本文主要是介绍京东数据分析(京东数据运营):2023年10月咖啡市场销售数据分析(商家销量销额店铺数据),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着我国经济的发展及人们消费观念、消费习惯的变化,咖啡消费越来越成为一种时尚生活方式,国内咖啡市场也在快速增长。且在当前互联网新零售的背景下,线上咖啡市场也愈加繁荣。
根据鲸参谋电商数据分析平台的相关数据显示,今年10月份,京东平台上咖啡市场的销量为350万+,环比增长约25%,同比增长约16%;销售额将近2.6亿,环比增长约18%,同比增长约33%。可以看到,环同比来看,线上咖啡市场的销量销额都在增长。
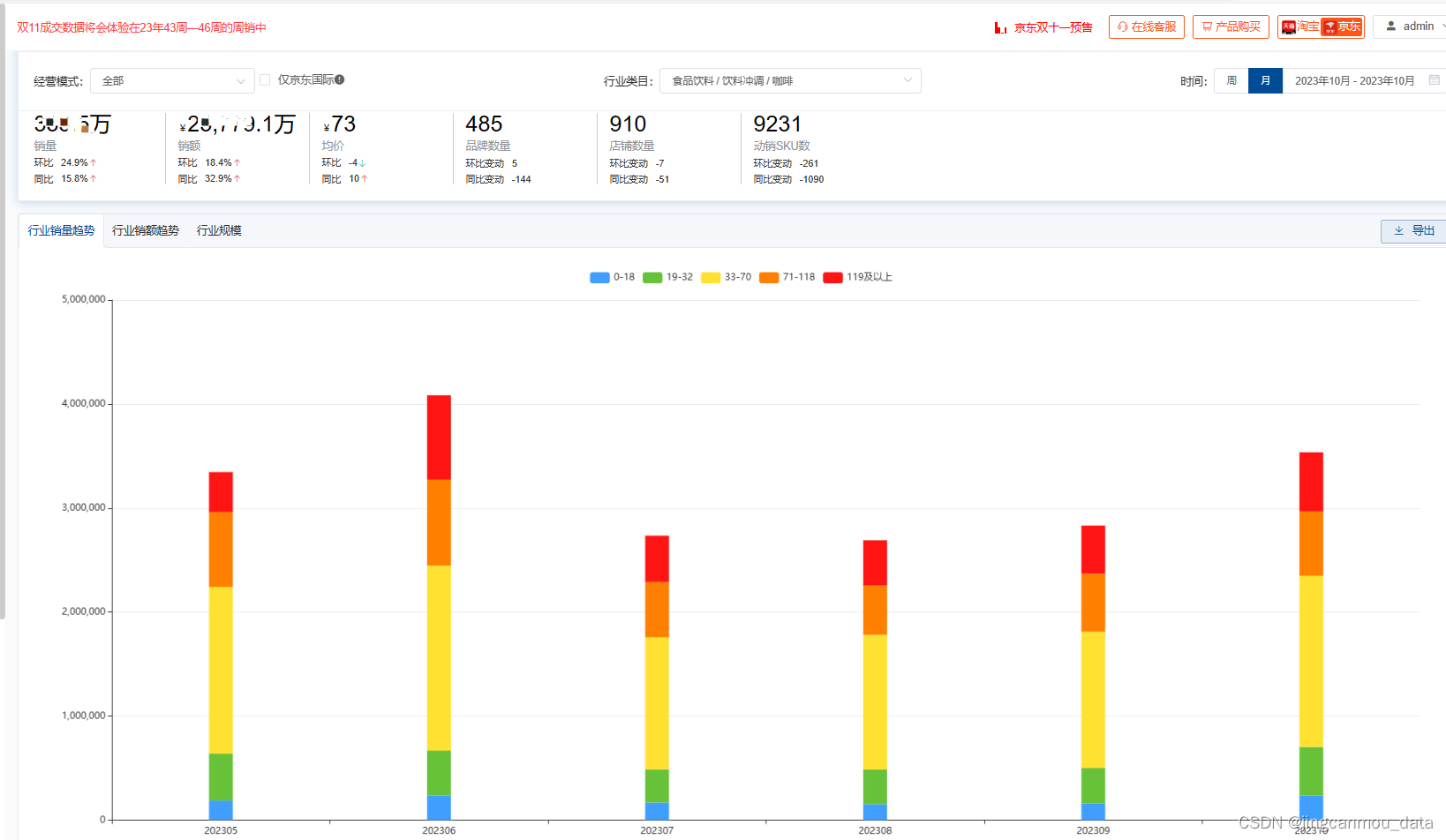
*数据源于鲸参谋-行业趋势分析(来自公开渠道获取与统计,数据仅供参考)
当前在线上咖啡市场中,产品主要有速溶咖啡、咖啡豆、胶囊咖啡、挂耳咖啡和咖啡液。速溶咖啡在市场中的占比过半,鲸参谋数据显示,今年10月份,速溶咖啡的销量将近210万,占比约59%;销售额超过1.4亿,占比约55%。
伴随消费升级,除速溶咖啡外,咖啡豆及胶囊咖啡、挂耳咖啡等新式速溶咖啡的热度也不断升高,在市场中也占据一定的份额。其中,咖啡豆在10月份的销售额将近3400万,占比为13%;胶囊咖啡的销售额为2400万+,占比约9%;挂耳咖啡在市场中的月销额约1400万,占比约5%。

*数据源于鲸参谋-属性分析(来自公开渠道获取与统计,数据仅供参考)
从品牌角度来看,当前在线上咖啡市场中,雀巢仍以先发优势牢牢占据第一位置,10月份,雀巢咖啡的月销额为6200万+,市场占比高达24%。其次是星巴克和瑞幸咖啡,两品牌的月销额分别约为2400万和1800万,市场占比分别约9%和7%。
此外,随着咖啡市场的不断火热,近年来市场中一些新锐品牌也不断崛起,如三顿半和隅田川等。根据鲸参谋平台的数据显示,以三顿半和隅田川为代表的新锐咖啡品牌在市场中的受欢迎程度仅次于雀巢、星巴克和瑞幸,市场占比分别约5%和3%。

*数据源于鲸参谋-品牌排行分析(来自公开渠道获取与统计,数据仅供参考)
从产品价格角度来看,市场中高价咖啡更加热卖。从数据来看,处在“119元及以上”这一价格区间的产品交易额将近1.1亿元,市场占比约为41%,占比排名第一。
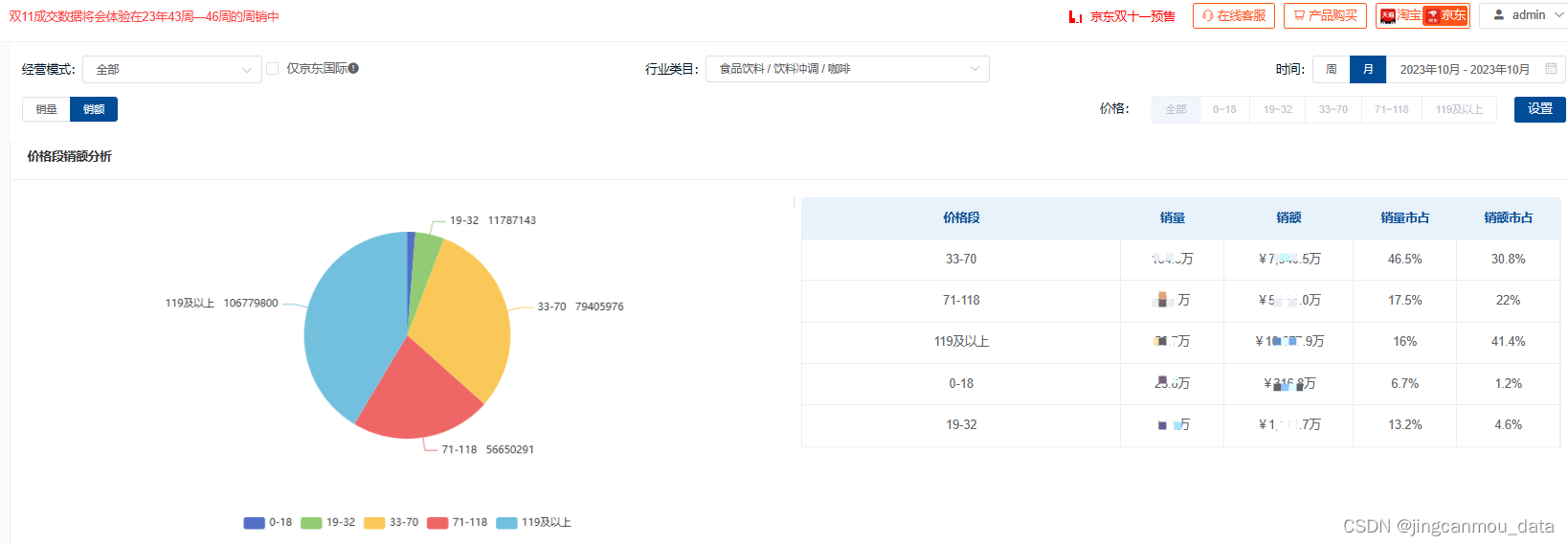
*数据源于鲸参谋-价格段分析(来自公开渠道获取与统计,数据仅供参考)
如今,随着城镇化进程加快、国民收入水平的提高,咖啡逐渐从基本的提神醒脑需求演变为社交需求,咖啡消费理念得以持续培育,这将进一步推动国内咖啡行业的持续增长。
同时,当前在互联网新零售的背景下,咖啡市场的竞争也逐渐愈演愈烈,因此,咖啡企业也应不断探索与升级,以此来应对市场新挑战、顺应咖啡新零售潮流。
鲸参谋数据来源于公开渠道,数据获取与统计可能存在不完整,仅供参考。
如想要查看京东(淘宝/天猫)全品类的销售数据(行业/品牌/店铺/商品/监控),欢迎搜索“鲸参谋电商数据”,或者直接评论留言和私信(也可接口对接)~
这篇关于京东数据分析(京东数据运营):2023年10月咖啡市场销售数据分析(商家销量销额店铺数据)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




