left = pd.DataFrame({'key1':['K0','K0','K1','K2'],'key2':['K0','K1','K0','K1'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})right = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K0'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})
left = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K1'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})right = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K0'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})print(pd.merge(left,right,on=['key1','key2']))
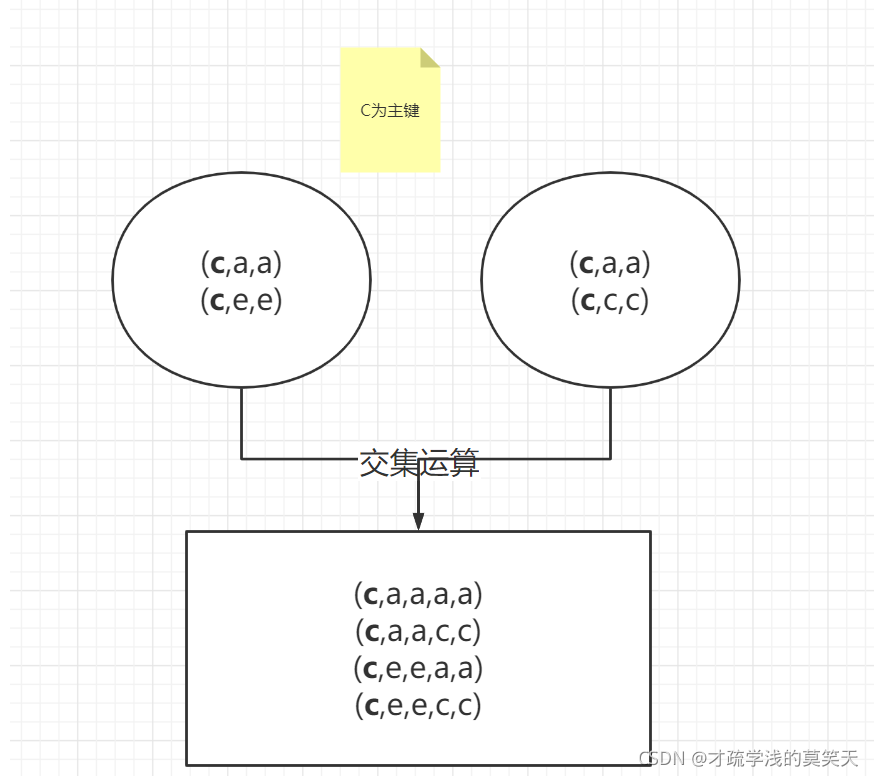
left = pd.DataFrame({'key':['c','d','c'],'A':['a','b','e'],'B':['a','b','e']},)
right = pd.DataFrame({'key':['c','d','c'],'C':['a','b','c'],'D':['a','b','c']},)
left
key
A
B
0
c
a
a
1
d
b
b
2
c
e
e
right
key
C
D
0
c
a
a
1
d
b
b
2
c
c
c
pd.merge(left,right,on=['key'])
key
A
B
C
D
0
c
a
a
a
a
1
c
a
a
c
c
2
c
e
e
a
a
3
c
e
e
c
c
4
d
b
b
b
b
left = pd.DataFrame({'key1':['K0','K0','K1','K2'],'key2':['K0','K1','K0','K1'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K0'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})print(pd.merge(left, right, how='left', on=['key1','key2']))## 匹配left数据框内有的所有键对,right没有则不匹配。
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
外连接,所有值,不存在则用na填充(并集)
left = pd.DataFrame({'key1':['K0','K0','K1','K2'],'key2':['K0','K1','K0','K1'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K0'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})print(pd.merge(left,right,how='outer',on=['key1','key2']))
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3
《JavaList使用举例(从入门到精通)》本文系统讲解JavaList,涵盖基础概念、核心特性、常用实现(如ArrayList、LinkedList)及性能对比,介绍创建、操作、遍历方法,结合实... 目录一、List 基础概念1.1 什么是 List?1.2 List 的核心特性1.3 List 家族成