字产业化和产业数字化的经济贡献测度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据新动能驱动中国经济增长的统计研究-基于数字产业化和产业数字化的经济贡献测度
整体求解过程概述(摘要)
伴随着数据要素化进程的不断加深,对于数据如何作用于经济发展,数据与其他要素结合产生的动能应该如何测度的研究愈发重要。本文将数据新动能分解为“数字产业化”与“产业数字化”两个角度来对其进行统计测度,以更好地去理解数据是如何赋能与其他要素,助力我国数字经济高质量发展。
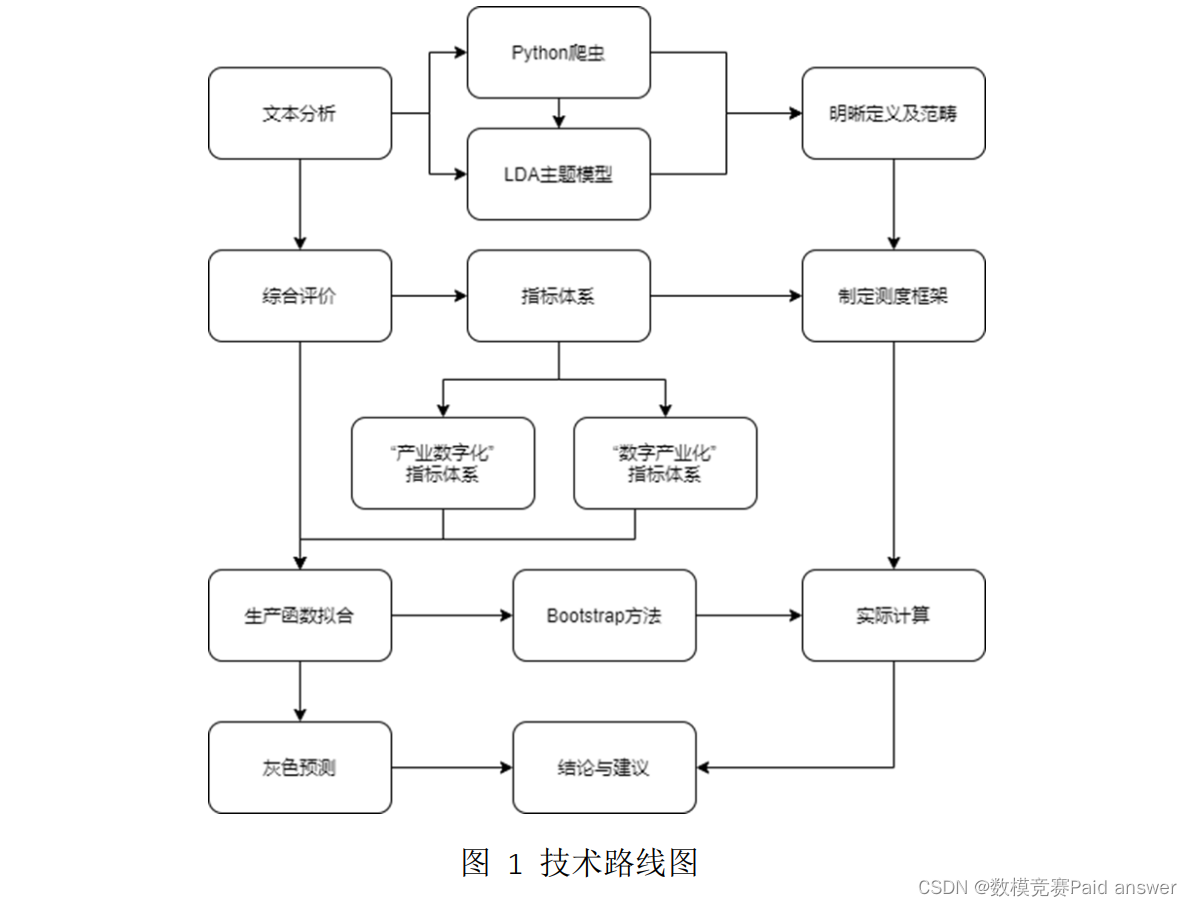
本文首先进行了文本分析,利用爬虫从知网、百度资讯上抓取相关文献,经过预处理、清洗、分词后,从词云图获取到文献聚焦的热点。在对分词后的建立“文档-词项”矩阵与 TI-IDF,并根据 TI-IDF 的结果建立 lda 主题模型,最终得到“数据要素”“技术创新”“宏观政策”“转型升级”“交易模型”“数据监管”六大主题,为后续问题的探讨明确了方向。
之后我们选择依据经济原理,通过综合评价来构建与“数字产业化”与“产业数字化”相对应的指标体系并使用柯布-道格拉斯生产函数,对“数字产业化”进行投入产出分析,通过 bootstrap 方法拟合方程计算得出各种生产要素在数据产业中的贡献率,并计算出相对应的“产业数字化”生产函数,通过数学变换分析得出了相应的数据要素对于劳动力,资本,科技的作用,来使得我们以更好地理解、分析“数字产业化”和“产业数字化”共同作用下的经济合力——数据新动能。
问题分析
本次建模所要研究的主要问题,就是探索测度数据赋能经济而产生新动能的方式,希望能够寻找到部分具有较强代表性,较高准确性的测度指标,找到一种合适的方式,来对数据要素这一新兴生产要素在对经济赋能过程中所产生的价值进行测度,助力数字产品与服务市场规范化,激发数据产业新动能,更好的发挥数据驱动新消费的作用,推动我国数字经济新发展。
本文接下来将进行数据新动能驱动经济增长的机理探索,基于文本挖掘的方法来对数据新动能进行解析,并对数据新动能及相关概念界定,分析数据新动能、“数字产业化”和“产业数字化”的关系与相互作用。之后我们将进行数据要素赋能中国经济增长的统计模型构建,并将其分为“数字产业化”评价指标体系和“产业数字化”评价指标体系进行设计。
基于这两个评价指标体系,我们将构建“数字产业化”和“产业数字化”的生产模型进行分析,并利用这一模型来进行数据要素赋能中国经济增长的测度分析,最后我们将根据我们研究的结果得出相关结论,并提出相关建议,助力数字化要素发展,让数据新动能使我国经济发展迸发出新的活力。
模型的建立与求解
为了更好的了解和界定数据新动能,本文进行了文本分析,利用 Python 爬虫从知网、百度资讯上抓取相关文献,经过预处理后,共计获得文章 622 篇。在对文本进行清洗、分词后,按照词频制作词云图,从词云图获取到文献聚焦的热点。在对分词后的建立“文档-词项”矩阵与 TI-IDF,并根据 TI-IDF 的结果建立lda 主题模型,以便从中获取主题,为后续问题的研究提供思路。通过文本分析后我们发现数据新动能由于各方面存在的很大的宽泛性和不确定性,直接测度没有标准,测度难度较大,所以我们选择使用综合评价体系来进行指标设计,从侧面进行测度。通过数据新动能作用方式将其划分为“数字产业化”“产业数字化”两部分分别进行测度,并将其拟合成生产函数的形式,利用数学变换来进行数据赋能的测度。
在拟合生产函数的过程中,由于数据量过少,部分指标统计近些年来才开始统计,我们使用了插值法来进行空值补全。为了解决模型拟合中由于数据量过少,大部分变量不显著的问题,我们通过 R 语言使用了对样本及其分布要求较低的bootstrap 方法来近似扩大样本的过程,进行 1500 次重抽样来进行方程参数的估计。最终拟合出较为准确的回归方程,并进行下一步的灰色预测来对指标体系中的指标进行进一步预测。
最后,我们根据上述结果进行分析并提出了相关的建议,希望能助力于我国数字经济的发展,使我国经济迸发出更多的数据新动能。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
(代码和文档not free)
import os
import numpy as np
import numpy.linalg as nplg
import scipy.optimize as spopt
import matplotlib.pyplot as plt
import scipy.interpolate as spidef zje_dp_objective(x,alpha, beta, delta,kgrid,pp, pp2, pp3):c = np.power(kgrid, alpha) + (1 - delta) * kgrid - xy = - np.sum(np.log(c) + beta * pp(x))return ydef zje_dp_objective_jac(x,alpha, beta, delta,kgrid,pp, pp2, pp3):c = np.power(kgrid, alpha) + (1 - delta) * kgrid - xyp = np.power(c, -1) - beta * pp2(x)return ypdef zje_dp_objective_hes(x,alpha, beta, delta,kgrid,pp, pp2, pp3):c = np.power(kgrid, alpha) + (1 - delta) * kgrid - xydp = np.diag(np.power(c, -2) - beta * pp3(x))return ydpdef zje_dp_pchip(alpha, beta, delta,m_kgrid, m_kgrid2,iternum,figurepath=None):'''dynamic programming with pchip'''kbar = np.power(alpha * beta / (1 - beta * (1 - delta)), 1 / (1 - alpha))kl = 0.75 * kbarkh = 1.25 * kbarkgrid = np.linspace(kl, kh, m_kgrid)v2 = np.log(kgrid)optk2 = kgridlb = np.ones(m_kgrid) * kgrid[0]ub = np.power(kgrid, alpha) + (1 - delta) * kgrid - 1e-06for kkk in range(iternum):v = v2optk = optk2pp = spi.pchip(kgrid, v)pp2 = pp.derivative(1)pp3 = pp.derivative(2)x0 = optkres = spopt.minimize(zje_dp_objective, x0,jac=zje_dp_objective_jac,hess=zje_dp_objective_hes,method="trust-exact",bounds=(lb, ub),args=(alpha, beta, delta, kgrid, pp, pp2, pp3,))optk2 = res.xoptc = np.power(kgrid, alpha) + (1 - delta) * kgrid - optk2v2 = np.log(optc) + beta * pp(optk2)vdiff = nplg.norm(v2 - v)kdiff = nplg.norm(optk2 - optk)if (vdiff < 1e-08 and kdiff < 1e-08):breakkspace = np.linspace(kgrid[0], kgrid[m_kgrid - 1], m_kgrid2)pp = spi.pchip(kgrid, optk2)kp = pp(kspace)c = np.power(kspace, alpha) + (1 - delta) * kspace - kpkpp = pp(kp)cp = np.power(kp, alpha) + (1 - delta) * kp - kppee = 1 - beta * np.power(cp, -1) * (alpha * np.power(kp,alpha - 1) + 1 - delta) / np.power(c, -1)fig = plt.figure(figsize=(16, 9))plt.plot(kspace, np.log10(np.abs(ee)))title = "zje_dp_pchip-eulereuqtionerrors.png"plt.title(title, fontsize=20)plt.grid()plt.show()if figurepath is not None:fig.savefig(os.path.join(figurepath, title), dpi=300)fig = plt.figure(figsize=(16, 9))plt.plot(kspace, kp)plt.plot(kspace, kspace, 'k--')title = "zje_dp_pchip-k&kp.png"plt.title(title, fontsize=20)plt.grid()plt.show()if figurepath is not None:fig.savefig(os.path.join(figurepath, title), dpi=300)return optk2, kspace, kp, kpp, c, cp, eeif __name__ == "__main__":alpha = 0.36beta = 0.99delta = 0.025m_kgrid = 31m_kgrid2 = 10001iternum = 2000figurepath = "../figure"zje_dp_pchip(alpha, beta, delta,m_kgrid, m_kgrid2,iternum,figurepath=figurepath)
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
这篇关于数学建模-数据新动能驱动中国经济增长的统计研究-基于数字产业化和产业数字化的经济贡献测度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






