本文主要是介绍相识词设计思路及实现方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.业务背景
2.实现方法
第一种:
编辑
第二种:
3.相关材料
1.业务背景
业务有全文检索功能,然后根据标书的要求需要有近似词的功能,一般近似词需要模型训练之后成为词库,是需要大数据相关人员负责。负责人表示简单实现一个不需要那么复杂,如输入 张三显示于张三有关的信息表示。作为开发的当然不允许这么草率实现一个功能,相识近似至少要能识别中文语义才行。
2.实现方法
第一种:
在网上找到一个 shibing624 similarity 的jar 包,里面包含了词语短句中文以及字符串的格式相识,通过比较都得一个相识分。然后在网上找到一个简单的词库,通过流的形式读取出来然后挨个比较。得出分数高的返回即可,嘿嘿嘿,想法不错。
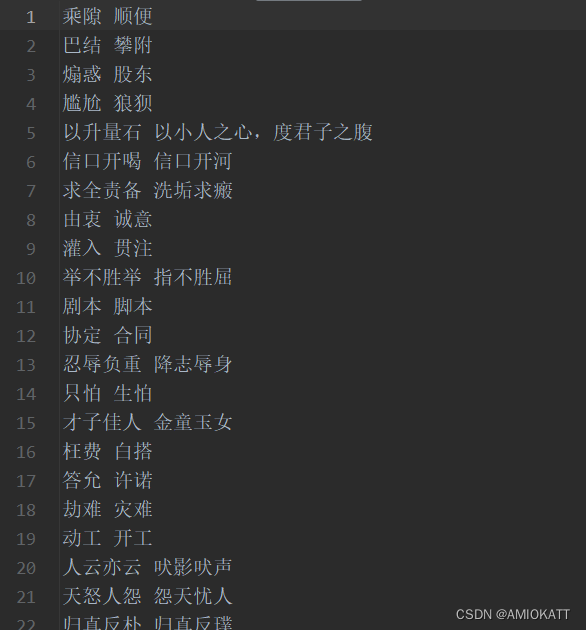
这是词库的格式得按照一定格式解析,考虑近似词使用可能比较频繁,每次本地IO也挺消耗资源,所以给他干以放在内存,因为词库数据可能存在重复的情况,使用set集合
private static Set<String> lexiconResourcePaths = new HashSet<>();private static Set<String> lexiconData = new HashSet<>();/*** 词典预热*/@PostConstructpublic void lexiconPreheat() {loadResource();analysisLexicon();}/*** 加载资源*/private void loadResource() {lexiconResourcePaths.add(getClass().getClassLoader().getResource("lexicon/jinyici.txt").getFile());}/*** 解析本地词典** @return*/private void analysisLexicon() {StringBuilder result = new StringBuilder();lexiconResourcePaths.forEach(filePath -> {File file = new File(filePath);try {// 构造一个BufferedReader类来读取文件BufferedReader br = new BufferedReader(new FileReader(file));String s = null;// 使用readLine方法,一次读一行while ((s = br.readLine()) != null) {result.append(System.lineSeparator() + s);}br.close();} catch (Exception e) {e.printStackTrace();}});String str = result.toString().replace("\r\n", " ");lexiconData = Arrays.stream(str.split(" ")).collect(Collectors.toSet());}然后就是将要获取同义词的和词库一一比计较,且必须得按照分数分值高的排序。
添加的时候会遇到几种情况,所以是添加的时候去比较,且可以根据前端传递的长度返回前几位,有几种情况
@Overridepublic List<SearchSimilarityVo> execute(SimilarSearchParam param) {List<SearchSimilarityVo> resultVo = new LinkedList<>();lexiconData.forEach(word -> {double score = Similarity.conceptSimilarity(param.getSearchContent(), word);if (score < 0.7 || StringUtils.isEmpty(word)){return;}SearchSimilarityVo currentData = new SearchSimilarityVo(word, score);if (resultVo.size() >= 1) {int lastIndex = resultVo.size() - 1;SearchSimilarityVo lastData = resultVo.get(lastIndex);Double acquaintanceshipScore = lastData.getScore();// 大于if (score > acquaintanceshipScore) {while (true) {if (lastIndex == 0) {// 最小break;}lastIndex--;lastData = resultVo.get(lastIndex);if (score > lastData.getScore()) {continue;} else {lastIndex++;break;}}// 1.大于长度 删除末尾if (resultVo.size() >= param.getSize()) {resultVo.remove(resultVo.size() - 1);}resultVo.add(lastIndex, currentData);} else if (resultVo.size() < param.getSize()) {// 2.小于且不超过总长度resultVo.add(currentData);}} else {// 3.第一个resultVo.add(currentData);}});System.out.println("resultVo{}:" + resultVo);return resultVo;}功能是实现了,但其实每次去比较这么多其实还是挺耗时间,词库 就 30000次每次都去比较,性能就不用说了,肯定慢,而且一旦遇到分数高的还得将数据进行排序,所以我这使用的是 linklist 会强一点,且在添加的时候已经将顺序排号,过滤了低分。
但是这种词库不出意外的肯定出意外了,客户说这同义词没啥用。嘿嘿嘿给我说,词库这方面我们还没想法,要不这样你就知识库(也就是 用户名 邮箱 电话 相关的三个库),要求比如输入英文名 能显示中文名,就这样一个实例,没错,剩下的又是我自己发挥的时候,开发真难,抱着客户都是祖宗的原则,我只能,害,这不简简单单的事情嘛。
第二种:
只有一个实例,剩下的都得自己想,首先是姓名 手机 邮箱的库,要我说就简单粗暴一些就全字段匹配将符合的一行数据全部匹配返回就完事了。唉,谁让我是个合格开发勒,这种低级耗时的设计代码我是一行都不想写,必须得高级。
正则表达式怎么样,首先根据输入的内容判断其输入的是什么,在根据其输入的内容格式去匹配最相识的格式,嘿嘿嘿,我确实想这么做,比如你输入手机号 123456 刚好库里有123457,第一符合的放前面,但是有点不符合客户的想法输入中文名 提示英文名()
同步es怎么样,毕竟三张表多字段匹配管理查询效率不说,且sql写起来也麻烦不是,直接组成宽表搞到es,嘿嘿嘿,还能分词,好是好,又得考虑同步问题,咋比对值有没有改变还是直接全部更新一遍,想的这头疼,好希望公司有个项目经理,这种方案的事我就不操心了。
TODO 代码实现后补充
3.相关材料
GitHub - shibing624/similarity: similarity: Text similarity calculation Toolkit for Java. 文本相似度计算工具包,java编写,可用于文本相似度计算、情感分析等任务,开箱即用。
这篇关于相识词设计思路及实现方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




