本文主要是介绍mysql truncsysdate_一日一句 SQL [持续更新] MySQL + Oracle,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 . group by 和 having字句: group by是根据列值对数据进行分组, having子句用于对分组的数据进行过滤. [ having 针对的对象是分好的组]
eg:
employee表: uuid emp_name emp_id dept_id
dept表: uuid dept_name dept_id
查询至少包含两个雇员的部门名称: select d.dept_name, d.dept.id, count(e.emp_id) emp_sum --这里统计可以使用*号,但是建议使用具体的列,速度上会快一点
from employee e left joindept don e.dept_id =d.dept_idgroup byd.namehaving count(e.emp_id) >= 2; --统计每组的人数,即部门人数
2 . Order by 子句
order by 子句用于对结果集中的原始列数据或是根据列数据计算的表达式的结果进行排序 .
默认是升序, 加上 desc 关键字就是降序了.
多条件排序只需把条件用逗号分割即可.
eg:
account表:
uuid
name
account
id
查询所有用户,结果按 account 降序:
select *
fromaccountorder by account desc;
根据表达式排序:
假设 account 表中 id 列为这样的数据 111-111-111, 和银行卡编号类似.
选择需要按照 id 后三位进行排序:
select *
fromaccountorder by right(id, 3) desc;
根据内建函数 right() 提取 id 字段的最后三个字符, 并根据该值对结果集进行排序.
3 . 聚集函数
提到聚集函数, 必须提到分组, 分组就联想到了 group by 语句. [ 使用 group by 是显示分组 ]
聚集函数是对某个分组的所有行进行特定的操作.
如下聚集函数:
Max() : 返回集合中最大值
Min() : 返回集合中最小值
Avg() : 返回集合中的平均值
Count() : 返回集合中值的个数
在上面提到了显示分组, 那么一定就还有隐式分组, 也就是不使用 group by 语句, 比如下面的 sql:
eg:
员工表 employee
uuid
name
emp_id
emp_age
emp_location
查询 emp_location 是杭州市的员工的最小年龄, 最大年龄, 平均年龄 :
select min(emp_age) min_age,max(emp_age) max_age,avg(emp_age) avg_agefromemployeewhere emp_location = "杭州";
上面没有使用分组语句, 但是却可以使用聚集函数, 那是因为 where 相当于了一个隐式分组, 结果集中只有一个组, 那就是emp_location="杭州" 这一组.
4 . distinct 关键字
用于除去集合中列中的重复值, 留下不重复的值, 用于统计 .
eg:
查询选课表中一共有多少学生选了课 :
选课表 SC :
uuid
c_id
s_id
select count(distincts_id)from SC;
注意 :
如果 distinct 关键字后有多个列, distinct 关键字的作用并不是保证离他最近的那一列保证不重复, 而是保证所有列的组合保证不重复 .
5 . as 关键字的使用
as 关键字用于取别名, 可以给表取别名, 也可以给列取别名, 可以被省略 . 但是有一点, 别名尽量使用双引号包裹, 如果别名中包含特殊字符就会出错 .
给列取别名有三种方式 : [ 推荐使用中间的 ]
select name as "姓名", age "年龄", sex 性别 --这里使用了三种取别名的方式, 推荐使用第二种
from users
给表取别名, 就使用第二种或者第三种都可以, 使用第三种时要保证别名中不包含特殊字符 .
SQL的优化:
少使用星号*, 多使用列名
多使用嵌套查询代替表连接查询
Oracle数据库判空函数:
在 Oracle数据中, 对于 null 有两点 :
包含 null 的表达式都是null
null 永远都 != null
对于第一点, 解决 null 值, 有两个函数 nvl(colName, defaultValue) 和nvl2() ;
对于第二点, 解决办法是不使用等号, 而是使用 is 关键字 ;
Oracle 数据库的 spool 语句:
如果需要对接下来的 sql操作进行记录的话, 可以使用spool 语句, 在开始的时候输入 :
spool D:sql记录.txt
这里的意思是将记录放在 D 盘的 sql记录.txt 文件中, 在结束的时候输入:
spool off
Oracle 数据库中的 round, trunc 函数:
round函数用于数值和日期的四舍五入, trunc用于截断数值或者时间 . [ trunc相对于 round只是少了四舍五入的功能 ]
对于数值 :
--四舍五入, 保留若干有效数字
select round(52.45, 2) "四舍五入, 保留两位小数",round(52.45, 0) "四舍五入, 只留整数",round(52.45, -1) "四舍五入, 保留两位整数",round(52.45, -2) "四舍五入, 保留三位整数"from dual;

连接虚拟机中 xp系统中安装的 Oracle数据库步骤 :
在本机环境变量中添加 sqlplus.exe的环境变量
打开本机命令行, 键入 sqlplus scott/tiger@192.168.83.128:1521/orcl 其中, scott是 Oracle中默认存在的一个用户, tiger是我们设置的密码, 一般将 scott 用户的密码设置为 tiger, ip地址是虚拟机中xp系统的ip地址, 端口默认是1521, orcl是Oracle中存在的数据库.
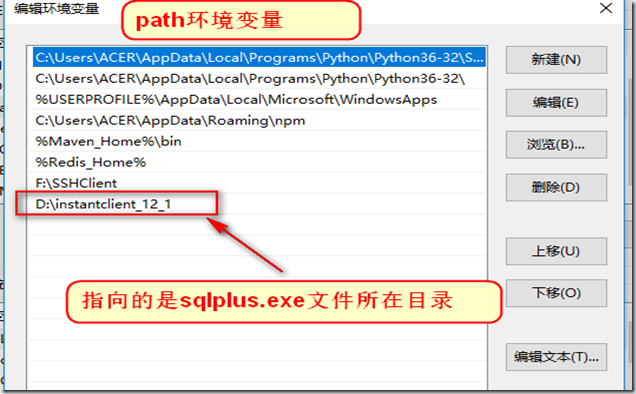
解决sqlplus乱码问题的环境变量:
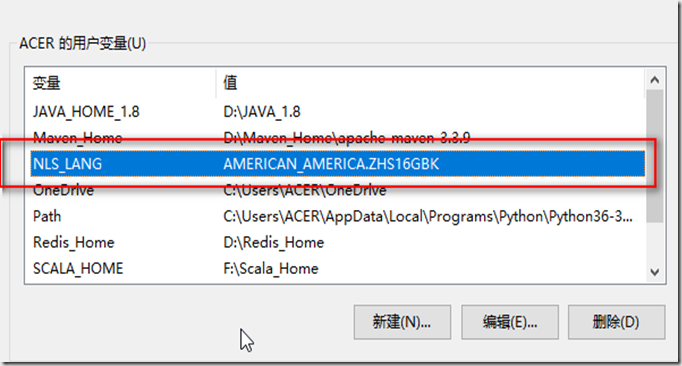
Oracle 中的单行函数:
操作字符的函数 :
函数名
作用
例句
备注
lower
字符串转成小写
eg:lower('MSYM')
输出: msym
使用单引号,而不是双引号
upper
字符串转成大写
eg: upper('msym')
输出: MSYM
使用单引号
initcap
首字母大写
eg:upper('msym hello')
输出: Mysm Hello
使用单引号,
是将每个单词的首字母都大写
substr
取子串
substr(str,startIndex)
eg:substr('msym', 2)
输出: sym
使用单引号,
开始的角标是 1
substr(str, startIndex, count)
eg: substr('msym', 1, 2)
输出: ms
同上
length
取字符串的字符数
eg:length('码上猿梦')
输出: 4
英文的字节数和字符数是一样的,
但是中文的字节数是字符数的两倍,
中文 : 2字节=1字符
lengthb
取字符串的字节数
lengthb('码上猿梦')
输出: 8
instr
查找子串在目的串中的开始位置
instr(resStr, targetStr)
eg: instr('msym', 'ym')
输出: 3
输出的是角标, 从 1 开始
lpad
左填充
eg: lpad('msym', 10, '*')
输出: ******msym
rpad
右填充
eg: rpad('msym', 10, '*')
输出: msym******
trim
去掉前后指定的字符
eg:trim('m' from 'msym')
输出: sy
只是前后的字符, 中间的字符无法使用 trim去掉
replace
替换字符
eg: replace('msym', 'm', '*')
输出: *sy*
操作时间的函数 :
函数名
作用
例子
备注
sysdate
返回系统当前时间
eg: sysdate
返回的包括 : 日-月-年
没有括号
months_between
返回两个日期的相差月数
eg: months_between(date1, date2)
返回date1和date2之间相差的月数
add_months
向指定的日期中加上若干月数
eg: add_months(sysdate, 51)
返回当前系统时间 51个月之后的日期
next_day
返回指定日期的下一天的日期
eg: next_day(sysdate)
返回的当前系统日期的下一天, 即明天
last_day
返回本月的最后一天的日期格式
eg: last_day(sysdate)
返回当前系统日期所在约在月份的最后一天的日期
round
对日期进行四舍五入, 这里的四舍五入指的是:月份: 14舍, 15入,
年份:四舍五入
eg:round(sysdate, 'month')
round(sysdate, 'year')
trunc
对日期进行截断,
eg:trunc(sysdate, 'month')
trunc(sysdate, 'year')
to_char
格式化日期
eg:to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss')
返回当前时间, 如: 2013-09-01 13:45:23
以上就是一日一句 SQL [持续更新] MySQL + Oracle的全部内容。
这篇关于mysql truncsysdate_一日一句 SQL [持续更新] MySQL + Oracle的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







