本文主要是介绍【Python3.6爬虫学习记录】(十)爬取教务处成绩并保存到Excel文件中(哈工大),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:基本上每天都会产生一点小想法,在实现的过程中,一步步解决问题,并产生新的想法,就比如,这次是保存为Excel文件。这感觉很美妙!
目录:
一,安装并简单使用xlwt
1.1 安装xlwt
1.2 写入Excel代码
1.3 拓展
二,登陆教务处爬取成绩
2.1 实现图解
2.2 代码及注释
2.3 相关问题
三,More
3.1 关于教务处的遐想
一,安装并简单使用xlwt
1.1 安装xlwt
命令行输入
pip install xlwt1.2 写入Excel代码
work = Workbook() #创建一个工作簿
sheet = w.add_sheet('Hey, Hades') #创建一个工作表sheet
sheet.write(0,0,'bit') #在1行1列写入bit
sheet.write(0,1,'huang') #在1行2列写入huang
sheet.write(1,0,'xuan') #在2行1列写入xuan
work.save('Test.xls') #保存注意,和数组一样,Excel表格是从 0 行 0 列开始计数
1.3 拓展
有了写入,当然也有读取。
pip install xlrd使用参考链接:
Python第三方库xlrd/xlwt的安装与读写Excel表格
Python–使用xlwt将列表类型的数据写到Excel xls文件中–TxtToExcel
window10下python的对elcel表格操作xlrd和xlwt模块的下载与安装及基本的使用
二,登陆教务处爬取成绩
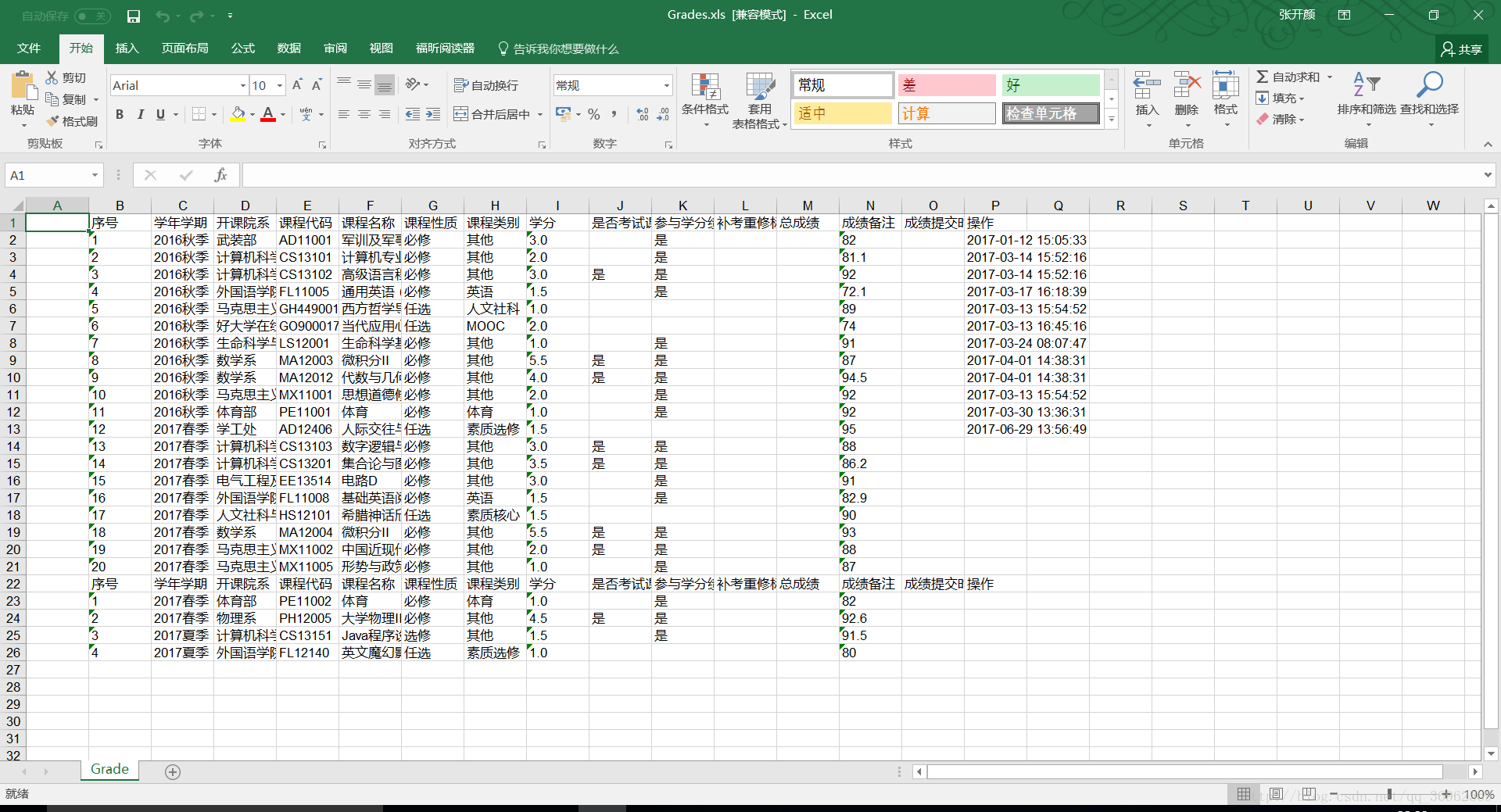
2.1 实现图解
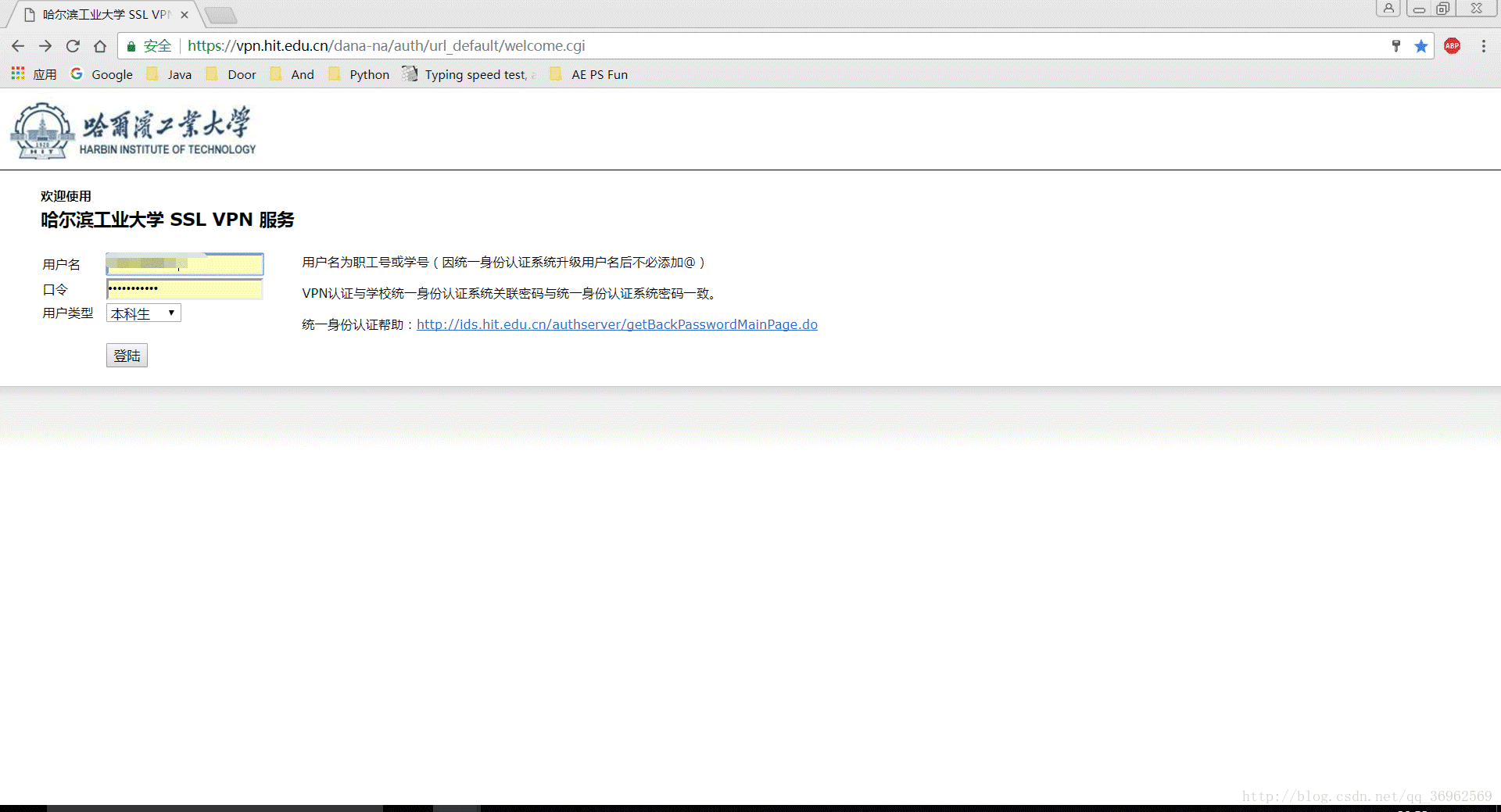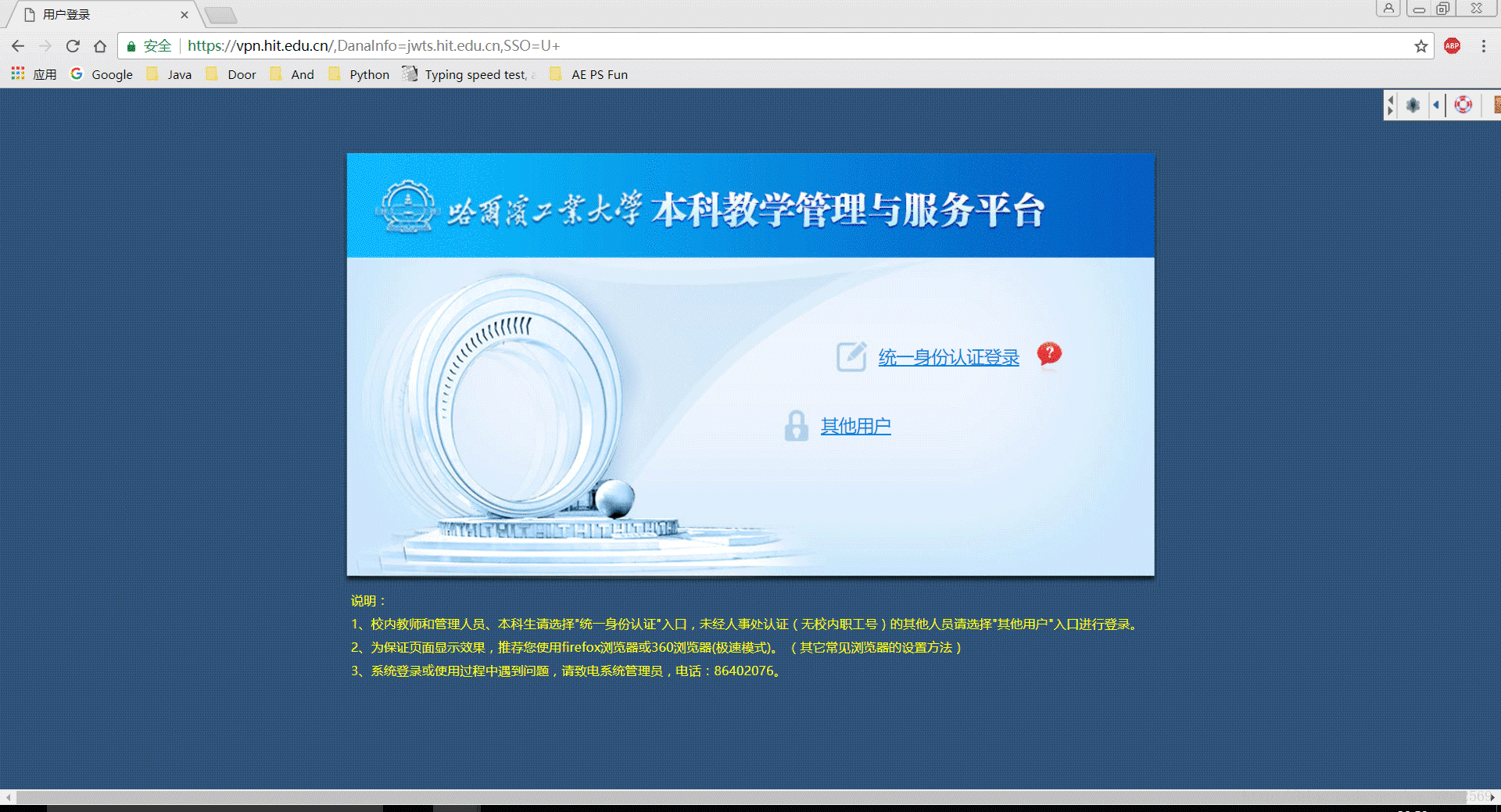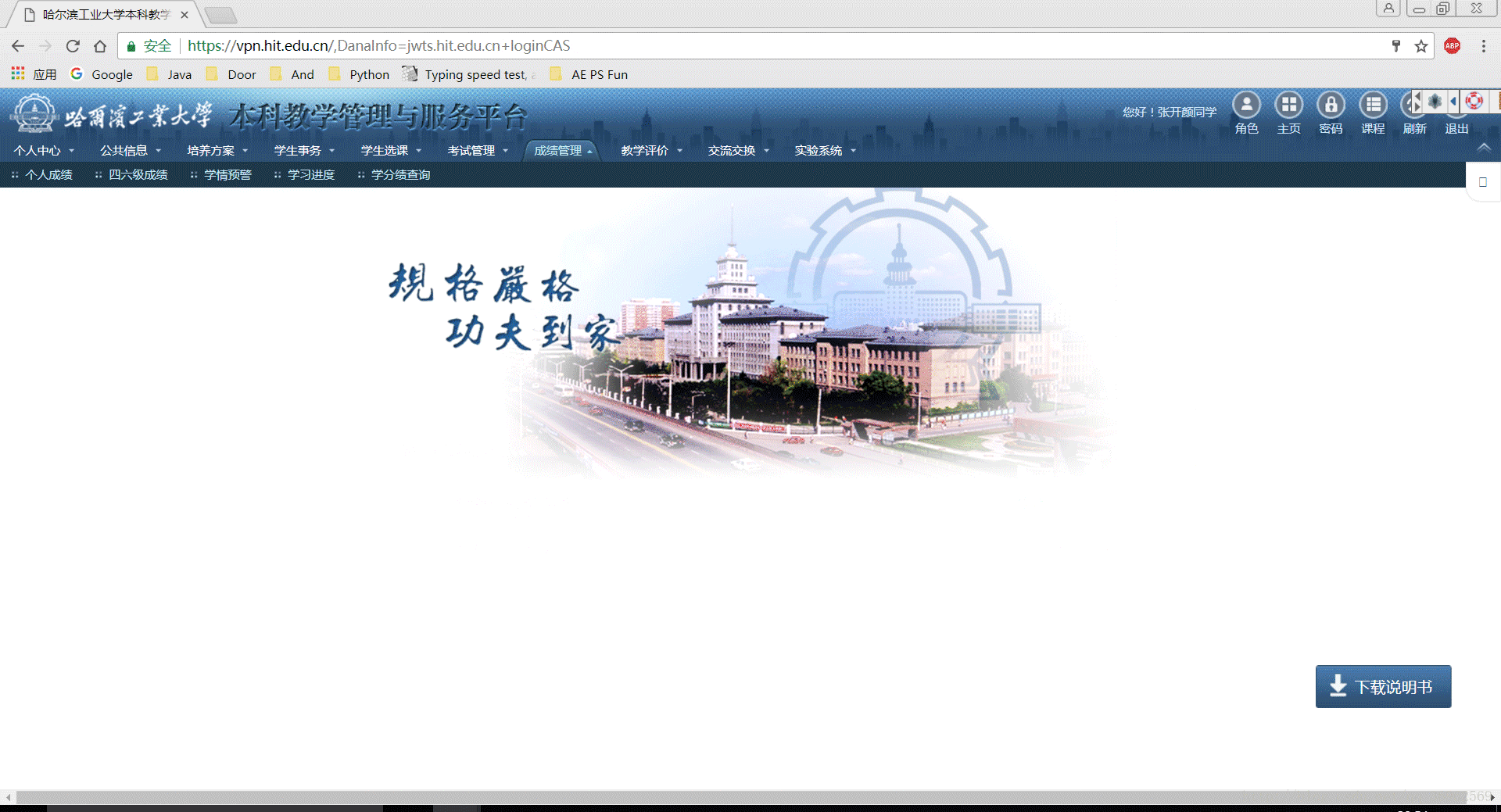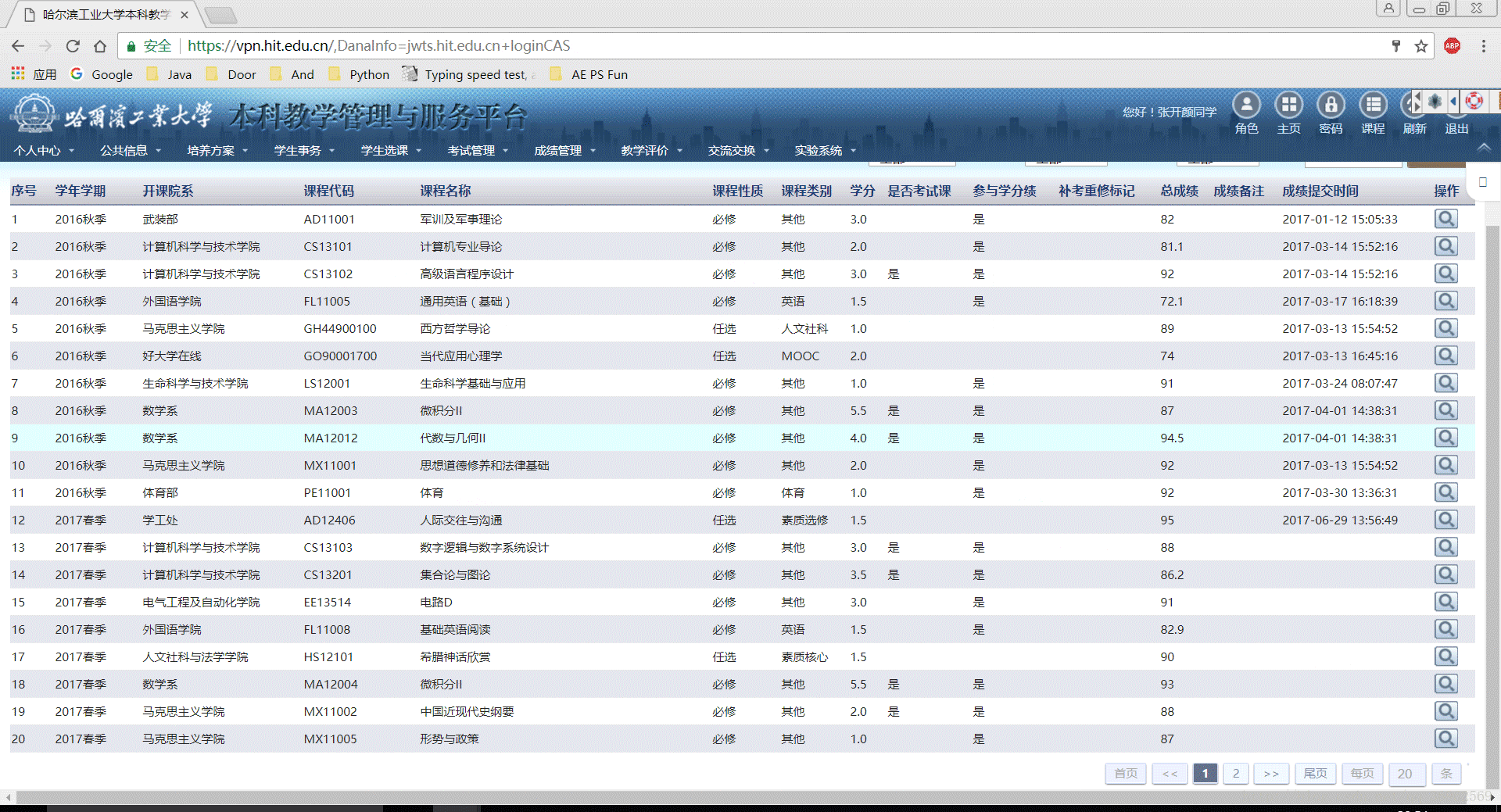
(多张图片合成GIF,也是现想到的,教程->photoshop将多个图片合成制作gif)
Excel文件:
2.2 代码及注释
# 由于放假回家,而登陆教务处需要校园网,所以采用SSL VPN登陆,到了学校,可以直接去掉前面的VPN登陆
# 通过SSL vpn登陆教务处,爬取成绩并保存到Excel
# SSL vpn地址 https://vpn.hit.edu.cn/dana-na/auth/url_default/welcome.cgi
# 教务处网址 jwts.hit.edu.cn
import xlwt
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
import requests
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
# 主要难点及错点在于各种按钮的点击def login_VPN():# 打开SSL VPNSSLVPN = 'https://vpn.hit.edu.cn/dana-na/auth/url_default/welcome.cgi'driver = webdriver.Chrome()driver.get(SSLVPN)# 输入用户密码user = driver.find_element_by_id('username')username = input('Enter your username : ')user.send_keys(username)pwd = driver.find_element_by_id('password')password = input('Enter your password : ')pwd.send_keys(password)# 选择登陆账户类型 ->下拉列表元素的定位login = driver.find_element_by_id('btnSubmit_6')login.click()# 成功登陆到网站;里面driver.find_element_by_id('browseUrl').send_keys('jwts.hit.edu.cn')driver.find_element_by_id('btnBrowse_3').click()# 教务网登陆 通用身份登陆time.sleep(1)# 以后都借助Google 开发者,直接拷贝xpath定位driver.find_element_by_xpath('//*[@id="dl"]').click()driver.find_element_by_id('username').send_keys(username)driver.find_element_by_id('password').send_keys(password)driver.find_element_by_xpath('//*[@id="casLoginForm"]/p[5]/button').click()# 先点击 成绩管理driver.find_element_by_xpath('//*[@id="menu_7"]/span').click()time.sleep(1)# 出现四个选项,选择个人成绩 -> Message: element not visible# xpath定位有问题//*[@id="closeBtn2"]/span[2]# 原来是个超链接,用text定位meGrade = driver.find_element_by_link_text('个人成绩')meGrade.click()# 在出现的页面中选择期末成绩time.sleep(1)driver.switch_to_frame('iframename')driver.find_element_by_class_name('qmcx').click()# 出现所有成绩页面time.sleep(1)page=0hang = 0# 创建Excel文件MyGrades = xlwt.Workbook()sheet = MyGrades.add_sheet('Grade',cell_overwrite_ok=True)while(page<2):soup = BeautifulSoup(driver.page_source,'lxml')grades = soup.find(class_='list').find_all('tr')for grade in grades:line = grade.get_text()# 根据换行分割ths = line.split('\n')lie=0for th in ths:sheet.write(hang,lie,th)lie+=1hang+=1# 最后一页,没有下一页if(page!=1):driver.find_element_by_link_text('2').click()page += 1time.sleep(1)# 保存Excel文件MyGrades.save('Grades.xls')# 退出driver.switch_to_default_content()driver.find_element_by_css_selector('[title="Sign out"]').click()login_VPN()
2.3 相关问题
①Google开发者copy xpath
发现Google可以直接 右键-> 检查-> select选定页面element -> 显示相应源码 -> 右键copy -> copy xpath
就这样,愉快的定位了,结果,,,坑死了
定位不唯一!!!终于发现,有时候还要自己修改,我‘好运’的碰到了。
warning,总的来说,只要有多个并列element(比如教务网的上的那一排选项),那么直接copy xpath是不可行了,需要修改或者再选别的定位方法。
②关于存在超链接的定位
通过link文字精确定位元素
<a onclick="return false;" class="lb" name="tj_login" href="https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F">登录</a>存在 href, 并且最后面是文本(也可以是父类中有href)
find_element_by_link_text("登录")参考链接:Selenuim+Python之元素定位总结及实例说明(写的非常好,有时定位拿不准时就可以参考,该作者还写了一系列文章)
一些注意事项:Python+Selenium定位不到元素常见原因及解决办法(报:NoSuchElementException)
③ 关于下拉列表的处理
参考链接:Python Selenium下拉列表元素定位
然而我的使用情况如下
# 选择登陆账户类型 ->下拉列表元素的定位# 定位父元素select,然后通过tag name找到所有option,得到option元素的数组,# 然后通过数组索引定位,最后click.# 报错 AttributeError: 'list' object has no attribute 'click'# 用select方法# 报错 AttributeError: 'list' object has no attribute 'tag_name'# select = Select(driver.find_elements_by_name('realm'))# select.select_by_value('本科生')最终解决如下,主要是先定位到下拉菜单父属性,再定位到选项
driver.find_element_by_id('realm_17').find_element_by_css_selector('[value="本科生"]').click()④点击出现,Message: element not visible
自信的用copy xpath直接定位,坑惨了,还是定位原因。。
不过还是参考了很多事例,前面也提到过处理方法,此处不再细说。
⑤关于字符串分割及print的问题
开始准备直接打印到文本,然而由于打印的格式不满意,最终想到了Excel。
不过前面遇到了一些问题,也记载下来:
一个是打印列表的新用法啊
# 根据换行分割ths = line.split('\n')# 直接打印print('\t'.join(ths))另一个是print 自动换行打印,需要注意。
ths = line.split('\n')for th in ths:# print(th) 会自动换行,需要加上end=""才不会自动换行print('%15s'%th, end="")三,More
3.1 关于教务处的遐想
提到教务网,基本所有学计算机的都是从攻击本校教务处开始。当然,这有点难度,不过,从教务网搞到全校学生照片,找找校花,还是嘿嘿的。。
本来准备下午就开始行动的的,然而,由于放假回家,用不到校园网,而用SSLVPN去操作下载,实在麻烦,需要反复登陆才行。所以作罢,到学校再试。
思路,教务网找到自己照片,查看对应源码, 光标悬浮在src属性上,查看照片真正源码,在新页面打开便是照片。可以发现照片真正地址与学号有关(应该所有高校都是这样吧),然后采用循环(得到系列学号->照片地址),下载所有照片。(注意,要捕获异常,避免因为学号不存在而发生错误)
伪代码:
def DownPictures():xh=xxxxxxxxxxxurlHead = 'https://vpn.hit.edu.cn/xswhxx/,DanaInfo=jwts.hit.edu.cn+showPhoto?xh='url = urlHead+str(xh)driver = webdriver.Chrome()driver.get(url)data = requests.get(url).contentsoup =BeautifulSoup(data,'lxml')image = soup.find('img')number = 000000000000while(number< stuNum)try:with open(str(xh)+'.jpg','wb') as f:f.write(img)print('Picture of '+str(xh)+' has downloaded')except Exception as e:print(str(number)+e)number+=1这篇关于【Python3.6爬虫学习记录】(十)爬取教务处成绩并保存到Excel文件中(哈工大)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







