本文主要是介绍数据扩增(Data Augmentation)、正则化(Regularization)和早停止(Early Stopping),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据扩增(Data Augmentation)、正则化(Regularization)和早停止(Early Stopping)是深度学习中常用的三种技术,它们有助于提高模型的泛化性能和防止过拟合
数据扩增(Data Augmentation)
-
定义:数据扩增是通过对训练集中的原始数据进行一系列变换,生成新的训练样本,从而增加训练数据的多样性。这有助于提高模型的鲁棒性,使其能够更好地泛化到未见过的数据。
-
常见的扩增操作:翻转(水平、垂直)、旋转、缩放、平移、亮度调整、对比度调整等。
-
作用:数据扩增通过引入差异性,有助于模型学习更丰富的特征,降低过拟合的风险。
-
实现:在训练过程中,每次从原始图像中随机选择一种扩增操作应用到训练样本上。
正则化(Regularization)
-
定义:正则化是一种通过在损失函数中引入额外的惩罚项,以防止模型过拟合的技术。常见的正则化方法包括L1正则化和L2正则化。
-
L1正则化:在损失函数中添加权重参数的绝对值之和,鼓励模型的权重更加稀疏。
-
L2正则化:在损失函数中添加权重参数的平方和,鼓励模型的权重保持较小的值。
-
作用:正则化通过对模型的复杂性进行控制,防止模型在训练数据上过度拟合,从而提高模型的泛化性能。
-
实现:在损失函数中添加正则化项,并通过超参数来控制正则化的强度。
早停止(Early Stopping)
-
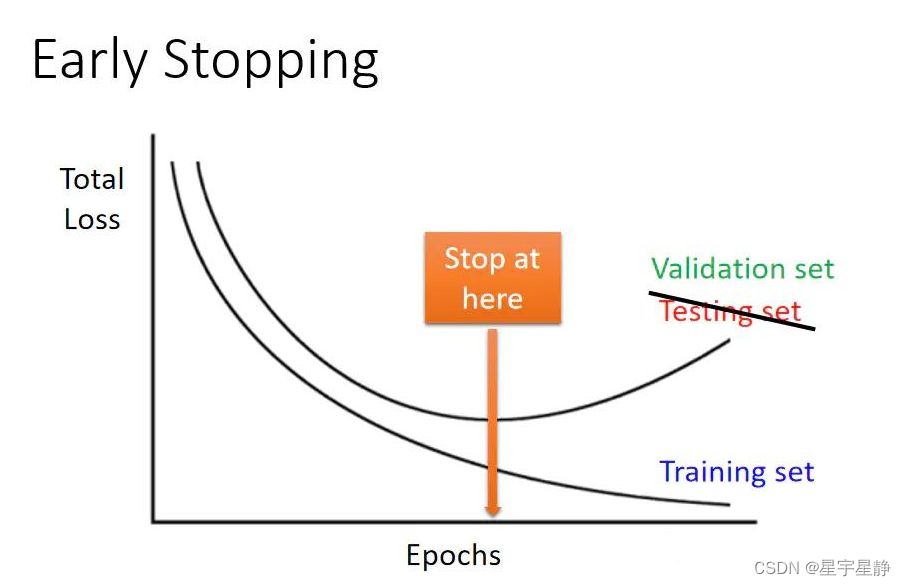
定义:早停止是一种在训练过程中监测验证集性能并在性能不再提高时停止训练的技术。它通过避免在训练数据上过度拟合,提高模型在未见过数据上的泛化性能。
-
作用:当模型在训练集上表现得越来越好但在验证集上表现趋于恶化时,早停止防止了过拟合。
-
实现:在每个训练周期结束后,监测验证集性能。如果验证集性能在一定轮次内没有提升,就停止训练。
这三种技术通常结合使用,以提高深度学习模型的性能并降低过拟合风险。数据扩增增加了训练数据的多样性,正则化通过对模型参数的惩罚控制模型的复杂性,而早停止则防止模型在训练集上过度拟合。
这篇关于数据扩增(Data Augmentation)、正则化(Regularization)和早停止(Early Stopping)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





