本文主要是介绍统计观测自画像VS实际规律自画像:数据建构(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、吧啦吧啦
2、一张决策设计图
3、建构数据
4、统计观测自画像
5、实际规律自画像
6、如何检测你用的方法是否准确
想到很多标题,如:
建构数据(2):让决策科学化
建构数据(2):思维规律的外显
建构数据(2):统计规律可信度的测量方法
建构数据(2):id3算法让你火眼金睛
……
今天主要展示一个有趣的现象,如题。
1、吧啦吧啦
数据结构树、图的新型应用。
数据建构方法只是一种中介性工具,行业、领域、业务知识是内核。
方法的应用对你是有要求的:你要懂得数据的内在规律、客观规律。
正向应用场景:
如果你是师傅,在传授一个工艺流程时,可能将几十年缩短为几年;
如果你是老师,一段代码输出的结果,可将原理、算法中的必要过程清晰表达,避免知识背景、情感心态、个人认知带来的信息丢失;
如果你是研究者,建构数据的灵活运用让你如虎添翼;
如果你是管理者,当你定义一个岗位职责时,可以通过建构数据建立岗位模型,精确定义岗位逻辑,精确统一思路。
……
反思:
在上述场景中的大多是实干型角色,对一些偏艺术、偏智慧角色来说更多的是需要来自心性上的打磨,建议适当了解,不必过多依赖。
2、一张决策设计图
如果从现实场景出发任意定义一种逻辑流程,这是一件比较考验我想象力和创造力的事,那么,就直接以模型的形式给出好了。
决策模型结构:

这个决策模型能不能成为模型,取决于实际生活中有没有这样的思维或逻辑流程。当然,我这里只是一种设计图,可能有意义,可能没有实际意义,不过这么没关系,因为这只是“渔”。
圆角矩形是决策节点,A、B、C、D、E代表具有某种内在关联的决策依据。圆是叶子节点,代表决策结果:Y表示决策成立,或某种概念成立,或某种类别成立,N表示不成立。
这个模型整体含义是:一个决策(或者说是判定)取决于依据A、B、C、D、E(或者说是状态、特征、属性等,它们对于决策成立的影响有范围、比重的区别),它们不同的值的组合(一条因果链、判断链上的路径)共同决定决策结果。
3、建构数据
从决策模型得出,各特征取值如下:
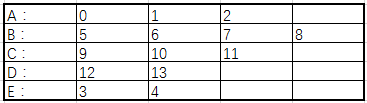
决策路径的符号描述:
Decision=(Reasons,Actions)
Reasons=(A,B,C,D,E)
Actions=(‘yes’,’no’)
A=(0,1,2)
B=(5,6,7,8)
C=(9,10,11)
D=(12,13)
E=(3,4)
具体决策路径:
d1=(A=0,E=3,B=6,’no’)
d2=(A=0,E=3,B=7,’yes’)
d3=(A=0,E=4,’yes’)
d4=(A=1,C=10,B=5,’no’)
d5=(A=1,C=10,B=8,’yes’)
d6=(A=1,C=9,’yes’)
d7=(A=1,C=11,’no’)
d8=(A=2,D=13,B=6,’yes’)
d9=(A=2,D=13,B=8,’no’)
d10=(A=2,D=12,’yes’)
数据生成原则:每个样本只能符合一条决策路径,该路径外的冗余特征将在内部随机取值。每个样本是唯一的。
数据生成方法有很多,可以先组合生成,再随机选取;也可以先随机选择路径,再取舍回溯。

这次只生成十个样本集(当然可以更多),每个样本集表现为三个文件:数据,决策树,决策代码。
4、统计观测自画像
第一组数据来自datapro0,我们不妨来详细分析一下:

首先看各个样本(注意,样本是一个从外部观察的概念)所属的决策路径:
d1=(A=0,E=3,B=6,’no’)
d2=(A=0,E=3,B=7,’yes’)
d3=(A=0,E=4,’yes’)
d4=(A=1,C=10,B=5,’no’)
d5=(A=1,C=10,B=8,’yes’)
d6=(A=1,C=9,’yes’)
d7=(A=1,C=11,’no’)
d8=(A=2,D=13,B=6,’yes’)
d9=(A=2,D=13,B=8,’no’)
d10=(A=2,D=12,’yes’)
(很为你着想吧)

datapro0样本集决策树:

是不是和最初设计的决策树很不一样?这是为什么呢?
原因很简单:
id3一种统计观测型算法,是一种通过外在观察得出的分类模式;
id3处理的方式是以“列”为单位,即只通过每个特征取值的分布情况来建立一种分类模式,从而忽略特征与特征之间的内在逻辑与关联;
那也许你就要问,这里才24个样本,要完整得到当初设计的决策树,必须要完整样本集:也就是所有路径的所有可能都要有。
想法很好,今晚就不去实验了,下次再整。不过,从id3的算法过程来看,特征B的取值是最多的,相当大的概率不会同意第一个判断对象是A。

将决策树生成决策代码,更能从逻辑上分析样本的内在规律与外在表现之间的区别,甚至有的’yes’与’no’根本无法从原始决策树的决策路径去理解。但是外在表现的数据样本硬是能得出一种全新的规律。
仿佛就是在说,内在规律和外在表现规律,你说你的,我说我的,但咱俩是等价的。
这实际上是一个极老套的问题:
内涵=外延
只不过,一阵观测统计之后,外延能够被逻辑化。
其他(第二次改版啦,修正了一些小瑕疵,但不影响观点):



第二组



第三组



第四组
请欣赏(对于csdn能直接复制图片过来就可上传的功能点赞):






5、实际规律自画像
这个小标题其实也可以叫做:千变万化不离其宗,看我本来面目。

6、如何检测你用的方法是否准确
直接通过数学方法来处理当然是好,可是,你也不妨先针对方法内建规律,再生成数据,最后用统计方法检测,判断。
如果效果较好,那么应用在实际场景中,效果也较好。
这篇关于统计观测自画像VS实际规律自画像:数据建构(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




