本文主要是介绍二叉树——堆(C语言,配图,例题详解,TopK问题+堆排序),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 二叉树的顺序存储结构
2. 堆的概念和性质
3. 堆的实现
3.1 向下调整法
3.2 堆的创建
3.3 建堆的时间复杂度:
3.3 堆的插入
3.4 堆的删除
3.5 代码实现
4. TopK问题
5. 堆排序
数据结构入门————树(C语言/零基础/小白/新手+模拟实现+例题讲解)
对上述文章中,堆的概念描述可能不清楚,为了方便大家更好的理解,这里对堆进行详细的讲解,其中包括了堆的实现,应用等。如果你对树的一系列概念还不是很熟悉,可以从链接文章中进行阅读了解。
1. 二叉树的顺序存储结构
普通二叉树是不适合用数组来存储,因为可能会造成大量空间的浪费,而完全二叉树更适合使用顺序存储结构。现实中通常把堆(一种二叉树)使用顺序存储结构的数组来存储,需要注意的是,这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
2. 堆的概念和性质

简单理解,堆就是一种完全二叉树的顺序存储结构的对象。
堆的性质:
1. 堆是一棵完全二叉树。
2. 堆中每个节点的值总是不大于或不小于它的父节点。
根据堆的性质,可以将堆分为:大堆 小堆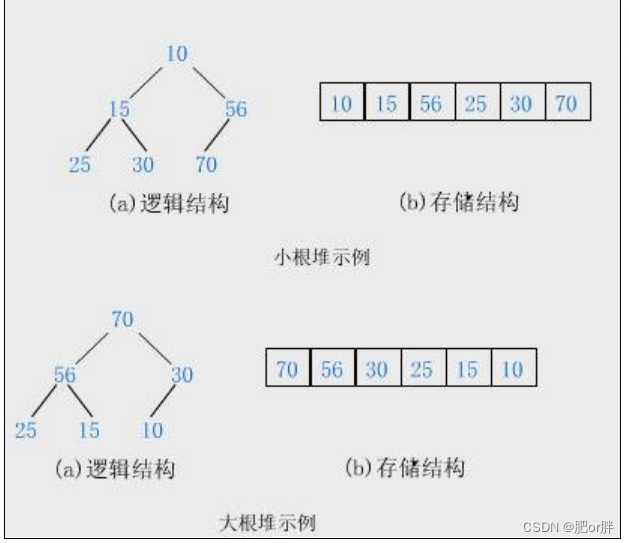
1. 下列关键字序列为堆的是:( A )A 100 , 60 , 70 , 50 , 32 , 65B 60 , 70 , 65 , 50 , 32 , 100C 65 , 100 , 70 , 32 , 50 , 60D 70 , 65 , 100 , 32 , 50 , 60E 32 , 50 , 100 , 70 , 65 , 60F 50 , 100 , 70 , 65 , 60 , 32解析:对于这种题目,我们最好的办法就是将每个节点依次试一遍。堆中每个节点总是不大于或不小于它的父节点。B. 70 > 60 , 子节点70大于父节点60,50 < 70 ,子节点50小于父节点70C. 65 < 70 , 子节点65小于父节点70, 100 > 70 ,子节点100大于父节点70D.100>50 ,子节点100大于父节点50,65<100 ,子节点65小于父节点100
3. 堆的实现
3.1 向下调整法
int array[] = {27,15,19,18,28,34,65,49,25,37};我们给出一个数组,逻辑上可以看做一颗完全二叉树,我们通过从根节点开始向下调整可以把把调整成一个小堆,向下调整算法有一个前提:左右子树必须是一个堆,才能调整。

所以实践中,我们一般从倒数第一个非叶子节点的子树开始,从下到上,依次进行向下调整,每次调整都将下面的子树调整成为堆。
3.2 堆的创建
下面我们给出一个数组,数组逻辑上可以看做一棵完全二叉树树,但还不是一个堆,现在我们通过算法,把它构建成为一个堆。我们从第一个非叶子节点的子树开始调整,一直调整到根节点的树,就可以调整成堆。
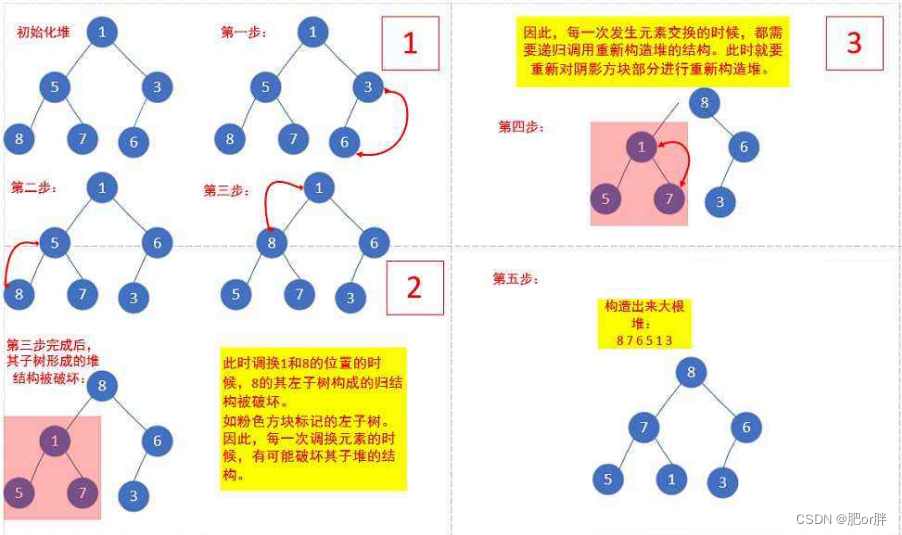
3.3 建堆的时间复杂度:
这是一个等差数列求和,如果感兴趣,可以自己计算一下,这里我们直接得出结论:
向下调整算法 建堆的时间复杂度:O (N)
向上调整算法 建堆的时间复杂度:O(N * logN)
3.3 堆的插入
先插入到数组尾中,在进行向上调整算法,直到满足堆。向上调整算法也必须满足,前面的子树满足堆。
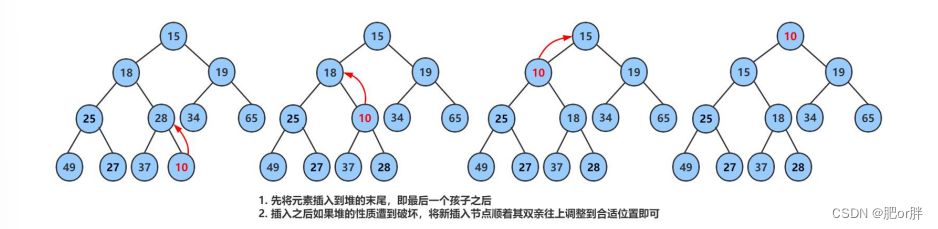
3.4 堆的删除
删除堆就是删除堆顶的数据,将堆顶的数据和最后一个数据交换,然后删除数组中最后一个数据,在进行向下调整算法。

3.5 代码实现
//Heap.h
typedef int HPDataType;
typedef struct Heap
{HPDataTyp *int _sizeint _capa
}Heap;
// 堆的构建
void HeapCrea e eap p, a aType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);#include "Heap.h"void Swap(HPDataType* x1, HPDataType* x2)
{HPDataType x = *x1;*x1 = *x2;*x2 = x;
}void AdjustDown(HPDataType* a, int n, int root)
{int parent = root;int child = parent*2+1;while (child < n){// 选左右孩纸中大的一个if (child+1 < n && a[child+1] > a[child]){++child;}//如果孩子大于父亲,进行调整交换 if(a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent*2+1;}else{break;}}
}void AdjustUp(HPDataType* a, int n, int child)
{int parent;assert(a);parent = (child-1)/2;//while (parent >= 0)while (child > 0){//如果孩子大于父亲,进行交换if (a[child] > a[parent]){Swap(&a[parent], &a[child]);child = parent;parent = (child-1)/2;}else{break;}}
}void HeapInit(Heap* hp, HPDataType* a, int n)
{int i;assert(hp && a);hp->_a = (HPDataType*)malloc(sizeof(HPDataType)*n);hp->_size = n;hp->_capacity = n;for (i = 0; i < n; ++i){hp->_a[i] = a[i];}// 建堆: 从最后一个非叶子节点开始进行调整// 最后一个非叶子节点,按照规则: (最后一个位置索引 - 1) / 2// 最后一个位置索引: n - 1// 故最后一个非叶子节点位置: (n - 2) / 2for(i = (n-2)/2; i >= 0; --i){AdjustDown(hp->_a, hp->_size, i);}
}void HeapDestory(Heap* hp)
{assert(hp);free(hp->_a);hp->_a = NULL;hp->_size = hp->_capacity = 0;
}void HeapPush(Heap* hp, HPDataType x)
{assert(hp);//检查容量if (hp->_size == hp->_capacity){hp->_capacity *= 2;hp->_a = (HPDataType*)realloc(hp->_a, sizeof(HPDataType)*hp->_capacity);}//尾插hp->_a[hp->_size] = x;hp->_size++;//向上调整AdjustUp(hp->_a, hp->_size, hp->_size-1);
}void HeapPop(Heap* hp)
{assert(hp);//交换Swap(&hp->_a[0], &hp->_a[hp->_size-1]);hp->_size--;//向下调整AdjustDown(hp->_a, hp->_size, 0);
}HPDataType HeapTop(Heap* hp)
{assert(hp);return hp->_a[0];
}int HeapSize(Heap* hp)
{return hp->_size;
}int HeapEmpty(Heap* hp)
{return hp->_size == 0 ? 0 : 1;
}void HeapPrint(Heap* hp)
{int i;for (i = 0; i < hp->_size; ++i){printf("%d ", hp->_a[i]);}printf("\n");
}
4. TopK问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。1. 用数据集合中前 K 个元素来建堆:● 前k 个最大的元素,则建小堆● 前k 个最小的元素,则建大堆2. 用剩余的 N-K 个元素依次与堆顶元素来比较,不满足则替换堆顶元素
这里我们使用rand函数创建10万个数,范围是0 ~ 99999,放到文化中,然后单独操作几个数,使得这几个数大于100000,然后输出,堆中的这几个数据,看看是不是TopK。
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <time.h>void CreateFile()
{srand(time(0));const char* file = "test.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen");return;}for (int i = 0;i < 10000;i++){int x = rand() % 10000;fprintf(fin,"%d\n", x);}fclose(fin);
}void Swap(int* p1, int* p2)
{int temp = *p1;*p1 = *p2;*p2 = temp;
}void AdjustDown(int* a, int size, int parent)
{int child = parent * 2 + 1;while (child < size){if (child + 1 < size && a[child] > a[child + 1]){child++;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
void AdjustUp(int* a, int child)
{int parent = (child - 1) / 2;while (child > 0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
void PrintTopK(int k)
{// min:大堆 max:小堆int* a = (int*)malloc(sizeof(int) * k);assert(a);int x = 0;const char* file = "test.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen");return;}for (int i = 0;i < k;i++){fscanf(fout,"%d",&a[i]);}//建堆for (int i = (k - 2) / 2;i >= 0;i--){AdjustDown(a, k, i);}//选数while (fscanf(fout,"%d", &x) != EOF){if (a[0] < x){a[0] = x;AdjustDown(a, k, 0);}}for (int i = 0;i < k;i++){printf("%d ", a[i]);}fclose(fout);
}int main()
{CreateFile();PrintTopK(5);return 0;
}5. 堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:1. 建堆● 升序:建大堆● 降序:建小堆2. 利用堆删除思想来进行排序建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
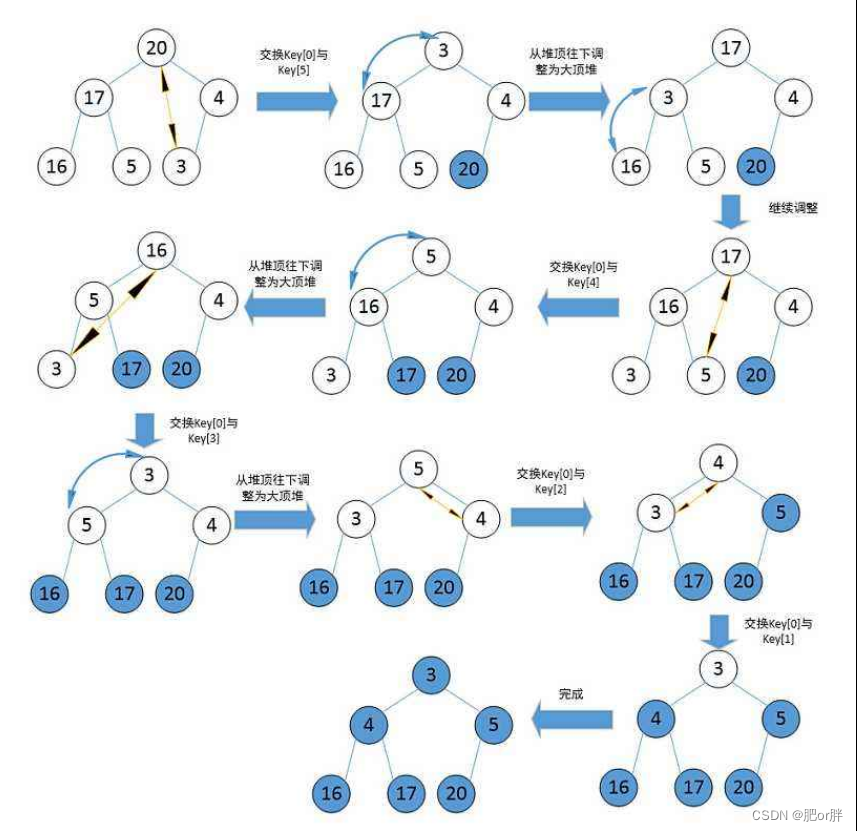
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>void Swap(int* p1, int* p2)
{int temp = *p1;*p1 = *p2;*p2 = temp;
}//向下调整
void AdjustDown(int* a, int size, int parent)
{int child = 2 * parent + 1;while (child < size){if(child+1 < size && a[child] > a[child+1]){child++;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}void Heapsort(int* a, int size)
{assert(a);assert(size > 0);//建堆for (int i = (size - 2) / 2;i >= 0;i--){AdjustDown(a, size, i);}//选数int end = size - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}int main()
{int a[9] = { 3,6,1,2,4,5,7,9,8 };Heapsort(a, sizeof(a) / sizeof(int));for (int i = 0;i < 9;i++){printf("%d ", a[i]);}return 0;
}这篇关于二叉树——堆(C语言,配图,例题详解,TopK问题+堆排序)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





