本文主要是介绍sonic轻量级的搜索引擎,极致的性能,只用来单纯的查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
sonic是利用rust语言开发的一款轻量级快捷纯净的搜索引擎,不适用于windows系统上部署,比较适合在docker容器上部署
1.在ubuntu上启动docker容器
2.在docker容器上下载sonic的镜像文件
docker pull valeriansaliou/sonic:v1.2.0下载完成后,我们需要配置一份配置文件,比如说sonic的服务器端口号呀等等
配置文件内容如下:
# Sonic
# Fast, lightweight and schema-less search backend
# Configuration file
# Example: https://github.com/valeriansaliou/sonic/blob/master/config.cfg[server]log_level = "debug"[channel]inet = "0.0.0.0:1491"
tcp_timeout = 300auth_password = "SecretPassword"[channel.search]query_limit_default = 10
query_limit_maximum = 100
query_alternates_try = 4suggest_limit_default = 5
suggest_limit_maximum = 20[store][store.kv]path = "/var/lib/sonic/store/kv/"retain_word_objects = 1000[store.kv.pool]inactive_after = 1800[store.kv.database]flush_after = 900compress = true
parallelism = 2
max_files = 100
max_compactions = 1
max_flushes = 1
write_buffer = 16384
write_ahead_log = true[store.fst]path = "/var/lib/sonic/store/fst/"[store.fst.pool]inactive_after = 300[store.fst.graph]consolidate_after = 180在这份配置文件中,你必须注意两个点:
net,sonic的监听端口,这里默认为"0.0.0.0:1491"。
auth_password,sonic的密码,这里默认为"SecretPassword"。然后将文件放在一个合适的位置,记住这个位置,等下启动要用到
/Users/pedro/Desktop/sonic-test/config.cfg
文件配置好后,开始启动服务器
在docker环境下运行
docker run -p 1491:1491 -v ~/Desktop/sonic-test/config.cfg:/etc/sonic.cfg valeriansaliou/sonic:v1.2.0
显示这样则表明启动成功
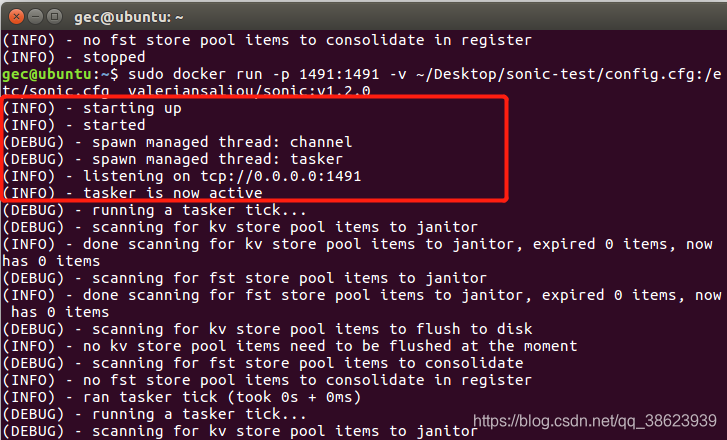
然后用另一个终端来telnet来连接这个端口1491的服务器

注意,这里有个坑,当你telnet上端口之后呢,要马上登录上 sonic服务器,也就是这一行命令
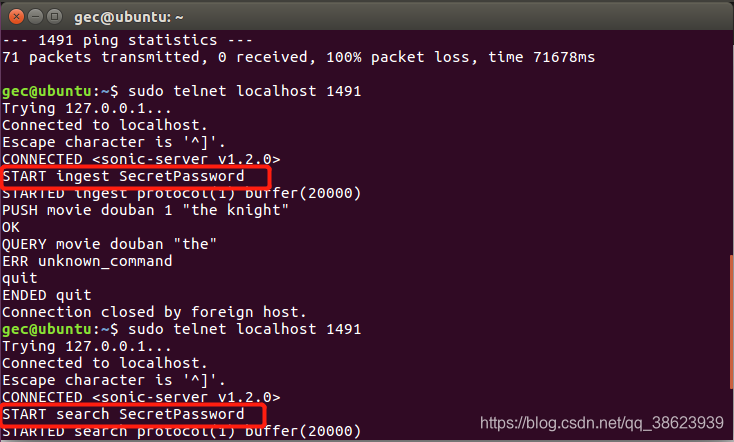
ingest是插入数据,search是搜索数据,视情况而定,我说的这个坑是,当你telnet上sonic服务器端口后,如果大约10秒之内不执行登录sonic服务器的话,那么这个连接就会自动断开(一开始不知道,这个有点坑) 如下图的结果
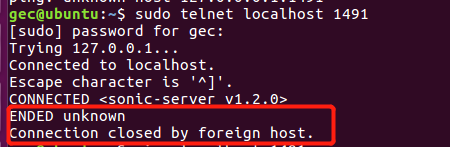
搞了半天,查了一堆资料,还以为是linux系统的 服务器安全策略,自动把我的连接断开了,原来不是的!!!!。
是连接上后大约10秒之内不登陆不执行操作就会自动断开!!!!这个必须注意,大坑
填完这个坑后,先进行插入数据看看
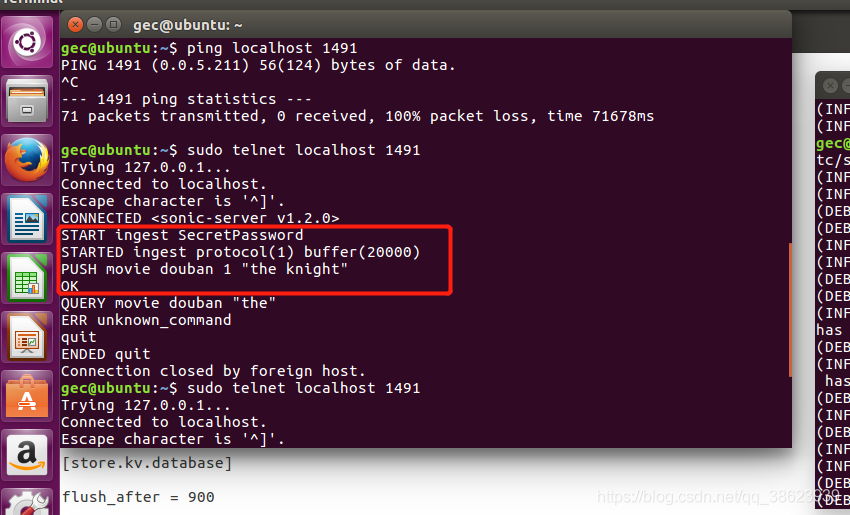
插入数据成功
再进行查询

查询成功, 刚刚添加的the出来了,其实这个sonic有点类似于solr搜索引擎
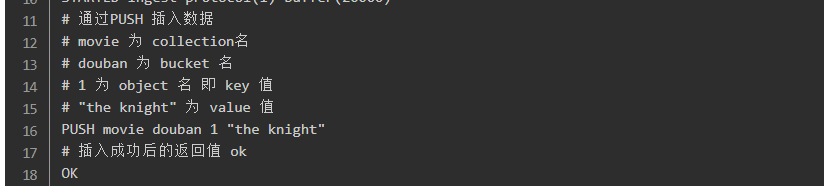
通过库名+桶名 然后通过value拿到key!
这篇关于sonic轻量级的搜索引擎,极致的性能,只用来单纯的查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




