本文主要是介绍MySQL去重-字段左右相反依旧视为同一条数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一. 需求
- 二. 解决方案
一. 需求
今天网上看到一个问题,觉得有点意思,然后尝试回答了下。
像这样的数据,字段左右相反,但要算作同一条数据去重怎么写sql
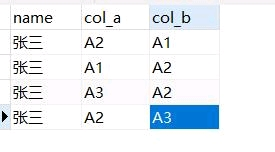
二. 解决方案
测试数据:
create table test2(id int,name varchar(20), col_a varchar(20), col_b varchar(20));insert into test2 values (1,'张三','A2','A1');
insert into test2 values (2,'张三','A1','A2');
insert into test2 values (3,'张三','A1','A2');
insert into test2 values (4,'张三','A3','A2');
insert into test2 values (5,'张三','A2','A3');
insert into test2 values (6,'张三','A2','A3');
刚开始遇到这个问题还卡了一下,一般的去重都是通过distinct或者Group by来实现,而这个因为两个字段相反也会视为重复,这个就没办法使用简单的distinct来去重了。
此时想到了万能的子查询和临时表,因为存在多条数据,使用临时表之后需要进行去重,此时使用子查询。
解决思路比较通用, 通过子查询找到 (col_a = col_a and col_b = col_b) or (col_a = col_b and col_b = col_a) 的数据,然后通过id进行对比,总共找到几条,然后取值第一条即可。
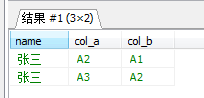
select name,col_a,col_bfrom (select id,name,col_a,col_b,(select count(*) from test2 t2 where (t2.col_a = t1.col_a and t2.col_b = t1.col_b and t2.name = t1.name and t2.id <= t1.id) or (t2.col_a = t1.col_b and t2.col_b = t1.col_a and t2.name = t1.name and t2.id <= t1.id )) as numsfrom test2 t1
) tmp
where nums = 1;
这篇关于MySQL去重-字段左右相反依旧视为同一条数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



