本文主要是介绍TBB并行编程2 _ 性能测试,任务域,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
性能测试:
#include <tbb/tick_count.h>
#define TICK(x) auto bench_##x = tbb::tick_count::now();
#define TOCK(x) std::cout << #x ": " << (tbb::tick_count::now() - bench_##x).seconds() << "s" << std::endl;#include <iostream>
#include"ticktock.h"
#include <string>
#include <cmath>
#include <vector>
#include <tbb/parallel_for.h>
#include <tbb/blocked_range.h>
#include <tbb/parallel_reduce.h>void test01() {size_t n = 1 << 27;std::vector<float> a(n);TICK(for);tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&](tbb::blocked_range<size_t> r) {for (size_t i = r.begin(); i < r.end(); i++) {a[i] = std::sin(i);}});TOCK(for);TICK(reduce);float res = tbb::parallel_reduce(tbb::blocked_range<size_t>(0, n), (float)0, [&](tbb::blocked_range<size_t> r, float local_res) {for (size_t i = r.begin(); i < r.end(); i++) {local_res += a[i];}return local_res; }, [](float x, float y) {return x + y;});TOCK(reduce);std::cout << res << std::endl;
}
void test02() {size_t n = 1 << 27;std::vector<float> a(n);TICK(for);for (size_t i = 0; i < n; i++){a[i] += std::sin(i);}TOCK(for);TICK(reduce);float res = 0;for (size_t i = 0; i < n; i++){res += a[i];}TOCK(reduce);std::cout << res << std::endl;
}int main() {test01();std::cout << "------------" << std::endl;test02();
}
通过上面那个时间戳就可以计时,从结果来看显然并行算法耗时更少。
评价一个并行速度通常会用加速比=串行用时÷并行用时
更专业的性能测试框架:Google benchmark
这个我安装了之后一直显示连接不上。。。。我也很奇怪
#include <iostream>
#include <vector>
#include <cmath>
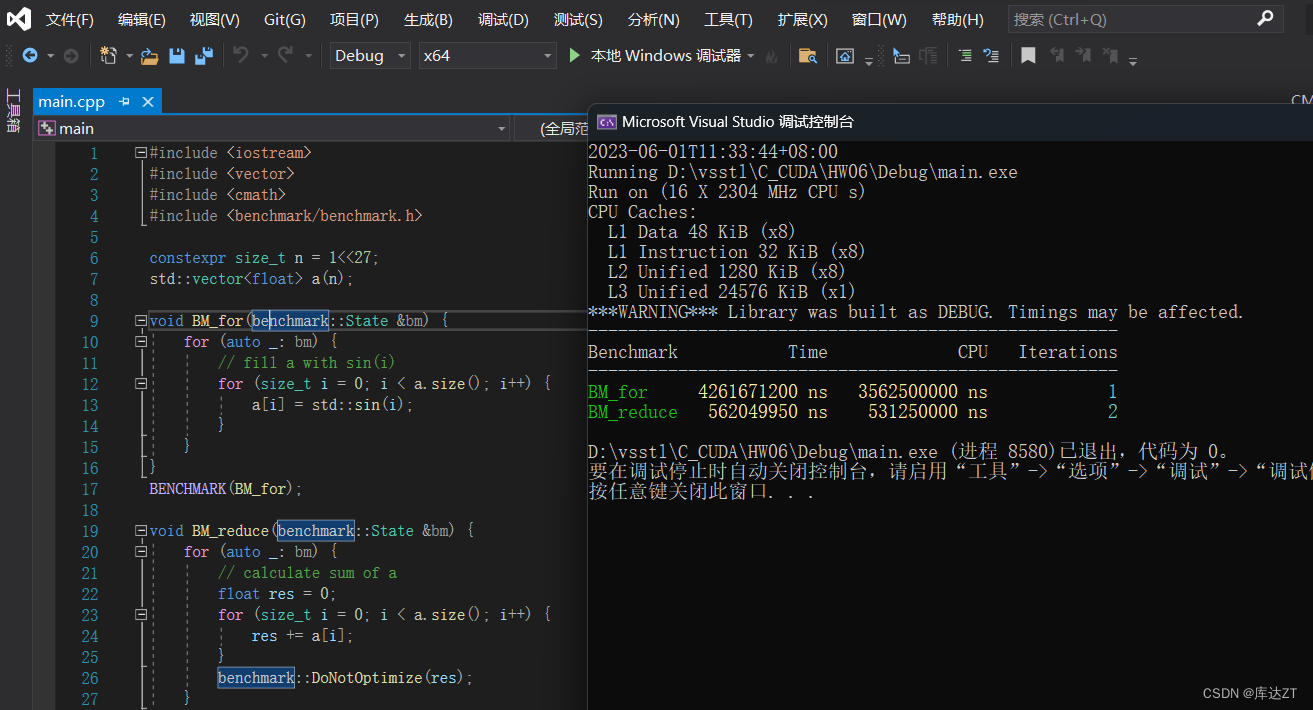
#include <benchmark/benchmark.h>constexpr size_t n = 1<<27;
std::vector<float> a(n);void BM_for(benchmark::State &bm) {for (auto _: bm) {// fill a with sin(i)for (size_t i = 0; i < a.size(); i++) {a[i] = std::sin(i);}}
}
BENCHMARK(BM_for);void BM_reduce(benchmark::State &bm) {for (auto _: bm) {// calculate sum of afloat res = 0;for (size_t i = 0; i < a.size(); i++) {res += a[i];}benchmark::DoNotOptimize(res);}
}
BENCHMARK(BM_reduce);BENCHMARK_MAIN();代码是这样的
回更:安装好啦
总结安装错误:要找到config。
cmake_minimum_required(VERSION 3.10)set(CMAKE_CXX_STANDARD 17)
set(CMAKE_BUILD_TYPE Release)
SET(TBB_DIR "D:\\vsstl\\C_CUDA\\vcpkg-master\\vcpkg-master\\packages\\tbb_x64-windows\\share\\tbb")
SET(benchmark_DIR "D:\\vsstl\\C_CUDA\\vcpkg-master\\vcpkg-master\\packages\\benchmark_x64-windows\\share\\benchmark")
project(main LANGUAGES CXX)add_executable(main main.cpp)#find_package(OpenMP REQUIRED)
#target_link_libraries(main PUBLIC OpenMP::OpenMP_CXX)find_package(TBB REQUIRED)
target_link_libraries(main PUBLIC TBB::tbb)set(BENCHMARK_ENABLE_TESTING OFF CACHE BOOL "Turn off the fking test!")
find_package(benchmark CONFIG REQUIRED)
target_link_libraries(main PUBLIC benchmark::benchmark benchmark::benchmark_main)
任务域与嵌套
#include <iostream>
#include <tbb/parallel_for.h>
#include <tbb/task_arena.h>
#include <vector>
#include <cmath>int main() {size_t n = 1<<26;std::vector<float> a(n);tbb::task_arena ta(4);//可以指定用多少线程ta.execute([&] {tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) {a[i] = std::sin(i);});});return 0;
}也可以用两个for进行嵌套,这样可以解决n比较小,核心没有用光的问题:
tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) {tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) {a[i * n + j] = std::sin(i) * std::sin(j);});});但是嵌套会导致死锁问题:
tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) {std::lock_guard lck(mtx);tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) {a[i * n + j] = std::sin(i) * std::sin(j);});});这是因为tbb采用的是工作窃取法,就是在线程t1做完自己的工作之后,就会去看别的线程有没有做完工作,如果还有没做完的工作就会从这个线程里将工作取出,放到自己的t1线程里。
因此内部 for 循环有可能“窃取”到另一个外部 for 循环的任务,从而导致 mutex 被重复上锁。
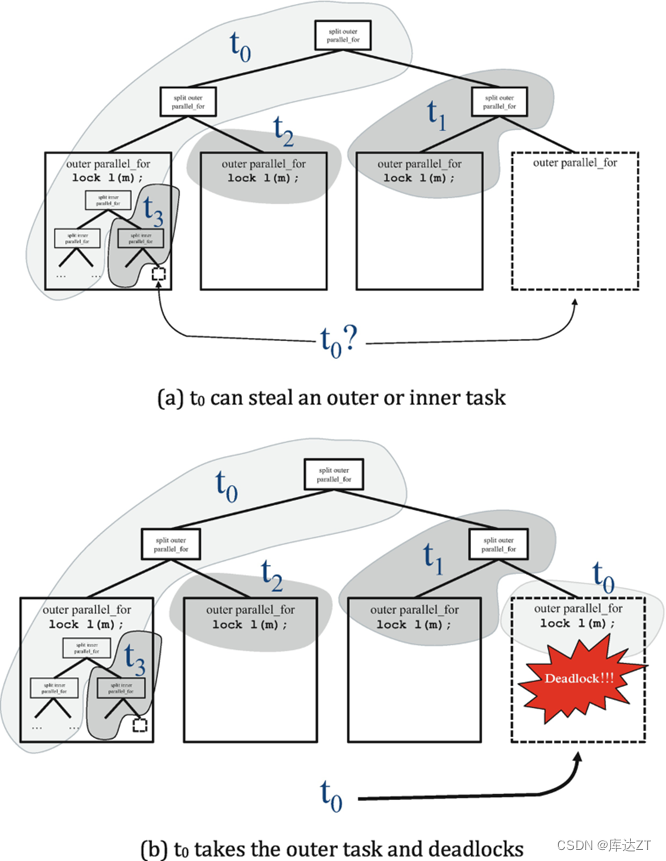
所以为了解决这种问题:
1、用递归锁:
std::recursive_mutex mtx;
2、另外创建一个任务域
tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) {std::lock_guard lck(mtx);tbb::task_arena ta;ta.execute([&] {tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) {a[i * n + j] = std::sin(i) * std::sin(j);});});});3、isolate隔离:
tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) {std::lock_guard lck(mtx);tbb::this_task_arena::isolate([&] {tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) {a[i * n + j] = std::sin(i) * std::sin(j);});});});这篇关于TBB并行编程2 _ 性能测试,任务域的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



