本文主要是介绍MySQL库和表的操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 什么是数据库?什么是SQL?
科学的组织和存储数据,如何高效获取和维护数据
2 一条SQL语句的执行过程
SQL语句就是一个数据库能够识别的指令语言
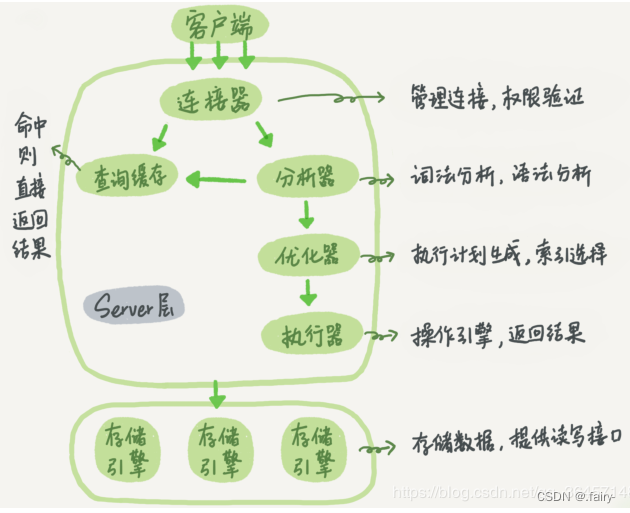
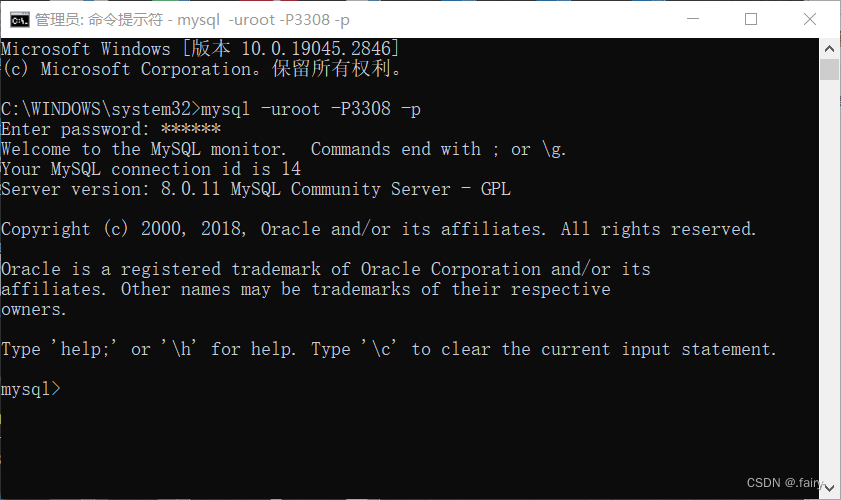
在实际操作过程中,创建连接,连接MySQL的server
mysql -uroot -P3308 -p以管理员身份打开命令提示符,输入密码即连接成功
3 库的增删改查
# 查看库
show databases;
# 创建某个库
create database 库名 charset utf8;
# 查看某个库
show create database 库名;
# 修改库的编码
alter database 库名 charset
# 删除某个库
drop database 库名;4 表的增删改查
增
create table stu(id int primary key auto_increment,name char(16) not null,age int not null)
# 数据类型
字符串 char(6) varchar(6) sql_mode 截断 以空间换时间
整型 int
小数 float(5,2) decimal double
日期 date datetime
枚举:enum set()# 约束条件
not null
unique
primary key 索引密切相关 查询效率
foreign key问题:
char与varchar的区别
1 定长和变长
2 存储方式
char存取速度快 varchar节省空间
改
# 修改表的名称
alter table stu rename stu_new;
# 修改表的数据类型
alter table stu_new modify name varchar(16);
# 修改表的字段名及数据类型(修改完字段名需要带上数据类型和约束条件)
alter table stu_new change name name_new char(16) not null;
# 新增字段
alter table stu_new add sex enum("男","女");
# 删除字段
alter table stu_new drop name, drop age;查
# desc 表名
desc stu_new;
# show create table 表名 \G;
show create table stu_new \G;删
# drop table 表名
drop table stu_new;5 记录的增删改查
增
# 语法1:insert into 表名 values(值1,值2,值3....)
# 语法2:insert into 表名(字段1,字段2) values (值1,值2)改
# 语法:update 表名 set 字段 = 新值 where 条件删
delete from 表名 where 条件;注:不加where条件就是清空表,一定要慎重使用delete清空表:delete from t1; # 如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。truncate table t1;# 数据量大,删除速度比上一条快,且直接从零开始,查(单表查询+多表查询)
单表查询
语法:
select distinct 字段1,字段2 [,...] from 表名where 条件group by fieldhaving 筛选条件order by filedlimit 条数
注:group by field 根据什么进行分组,一般是某个字段或多个字段order by filed 根据什么进行排序,一般是某个字段或多个字段having主要配合group by使用,对分组后的数据进行过滤,里面可以使用聚合函数where是针对select查询的过滤,各有区别和用处优先级:fromwheregroup byselectdistincthavingorder bylimit
解释说明:1.先找到表:from2.拿着where指定的约束条件,去表中取出符合条件的一条条数据3.将取出的数据进行分组group by,如果没有group by,则每行为一组4.执行select 查询所指定的字段5.若有distinct 则去重6.将结果按照条件排序 order by7.限制结果的显示条数 limit问题:为什么having后面可以跟聚合函数,而where却不可以
单表查询所需数据
create table emp(id int primary key auto_increment,emp_name char(20) not null,sex enum("male","female") not null default "male",age int(3) unsigned not null default 28,hire_date date not null,post char(50),post_comment char(100),salary double(15,2),office int,depart_id int);-- 插入数据
-- 以下是教学部
insert into emp(emp_name,sex,age,hire_date,post,salary,office,depart_id) values
('huahua','male',18,'20170301','teacher',7300.33,401,1),
('weiwei','male',78,'20150302','teacher',1000000.31,401,1),
('lala','male',81,'20130305','teacher',8300,401,1),
('zhangsan','male',73,'20140701','teacher',3500,401,1),
('liulaogen','male',28,'20121101','teacher',2100,401,1),
('aal','female',18,'20110211','teacher',9000,401,1),
('zhugelang','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),-- 以下是销售部门
('歪歪','female',48,'20150311','sale',3000.13,402,2),
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),-- 以下是运营部门
('张野','male',28,'20160311','operation',10000.13,403,3),
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;题目
1 查询姓名末尾的那个字符
substring(string,position,length); mid(文本,截止字符的起点,截多长)例如:select emp_name,substring(emp_name,-1) as new_name from emp;
2 查询以"程"开头的三个字的员工信息(_ %) excel(?*)select * from emp where emp_name like "程__";
3 查询以"z"开头的员工信息select * from emp where emp_name like "z%";
4 计算每个部门都有多少人?大于6个人的部门有哪些?select post,count(emp_name) 人数 from emp group by post having count(emp_name) > 6;
5 计算每个部门的平均工资并从高到低排序select post,avg(salary) as avg_salary from emp group by post;
6 更新
提示:
单独更新一个字段 update 表名 set 字段1 = 新值1,where 条件;更新多个字段 update 表名 set 字段1 = 新值1,字段2 = 新值2where 条件;如果部门为教学部,则post_comment填写:优质课程,优秀讲师,棒棒哒
如果部门为销售部,则post_comment填写:每个人都是公司的一张名片
如果部门为运营部,则post_comment填写:好的运营,一定是节约成本的同时带来最大的收益
多表查询
准备数据
create table dep(id int primary key,name char(20)
);
create table emp(id int primary key auto_increment,name char(20),sex enum("male","female") not null default "male",age int,dep_id int
);-- 插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');insert into emp(name,sex,age,dep_id) values
('ailsa','male',18,200),
('lala','female',48,201),
('huahua','male',38,201),
('zhangsan','female',28,202),
('zhaosi','male',18,200),
('shenteng','female',18,204)
;题目
1 连表查询 查询每个部门的员工信息?查询每个员工所在部门信息?查询所有员工及所有部门的员工部门信息?
2 子查询 查询平均年龄在25岁以上的部门名
3 查询大于所有人平均年龄的员工与年龄
复杂的多表查询
准备数据
CREATE TABLE class (cid int(11) NOT NULL AUTO_INCREMENT,caption varchar(32) NOT NULL,PRIMARY KEY (cid)
) ENGINE=InnoDB CHARSET=utf8;INSERT INTO class VALUES
(1, '三年二班'),
(2, '三年三班'),
(3, '一年二班'),
(4, '二年九班');CREATE TABLE teacher(tid int(11) NOT NULL AUTO_INCREMENT,tname varchar(32) NOT NULL,PRIMARY KEY (tid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO teacher VALUES
(1, '张蒙老师'),
(2, '李超老师'),
(3, '刘颜老师'),
(4, '朱西老师'),
(5, '李湿老师');CREATE TABLE course(cid int(11) NOT NULL AUTO_INCREMENT,cname varchar(32) NOT NULL,teacher_id int(11) NOT NULL,PRIMARY KEY (cid),KEY fk_course_teacher (teacher_id),CONSTRAINT fk_course_teacher FOREIGN KEY (teacher_id) REFERENCES teacher (tid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO course VALUES
(1, '生物', 1),
(2, '物理', 2),
(3, '体育', 3),
(4, '美术', 2);CREATE TABLE student(sid int(11) NOT NULL AUTO_INCREMENT,gender char(1) NOT NULL,class_id int(11) NOT NULL,sname varchar(32) NOT NULL,PRIMARY KEY (sid),KEY fk_class (class_id),CONSTRAINT fk_class FOREIGN KEY (class_id) REFERENCES class (cid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO student VALUES
(1, '男', 1, '理解'),
(2, '女', 1, '钢蛋'),
(3, '男', 1, '张三'),
(4, '男', 1, '张一'),
(5, '女', 1, '张二'),
(6, '男', 1, '张四'),
(7, '女', 2, '铁锤'),
(8, '男', 2, '李三'),
(9, '男', 2, '李一'),
(10, '女', 2, '李二'),
(11, '男', 2, '李四'),
(12, '女', 3, '如花'),
(13, '男', 3, '刘三'),
(14, '男', 3, '刘一'),
(15, '女', 3, '刘二'),
(16, '男', 3, '刘四');CREATE TABLE score (sid int(11) NOT NULL AUTO_INCREMENT,student_id int(11) NOT NULL,course_id int(11) NOT NULL,num int(11) NOT NULL,PRIMARY KEY (sid),KEY fk_score_student (student_id),KEY fk_score_course (course_id),CONSTRAINT fk_score_course FOREIGN KEY (course_id) REFERENCES course (cid),CONSTRAINT fk_score_student FOREIGN KEY (student_id) REFERENCES student(sid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO score VALUES
(1, 1, 1, 10),
(2, 1, 2, 9),
(5, 1, 4, 66),
(6, 2, 1, 8),
(8, 2, 3, 68),
(9, 2, 4, 99),
(10, 3, 1, 77),
(11, 3, 2, 66),
(12, 3, 3, 87),
(13, 3, 4, 99),
(14, 4, 1, 79),
(15, 4, 2, 11),
(16, 4, 3, 67),
(17, 4, 4, 100),
(18, 5, 1, 79),
(19, 5, 2, 11),
(20, 5, 3, 67),
(21, 5, 4, 100),
(22, 6, 1, 9),
(23, 6, 2, 100),
(24, 6, 3, 67),
(25, 6, 4, 100),
(26, 7, 1, 9),
(27, 7, 2, 100),
(28, 7, 3, 67),
(29, 7, 4, 88),
(30, 8, 1, 9),
(31, 8, 2, 100),
(32, 8, 3, 67),
(33, 8, 4, 88),
(34, 9, 1, 91),
(35, 9, 2, 88),
(36, 9, 3, 67),
(37, 9, 4, 22),
(38, 10, 1, 90),
(39, 10, 2, 77),
(40, 10, 3, 43),
(41, 10, 4, 87),
(42, 11, 1, 90),
(43, 11, 2, 77),
(44, 11, 3, 43),
(45, 11, 4, 87),
(46, 12, 1, 90),
(47, 12, 2, 77),
(48, 12, 3, 43),
(49, 12, 4, 87),
(52, 13, 3, 87);这五个表的联系
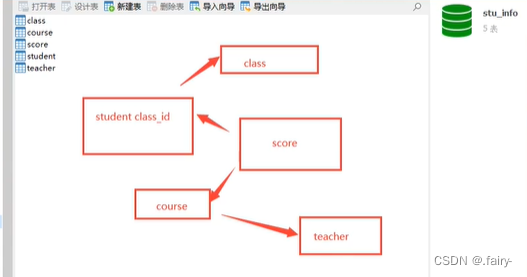
题目
1 查询成绩最好的前两名学生姓名
select * from stu where num = (select max(num) from stu)
union all
select * from stu where num = (select max(num) from stu where num<(select max(num) from stu));
2 查询每门课程成绩最好的前两名学生姓名
创建视图
虚拟的表
create view stu asselect s.sid,gender,sname,caption,cname,tname,num from student s
left join class c on s.class_id = c.cid
left join score s1 on s.sid = s1.student_id
left join course c1 on s1.course_id = c1.cid
left join teacher t on t.tid = c1.teacher_id第二题 查询每门课程成绩最好的前两名学生姓名
select s.* from stu s
left join
(select max(num) max_num,cname from stu group by cname ) s1 on s.cname = s1.cname
where num = max_num
union allselect s.* from stu s
left join(select s.cname,max(num) second_num from stu s
left join
(select max(num) max_num,cname from stu group by cname ) s1 on s.cname = s1.cname
where num < max_num
group by s.cname) m on s.cname = m.cname
where s.num = second_numorder by cname,num desc6 窗口函数
实现 查询每门课程成绩最好的前两名学生姓名
select * from (select *,dense_rank() over(order by num desc) as rank_num from stu) as e where rank_num<=2;介绍窗口函数
语法
完整语法
函数名([字段]) over(partition by 字段名 order by 字段名)
聚合函数:sum count avg max min
排名函数 row_number rank dense_rank ntile
其他:lag lead first_value last_value
聚合开窗的用法
-- 题目1 计算每个学生的及格科目数
select sname,count(sname) from stu where num>=60 group by sname;select *,count(sname) over(partition by sname) 及格的个数 from stu where num>=60
order by sname;-- 每个人的成绩与自己总的平均分的差距
select *, avg(num) over(partition by cname order by cname) as avg_score from stu where num>0
;排名开窗函数
select s.sid,s1.sname,s1.gender,c.cname,s.num, row_number() over
(partition by c.cname order by num desc) as row_number排名,
rank() over (partition by c.cname order by num desc) as rank排名,
dense_rank() over (partition by c.cname order by num desc) as dense_rank排名,
ntile(6) over (partition by c.cname order by num desc) as ntile排名
from score s join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid作弊次数的案例
select uid,count(uid) 作弊次数 from
(select *,lead(login_time,1) over(partition by uid order by login_time) as new_time,
TIMESTAMPDIFF(SECOND,login_time,(lead(login_time,1) over(partition by uid order by login_time) ))/60 相差秒数
from lag_table) as e
where 相差秒数<=2 group by uidlast_value
select s.sid,s1.sname,s1.gender,c.cname,s.num,
last_value(num) over(partition by c.cname order by c.cname) as last_value用法
from score s join student s1 on s.student_id = s1.sid
left join course c on s.course_id = c.cid这篇关于MySQL库和表的操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





