本文主要是介绍LLM Fine-Tuning大模型FT方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Here we discuss fine-tuning Llama 2 with a couple of different recipes. We will cover two scenarios here:
1. Parameter Efficient Model Fine-Tuning
This helps make the fine-tuning process more affordable even on 1 consumer grade GPU. These methods enable us to keep the whole model frozen and to just add tiny learnable parameters/ layers into the model. In this way, we just train a very tiny portion of the parameters. The most famous method in this category is LORA, LLaMA Adapter and Prefix-tuning.
These methods will address three aspects:
-
Cost of full fine-tuning – these methods only train a small set of extra parameters instead of the full model, this makes it possible to run these on consumer GPUs.
-
Cost of deployment – for each fine-tuned downstream model we need to deploy a separate model; however, when using these methods, only a small set of parameters (few MB instead of several GBs) of the pretrained model can do the job. In this case, for each task we only add these extra parameters on top of the pretrained model so pretrained models can be assumed as backbone and these parameters as heads for the model on different tasks.
-
Catastrophic forgetting — these methods also help with forgetting the first task that can happen in fine-tunings.
HF PEFT library provides an easy way of using these methods which we make use of here. Please read more here.
2. Full/ Partial Parameter Fine-Tuning
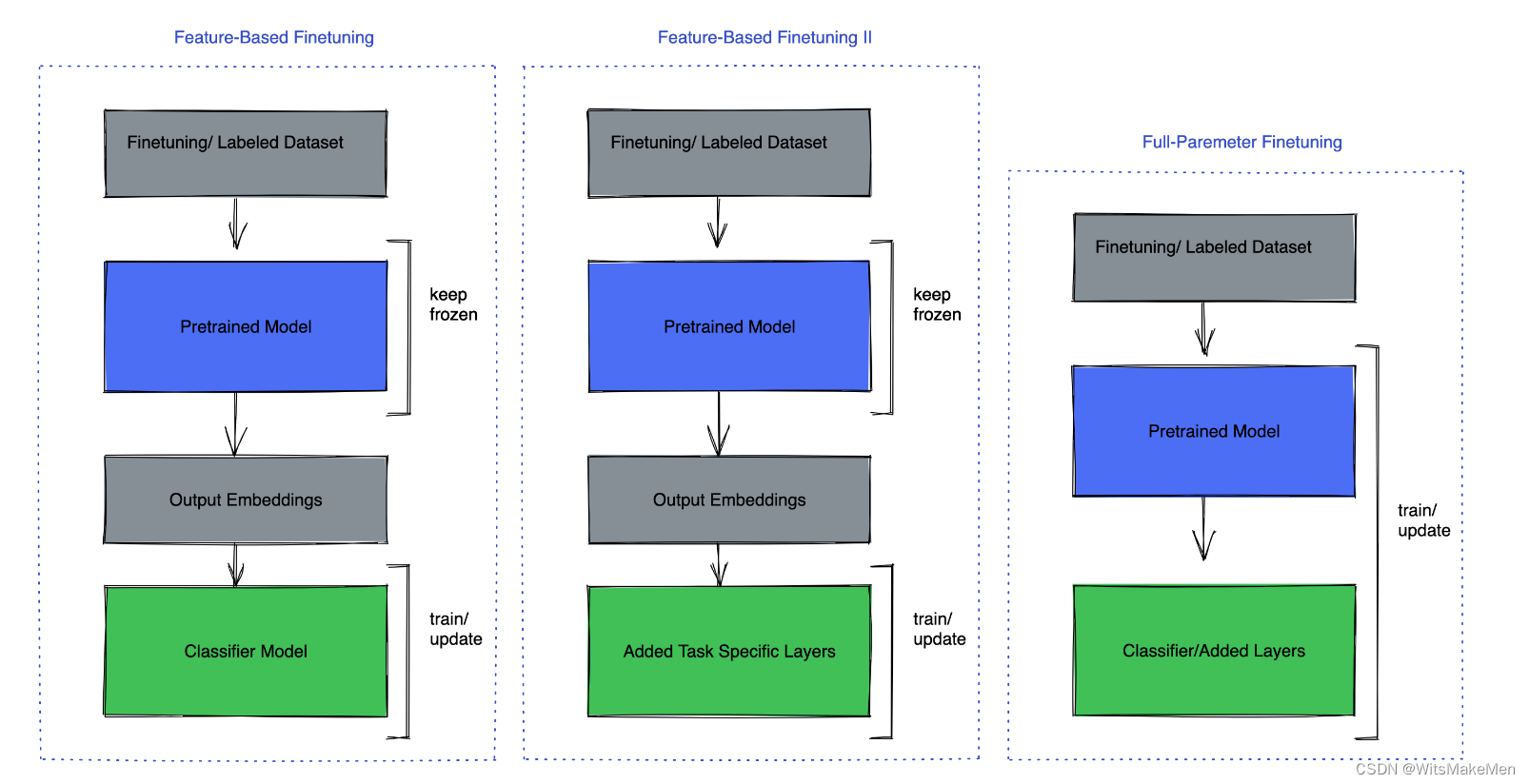
Full parameter fine-tuning has its own advantages, in this method there are multiple strategies that can help:
-
Keep the pretrained model frozen and only fine-tune the task head for example, the classifier model.
-
Keep the pretrained model frozen and add a few fully connected layers on the top.
-
Fine-tuning on all the layers.
You can also keep most of the layers frozen and only fine-tune a few layers. There are many different techniques to choose from to freeze/unfreeze layers based on different criteria.
In this scenario depending on the model size, you might need to go beyond one GPU, especially if your model does not fit into one GPU for training. In this case Llama 2 7B parameter won’t fit into one gpu. The way you want to think about it is, you would need enough GPU memory to keep model parameters, gradients and optimizer states. Where each of these, depending on the precision you are training, can take up multiple times of your parameter count x precision( depending on if its fp32/ 4 bytes, fp16/2 bytes/ bf16/2 bytes). For example AdamW optimizer keeps 2 parameters for each of your parameters and in many cases these are kept in fp32. This implies that depending on how many layers you are training/ unfreezing your GPU memory can grow beyond one GPU.
FSDP (Fully Sharded Data Parallel)
Pytorch has the FSDP package for training models that do not fit into one GPU. FSDP lets you train a much larger model with the same amount of resources. Prior to FSDP was DDP (Distributed Data Parallel) where each GPU was holding a full replica of the model and would only shard the data. At the end of backward pass it would sync up the gradients.
FSDP extends this idea, not only sharding the data but also model parameters, gradients and optimizer states. This means each GPU will only keep one shard of the model. This will result in huge memory savings that enable us to fit a much larger model into the same number of GPU. As an example in DDP the most you could fit into a GPU with 16GB memory is a model around 700M parameters. So, suppose you had 4 GPUs, in this case even though you access 4 GPUs, you still can’t scale beyond the model size that can fit into one GPU. However with FSDP you can fit a 3B model into 4 GPUs, > 4x larger model.
Please read more on FSDP here & get started with FSDP here.
To boost the performance of fine-tuning with FSDP, we can make use a number of features such as:
-
Mixed Precision which in FSDP is much more flexible compared to Autocast. It gives user control over setting precision for model parameters, buffers and gradients.
-
Activation Checkpointing which is a technique to save memory by discarding the intermediate activation in forward pass instead of keeping it in the memory with the cost recomputing them in the backward pass. FSDP Activation checkpointing is shard aware meaning we need to apply it after wrapping the model with FSDP. In our script we are making use of that.
-
auto_wrap_policy Which is the way to specify how FSDP would partition the model, there is default support for transformer wrapping policy. This allows FSDP to form each FSDP unit ( partition of the model ) based on the transformer class in the model. To identify this layer in the model, you need to look at the layer that wraps both the attention layer and MLP. This helps FSDP have more fine-grained units for communication that help with optimizing the communication cost.
这篇关于LLM Fine-Tuning大模型FT方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




