美剧《权力的游戏》终于要开播最后一季了,作为马丁老爷子的忠实粉丝,为了能够看得懂第八季复杂庞大的剧情架构,本人想着将前几季再稳固一下,所以就上美剧天堂下载来看,可是每次都上去下载太麻烦了,于是干脆自己写个爬虫爬下来得了。
话不多说,先上图片。
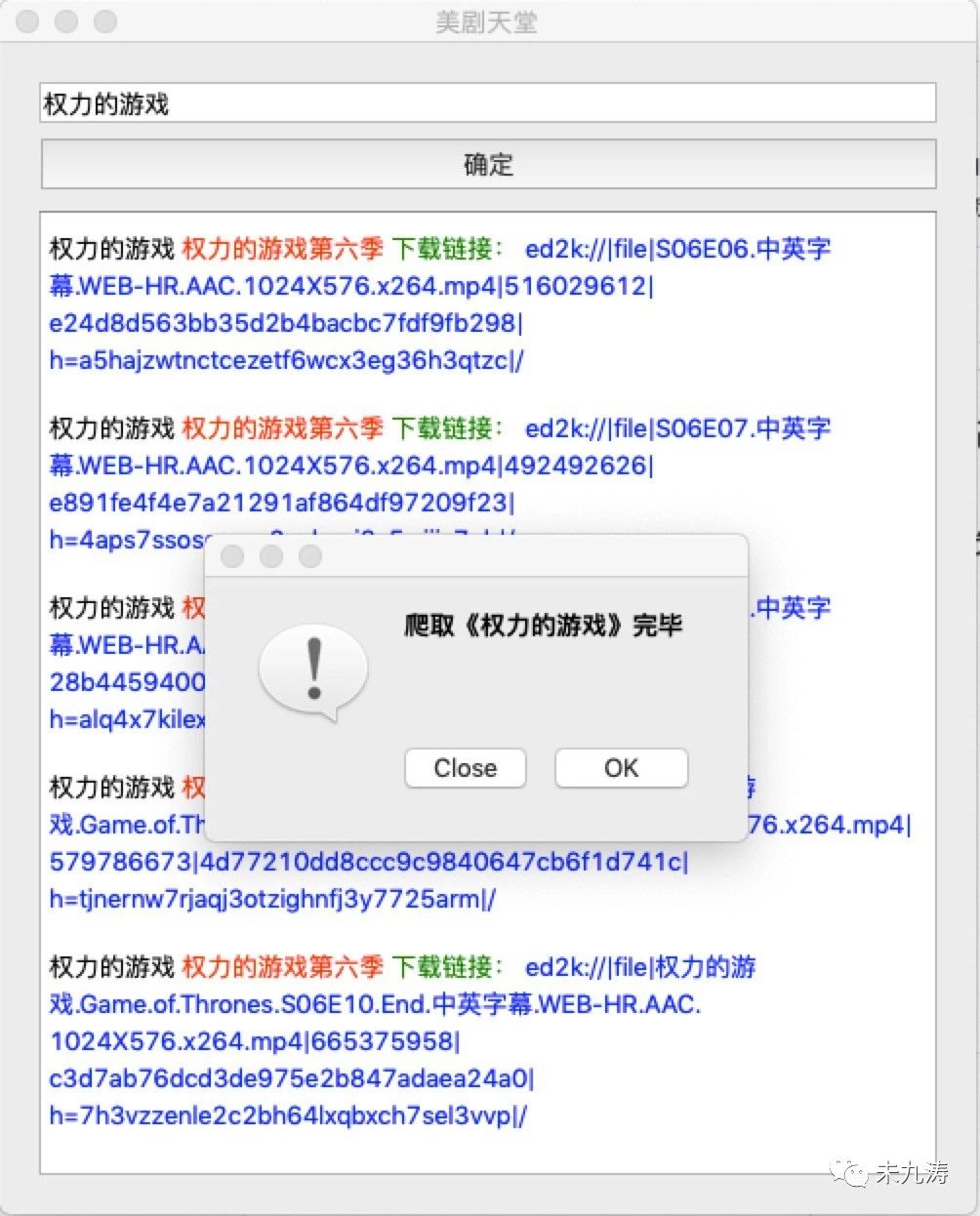
本人才疏学浅,就写了个简单的可视化软件,关键是功能实现就行了嘛。
实现语言:Python ,版本 3.7.1
实现思路:首先运用 Python 工具爬取到数据再实现图形化软件。
由于这里只是实现简单的爬取数据,并没有牵扯到 cookie 之类的敏感信息,也没有设置代理,所以在选择 Python 库上并没有引入 Selenium 或者更高级的 Scrapy 框架,只是拿到数据就可以了,没必要那么麻烦。
所以选择了 urllib 这个库,在 Python 2.X 中应该是 urllib 和 urllib2 同时引入,由于本人选用的版本的 Python 3.X ,在 Python 3.X 中上面两个库已经被合并为 urllib 一个库,语法上有些不同,但语言这种东西都是大同小异的嘛。
先贴代码,缓和一下尴尬的气氛。
1 import urllib.request 2 from urllib import parse 3 from lxml import etree 4 import ssl 5 from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox 6 import sys 7 8 # 取消代理验证 9 ssl._create_default_https_context = ssl._create_unverified_context 10 11 class TextEditMeiJu(QWidget): 12 def __init__(self, parent=None): 13 super(TextEditMeiJu, self).__init__(parent) 14 # 定义窗口头部信息 15 self.setWindowTitle('美剧天堂') 16 # 定义窗口的初始大小 17 self.resize(500, 600) 18 # 创建单行文本框 19 self.textLineEdit = QLineEdit() 20 # 创建一个按钮 21 self.btnButton = QPushButton('确定') 22 # 创建多行文本框 23 self.textEdit = QTextEdit() 24 # 实例化垂直布局 25 layout = QVBoxLayout() 26 # 相关控件添加到垂直布局中 27 layout.addWidget(self.textLineEdit) 28 layout.addWidget(self.btnButton) 29 layout.addWidget(self.textEdit) 30 # 设置布局 31 self.setLayout(layout) 32 # 将按钮的点击信号与相关的槽函数进行绑定,点击即触发 33 self.btnButton.clicked.connect(self.buttonClick) 34 35 # 点击确认按钮 36 def buttonClick(self): 37 # 爬取开始前提示一下 38 start = QMessageBox.information( 39 self, '提示', '是否开始爬取《' + self.textLineEdit.text() + "》", 40 QMessageBox.Ok | QMessageBox.No, QMessageBox.Ok 41 ) 42 # 确定爬取 43 if start == QMessageBox.Ok: 44 self.page = 1 45 self.loadSearchPage(self.textLineEdit.text(), self.page) 46 # 取消爬取 47 else: 48 pass 49 50 # 加载输入美剧名称后的页面 51 def loadSearchPage(self, name, page): 52 # 将文本转为 gb2312 编码格式 53 name = parse.quote(name.encode('gb2312')) 54 # 请求发送的 url 地址 55 url = "https://www.meijutt.com/search/index.asp?page=" + str(page) + "&searchword=" + name + "&searchtype=-1" 56 # 请求报头 57 headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"} 58 # 发送请求 59 request = urllib.request.Request(url, headers=headers) 60 # 获取请求的 html 文档 61 html = urllib.request.urlopen(request).read() 62 # 对 html 文档进行解析 63 text = etree.HTML(html) 64 # xpath 获取想要的信息 65 pageTotal = text.xpath('//div[@class="page"]/span[1]/text()') 66 # 判断搜索内容是否有结果 67 if pageTotal: 68 self.loadDetailPage(pageTotal, text, headers) 69 # 搜索内容无结果 70 else: 71 self.infoSearchNull() 72 73 # 加载点击搜索页面点击的本季页面 74 def loadDetailPage(self, pageTotal, text, headers): 75 # 取出搜索的结果一共多少页 76 pageTotal = pageTotal[0].split('/')[1].rstrip("页") 77 # 获取每一季的内容(剧名和链接) 78 node_list = text.xpath('//a[@class="B font_14"]') 79 items = {} 80 items['name'] = self.textLineEdit.text() 81 # 循环获取每一季的内容 82 for node in node_list: 83 # 获取信息 84 title = node.xpath('@title')[0] 85 link = node.xpath('@href')[0] 86 items["title"] = title 87 # 通过获取的单季链接跳转到本季的详情页面 88 requestDetail = urllib.request.Request("https://www.meijutt.com" + link, headers=headers) 89 htmlDetail = urllib.request.urlopen(requestDetail).read() 90 textDetail = etree.HTML(htmlDetail) 91 node_listDetail = textDetail.xpath('//div[@class="tabs-list current-tab"]//strong//a/@href') 92 self.writeDetailPage(items, node_listDetail) 93 # 爬取完毕提示 94 if self.page == int(pageTotal): 95 self.infoSearchDone() 96 else: 97 self.infoSearchContinue(pageTotal) 98 99 # 将数据显示到图形界面 100 def writeDetailPage(self, items, node_listDetail): 101 for index, nodeLink in enumerate(node_listDetail): 102 items["link"] = nodeLink 103 # 写入图形界面 104 self.textEdit.append( 105 "<div>" 106 "<font color='black' size='3'>" + items['name'] + "</font>" + "\n" 107 "<font color='red' size='3'>" + items['title'] + "</font>" + "\n" 108 "<font color='orange' size='3'>第" + str(index + 1) + "集</font>" + "\n" 109 "<font color='green' size='3'>下载链接:</font>" + "\n" 110 "<font color='blue' size='3'>" + items['link'] + "</font>" 111 "<p></p>" 112 "</div>" 113 ) 114 115 # 搜索不到结果的提示信息 116 def infoSearchNull(self): 117 QMessageBox.information( 118 self, '提示', '搜索结果不存在,请重新输入搜索内容', 119 QMessageBox.Ok, QMessageBox.Ok 120 ) 121 122 # 爬取数据完毕的提示信息 123 def infoSearchDone(self): 124 QMessageBox.information( 125 self, '提示', '爬取《' + self.textLineEdit.text() + '》完毕', 126 QMessageBox.Ok, QMessageBox.Ok 127 ) 128 129 # 多页情况下是否继续爬取的提示信息 130 def infoSearchContinue(self, pageTotal): 131 end = QMessageBox.information( 132 self, '提示', '爬取第' + str(self.page) + '页《' + self.textLineEdit.text() + '》完毕,还有' + str(int(pageTotal) - self.page) + '页,是否继续爬取', 133 QMessageBox.Ok | QMessageBox.No, QMessageBox.No 134 ) 135 if end == QMessageBox.Ok: 136 self.page += 1 137 self.loadSearchPage(self.textLineEdit.text(), self.page) 138 else: 139 pass 140 141 142 if __name__ == '__main__': 143 app = QApplication(sys.argv) 144 win = TextEditMeiJu() 145 win.show() 146 sys.exit(app.exec_())
以上是实现功能的所有代码,可以运行 Python 的小伙伴直接复制到本地运行即可。都说 Python 是做爬虫最好的工具,写完之后发现确实是这样。
我们一点点分析代码:
1 import urllib.request 2 from urllib import parse 3 from lxml import etree 4 import ssl 5 from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox, QLabel 6 import sys
以上为我们引入的所需要的库,前 4 行是爬取 美剧天堂 官网所需要的库,后两个是实现图形化应用所需的库。
我们先来看一下如何爬取网站信息。
由于现在 美剧天堂 使用的是 https 协议,进入页面需要代理验证,为了不必要的麻烦,我们干脆取消代理验证,所以用到了 ssl 模块。
然后我们就可以正大光明的进入网站了:https://www.meijutt.com/
令人遗憾的是 url 链接为 https://www.meijutt.com/search/index.asp ,显然没有为我们提供任何有用的信息,当我们刷新页面时,如下图:
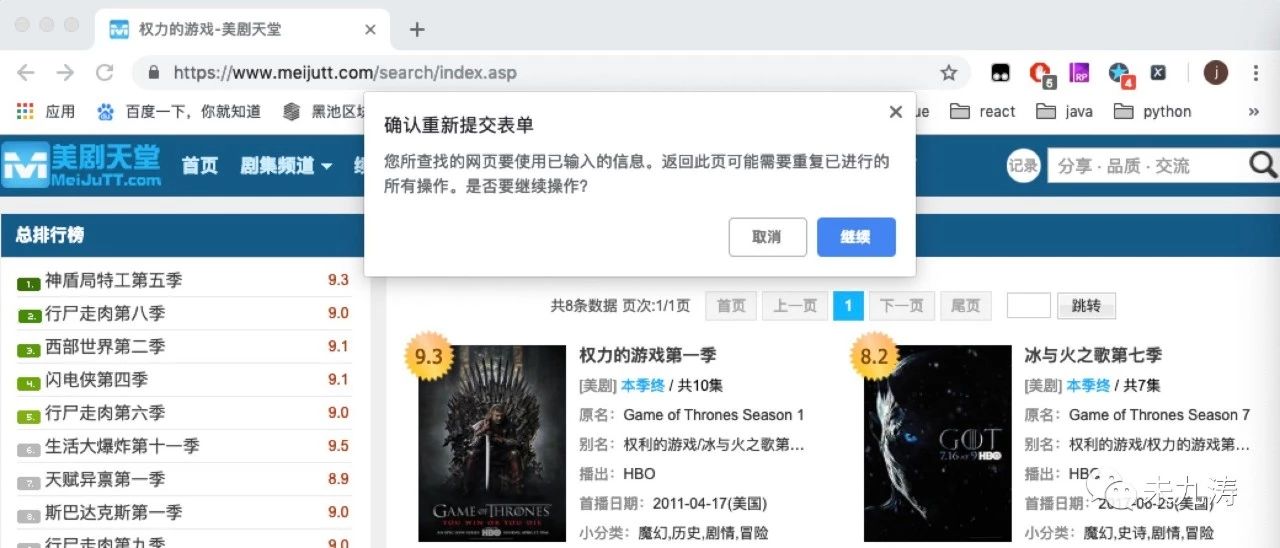
当我们手动输入 ulr 链接 https://www.meijutt.com/search/index.asp 进行搜索时:

很明显了,当我们在首页输入想看的美剧并搜索时网站将我们的请求表单信息隐藏了,并没有给到 url 链接里,但是本人可不想每次都从首页进行搜索再提交表单获取信息,很不爽,还好本人发现了一个更好的方法。如下图:
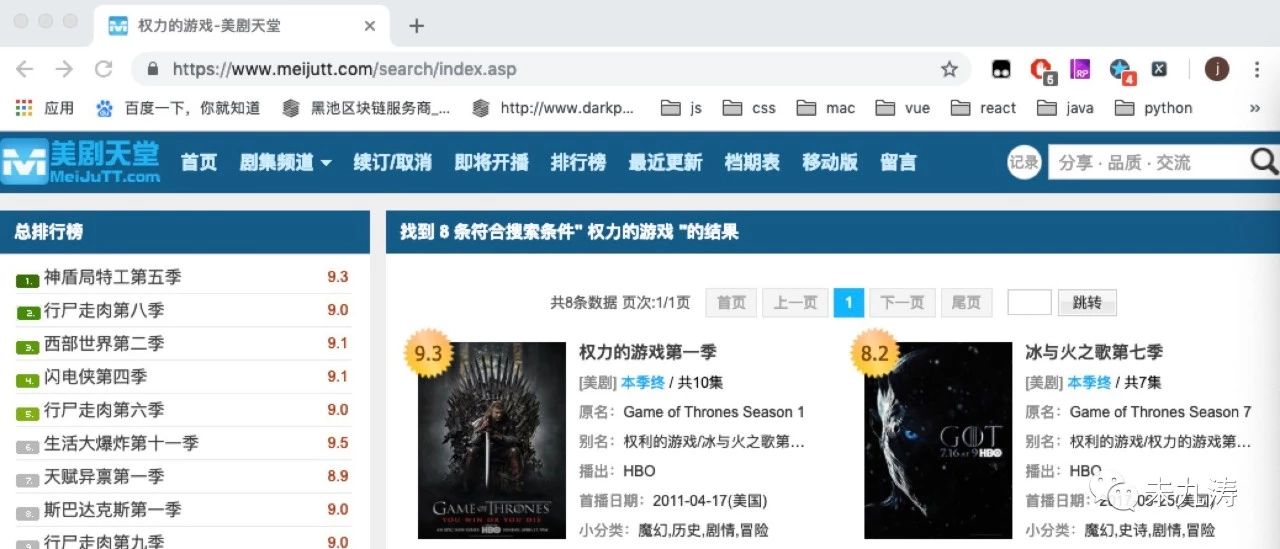
在页面顶部有一个页面跳转的按钮,我们可以选择跳转的页码,当选择跳转页码后,页面变成了如下:

url 链接已经改变了:https://www.meijutt.com/search/index.asp?page=&searchword=%C8%A8%C1%A6%B5%C4%D3%CE%CF%B7&searchtype=-1
我们再将 page 中动态添加为 page=1 ,页面效果不变。
经过搜索多个不同的美剧的多次验证发现只有 page 和 searchword 这两个字段是改变的,其中 page 字段默认为 1 ,而其本人搜索了许多季数很长的美剧,比如《老友记》、《生活大爆炸》、《邪恶力量》,这些美剧也就一页,但仍有更长的美剧,比如《辛普森一家》是两页,《法律与秩序》是两页,这就要求我们对页数进行控制,但是需要特别注意的是如果随意搜索内容,比如在搜索框只搜索了一个 ”i“,整整搜出了 219 页,这要扒下来需要很长的时间,所以就需要对其搜索的页数进行控制。
我们再来看一下 searchword 字段,将 searchword 字段解码转成汉字:
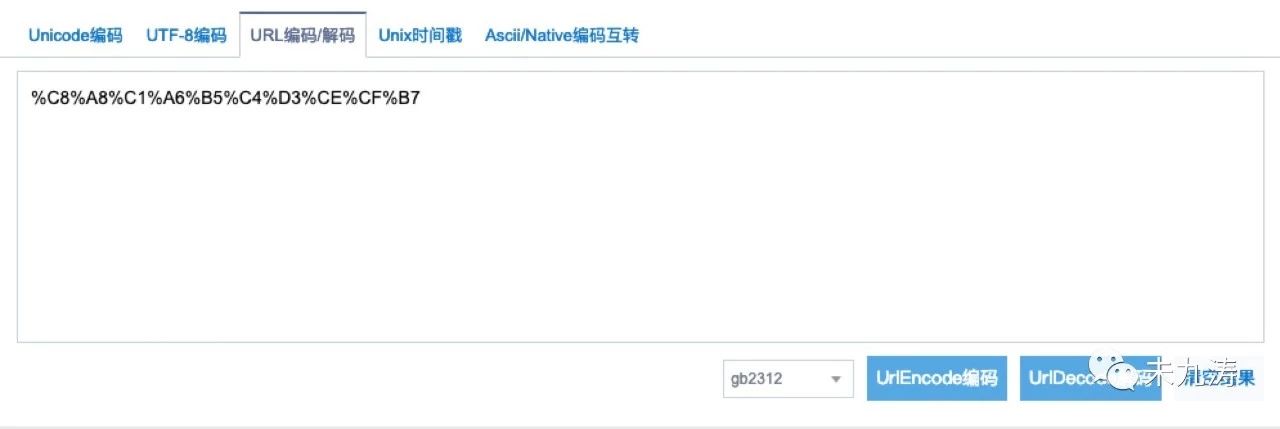
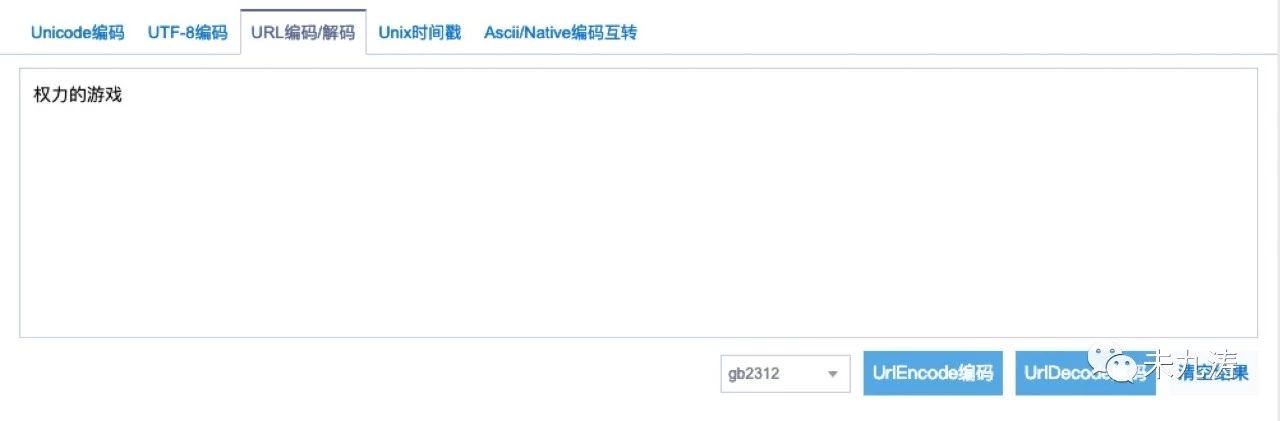
没错,正是我们想要的,万里长征终于实现了第一步。
1 # 加载输入美剧名称后的页面 2 def loadSearchPage(self, name, page): 3 # 将文本转为 gb2312 编码格式 4 name = parse.quote(name.encode('gb2312')) 5 # 请求发送的 url 地址 6 url = "https://www.meijutt.com/search/index.asp?page=" + str(page) + "&searchword=" + name + "&searchtype=-1" 7 # 请求报头 8 headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"} 9 # 发送请求 10 request = urllib.request.Request(url, headers=headers) 11 # 获取请求的 html 文档 12 html = urllib.request.urlopen(request).read() 13 # 对 html 文档进行解析 14 text = etree.HTML(html) 15 # xpath 获取想要的信息 16 pageTotal = text.xpath('//div[@class="page"]/span[1]/text()') 17 # 判断搜索内容是否有结果 18 if pageTotal: 19 self.loadDetailPage(pageTotal, text, headers) 20 # 搜索内容无结果 21 else: 22 self.infoSearchNull() 23
接下来我们只需要将输入的美剧名转化成 url 编码格式就可以了。如上代码,通过 urllib 库对搜索的网站进行操作。
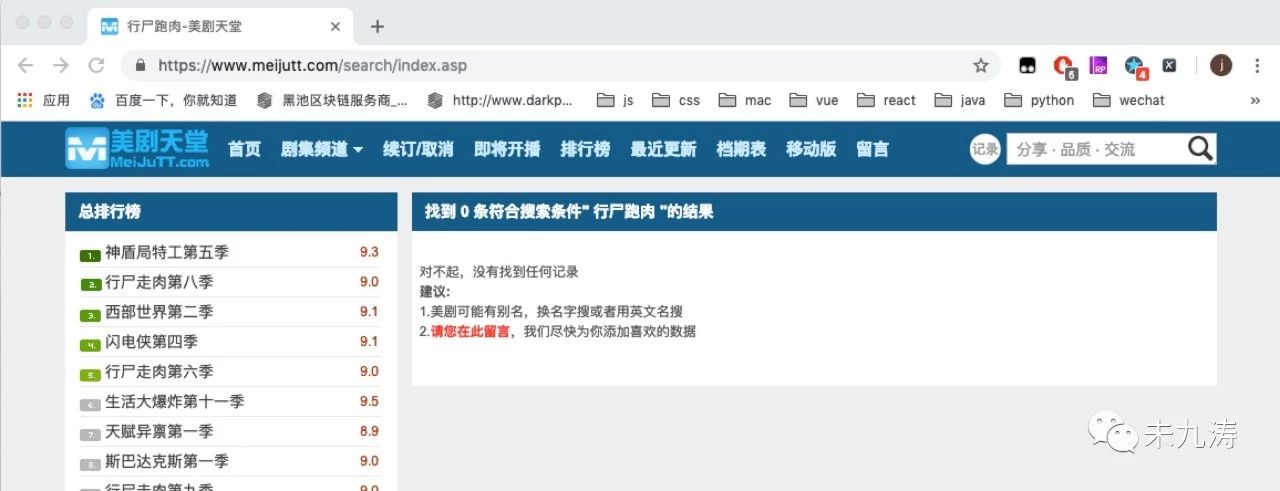
其中我们还需要做判断,搜索结果是否存在,比如我们搜索 行尸跑肉,结果不存在。
当搜索结果存在时:

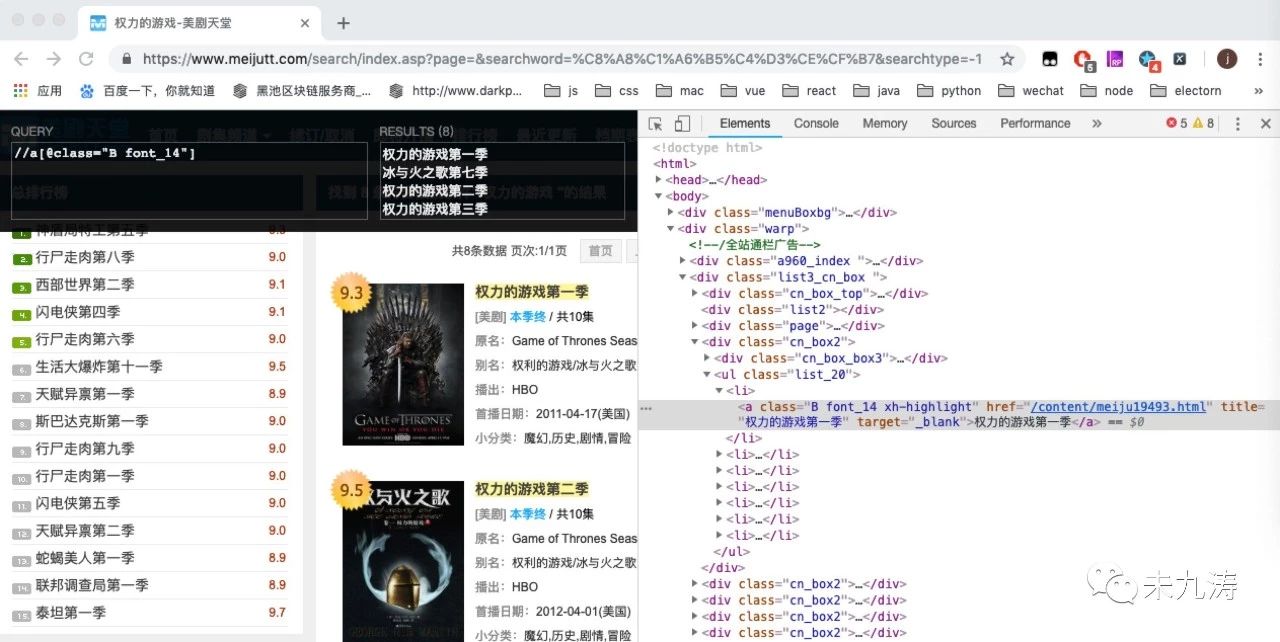
我们通过谷歌的 xpath 插件对页面内的 dom 进行搜索,发现我们要选取的 class 类名,关于谷歌插件本人之前的文章讲过一些 https://www.cnblogs.com/weijiutao/p/10608107.html,这里就不多说了。
我们根据获取到的页数,找到所有页面里我们要搜索的信息:
1 # 加载点击搜索页面点击的本季页面 2 def loadDetailPage(self, pageTotal, text, headers): 3 # 取出搜索的结果一共多少页 4 pageTotal = pageTotal[0].split('/')[1].rstrip("页") 5 # 获取每一季的内容(剧名和链接) 6 node_list = text.xpath('//a[@class="B font_14"]') 7 items = {} 8 items['name'] = self.textLineEdit.text() 9 # 循环获取每一季的内容 10 for node in node_list: 11 # 获取信息 12 title = node.xpath('@title')[0] 13 link = node.xpath('@href')[0] 14 items["title"] = title 15 # 通过获取的单季链接跳转到本季的详情页面 16 requestDetail = urllib.request.Request("https://www.meijutt.com" + link, headers=headers) 17 htmlDetail = urllib.request.urlopen(requestDetail).read() 18 textDetail = etree.HTML(htmlDetail) 19 node_listDetail = textDetail.xpath('//div[@class="tabs-list current-tab"]//strong//a/@href') 20 self.writeDetailPage(items, node_listDetail) 21 # 爬取完毕提示 22 if self.page == int(pageTotal): 23 self.infoSearchDone() 24 else: 25 self.infoSearchContinue(pageTotal) 26
我们根据获取到的链接,再次通过 urllib 库进行页面访问,即我们手动点击进入其中的一个页面,比如 权利的游戏第一季,再次通过 xpath 获取到我们所需要的下载链接:
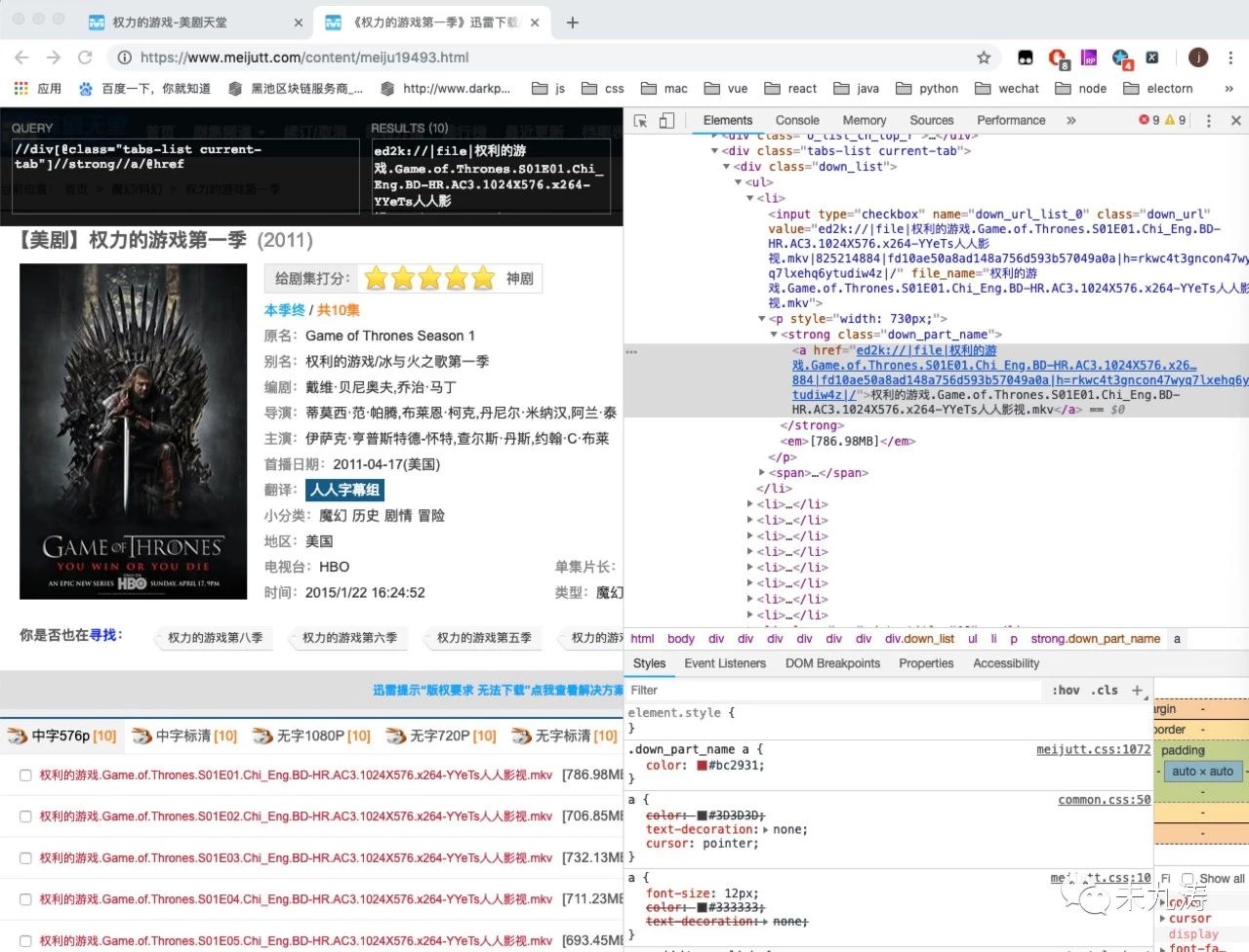
至此我们就将所有我们搜索到的 权力的游戏 的下载链接拿到手了,接下来就是写图形界面了。
本人选用了 PyQt5 这个框架,它内置了 QT 的操作语法,对于本人这种小白用起来也很友好。至于如何使用本人也都在代码上添加了注释,在这儿做一下简单的说明,就不过多解释了。
1 from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox, QLabel 2 import sys
将获取的信息写入搜索结果内:
1 # 将数据显示到图形界面 2 def writeDetailPage(self, items, node_listDetail): 3 for index, nodeLink in enumerate(node_listDetail): 4 items["link"] = nodeLink 5 # 写入图形界面 6 self.textEdit.append( 7 "<div>" 8 "<font color='black' size='3'>" + items['name'] + "</font>" + "\n" 9 "<font color='red' size='3'>" + items['title'] + "</font>" + "\n" 10 "<font color='orange' size='3'>第" + str(index + 1) + "集</font>" + "\n" 11 "<font color='green' size='3'>下载链接:</font>" + "\n" 12 "<font color='blue' size='3'>" + items['link'] + "</font>" 13 "<p></p>" 14 "</div>" 15 )
因为可能有多页情况,所以我们得做一次判断,提示一下剩余多少页,可以选择继续爬取或停止,做到人性化交互。
1 # 搜索不到结果的提示信息 2 def infoSearchNull(self): 3 QMessageBox.information( 4 self, '提示', '搜索结果不存在,请重新输入搜索内容', 5 QMessageBox.Ok, QMessageBox.Ok 6 ) 7 8 # 爬取数据完毕的提示信息 9 def infoSearchDone(self): 10 QMessageBox.information( 11 self, '提示', '爬取《' + self.textLineEdit.text() + '》完毕', 12 QMessageBox.Ok, QMessageBox.Ok 13 ) 14 15 # 多页情况下是否继续爬取的提示信息 16 def infoSearchContinue(self, pageTotal): 17 end = QMessageBox.information( 18 self, '提示', '爬取第' + str(self.page) + '页《' + self.textLineEdit.text() + '》完毕,还有' + str(int(pageTotal) - self.page) + '页,是否继续爬取', 19 QMessageBox.Ok | QMessageBox.No, QMessageBox.No 20 ) 21 if end == QMessageBox.Ok: 22 self.page += 1 23 self.loadSearchPage(self.textLineEdit.text(), self.page) 24 else: 25 pass
demo 图形化软件操作如下:
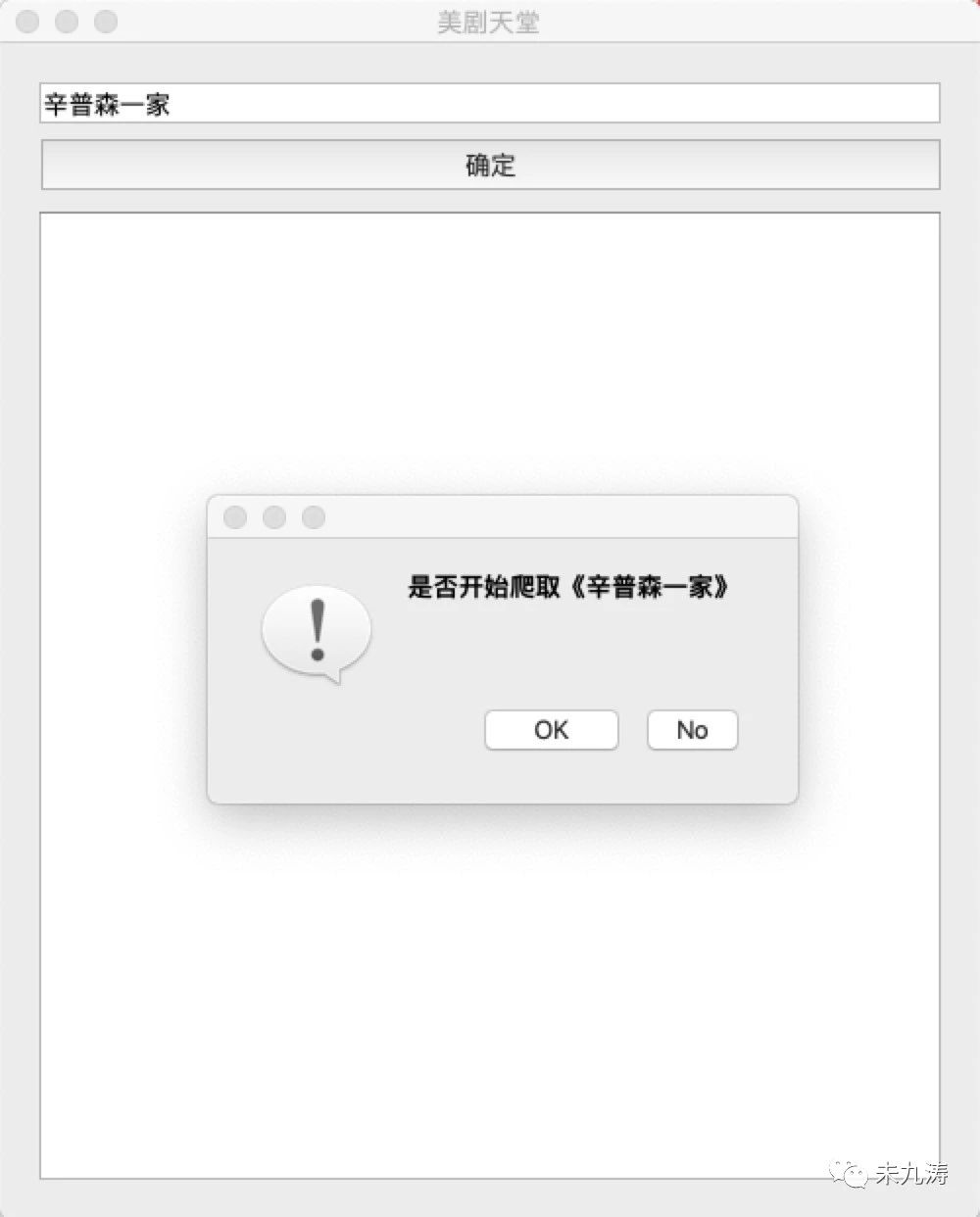
在搜索框内输入要搜索的美剧名,点击确认。提示一下是否要爬取,点击 No 不爬取,点击 OK 爬取。
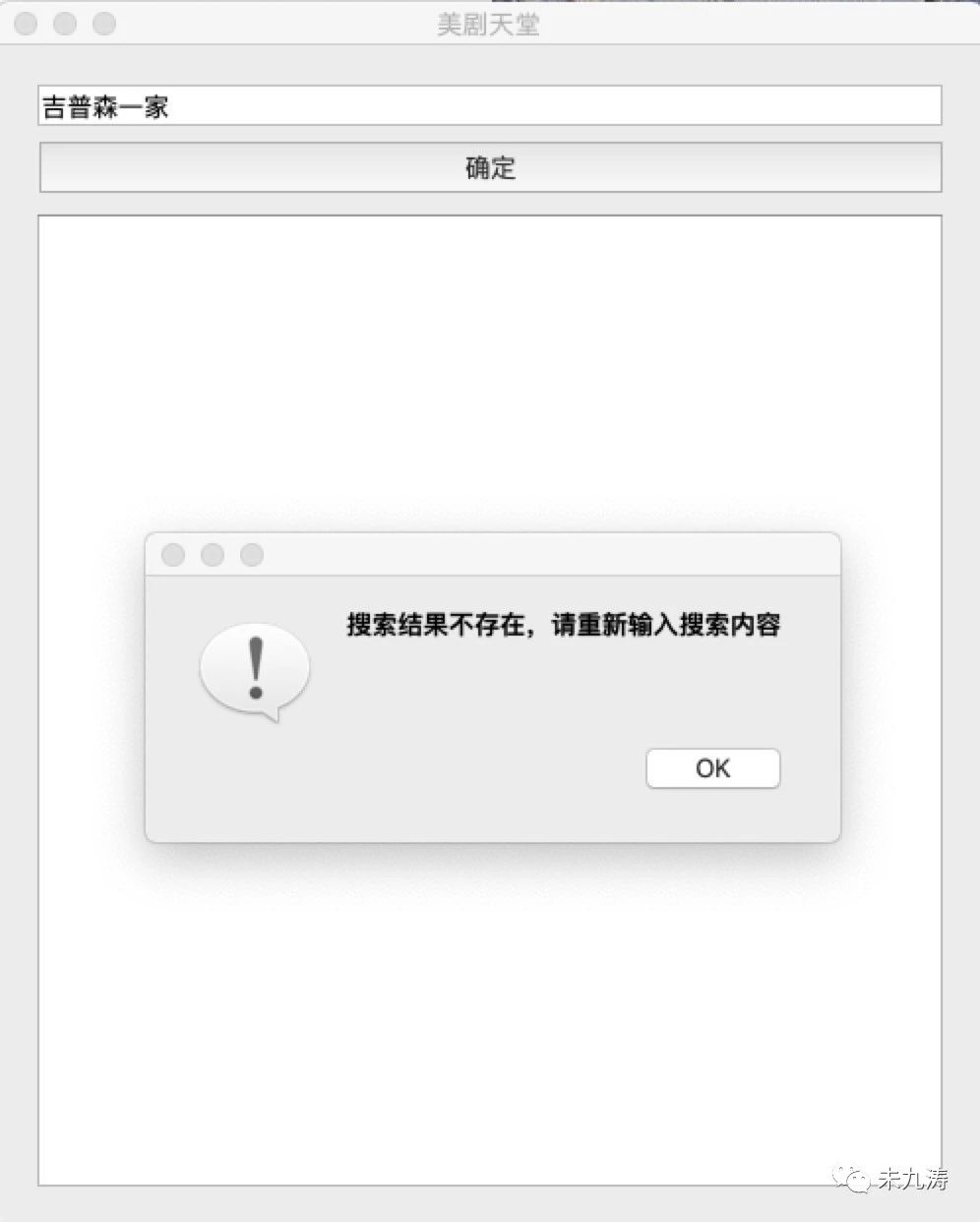
判断一下是否存在搜索结果,比如吧 ”辛普森一家“ 换成了 ”吉普森一家“,搜索内容不存在。
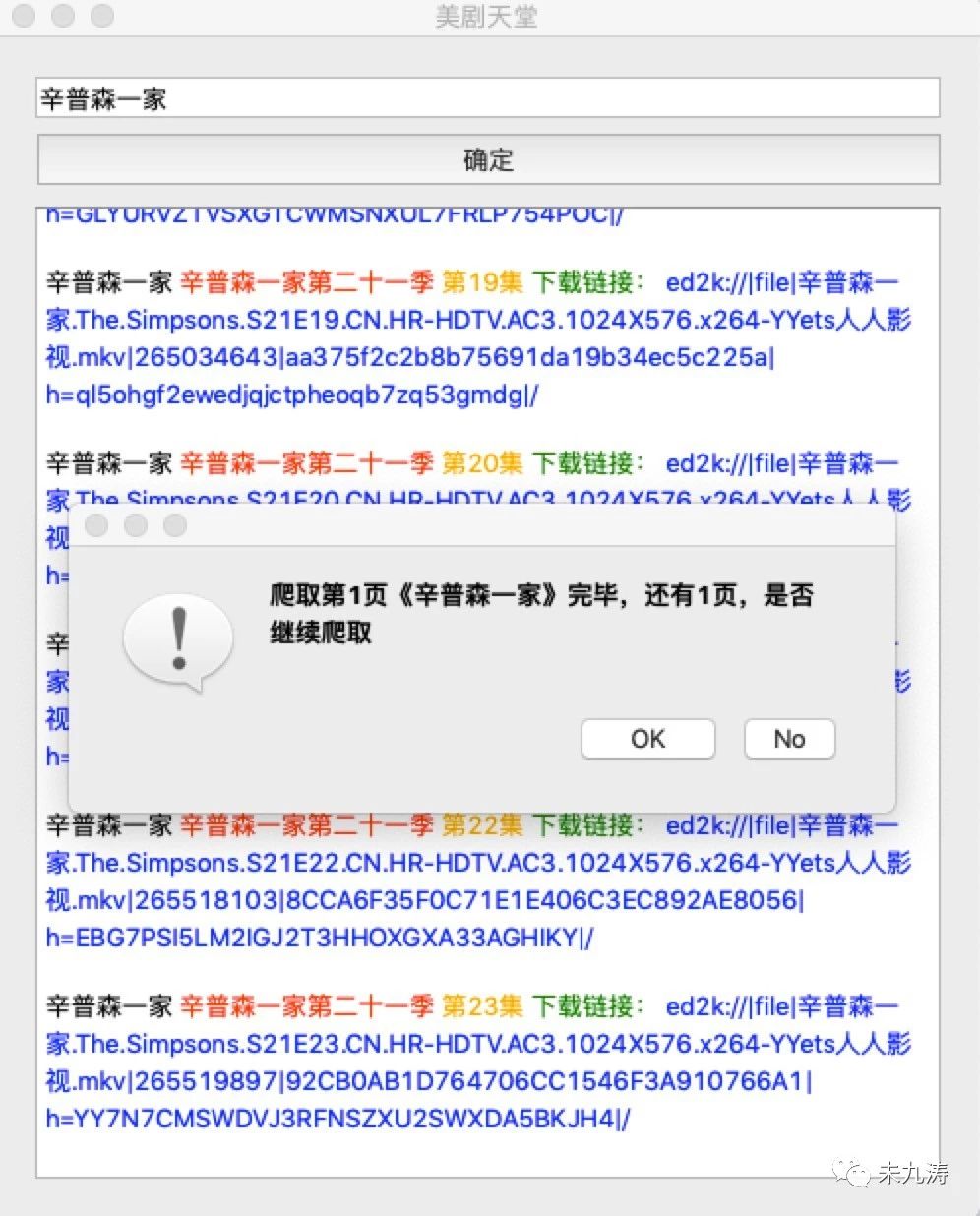
如果搜索内容存在,在搜索完成第一页后提示一下是否需要继续爬取,点击 No 表示停止爬取,点击 OK 表示继续爬取。
最后爬取完毕后提示爬取完毕:
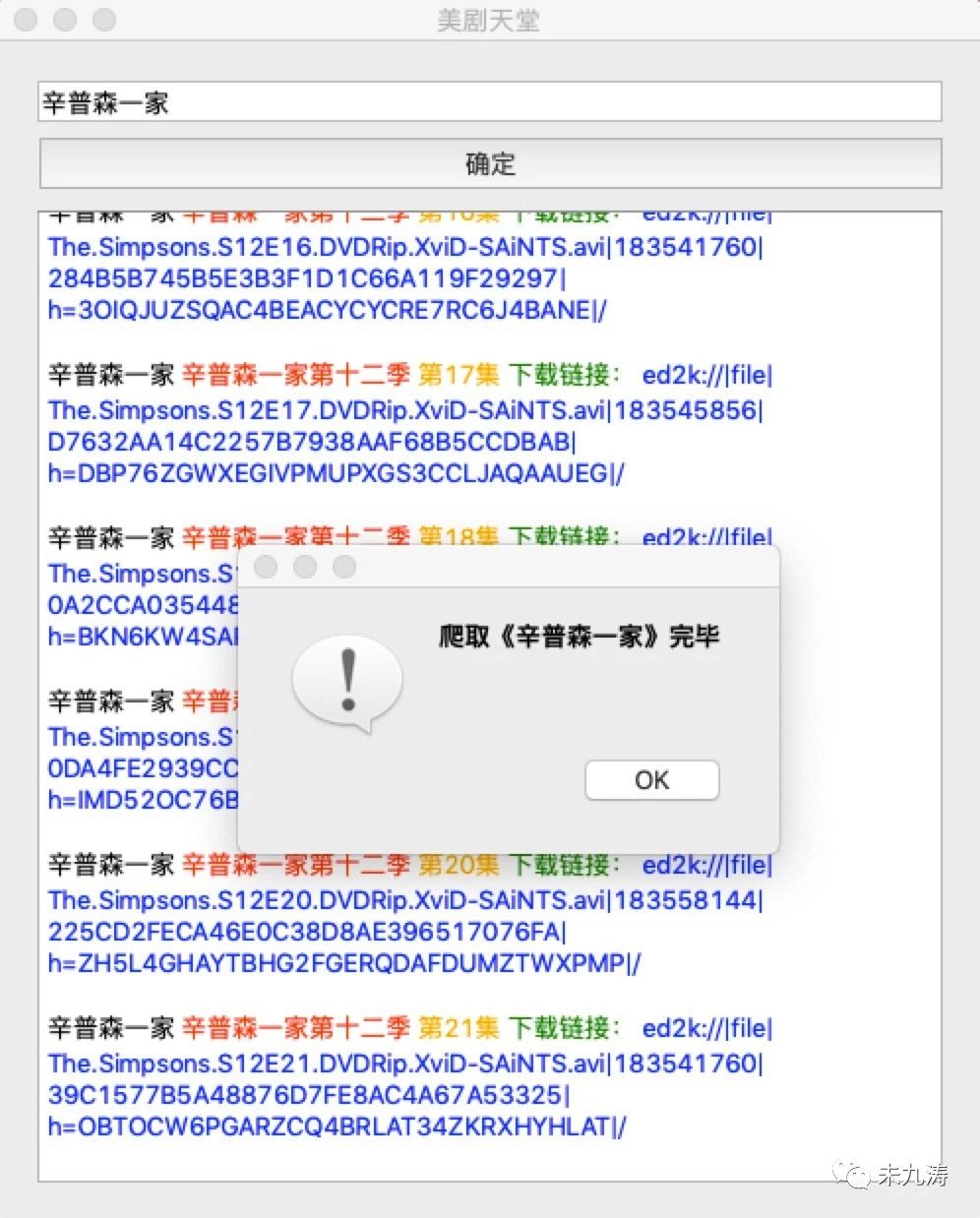
由于本人对 Python 了解不深,代码中有很多不足之处,需要不断学习改进,代码中有任何要改进的地方请各位大佬批评指教!
最后本人做了一套包含 Mac 和 windows 版的图形化美剧天堂抓包程序,只需要在对应电脑上点击运行即可,需要的小伙伴可以在本人的公众号后台回复 美剧天堂 就可以拿到了,注:在 windows 上打包生成的 .exe 软件第一打开时被 360 阻止,大家允许操作就可以了,Mac 无此提示。
好记性不如烂笔头,特此记录,与君共勉!






