本文主要是介绍数据结构-快速排序“人红是非多”?看我见招拆招,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.快速排序
Hoare版本:
挖坑法:
前后指针版本:
快速排序的时间复杂度
2.快速排序的优化
三数取中法选key
随机数选key
三路划分法
3. 非递归实现快速排序
1.快速排序
快速排序一共有三种版本:Hoare版本、挖坑法、前后指针版本。
Hoare版本:
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
也就是说如果我们要排一个升序,我们可以在待排数据中选择一个值key,把大于该值的数据放在该值的右边,小于该值的数据放在该值的左边,然后在左边的数据中同样选择一个值,重复以上步骤,同时,在右边的数据中选择一个值,重复以上步骤,直到key的左边和右边都是有序的,此时所有数据都有序了。
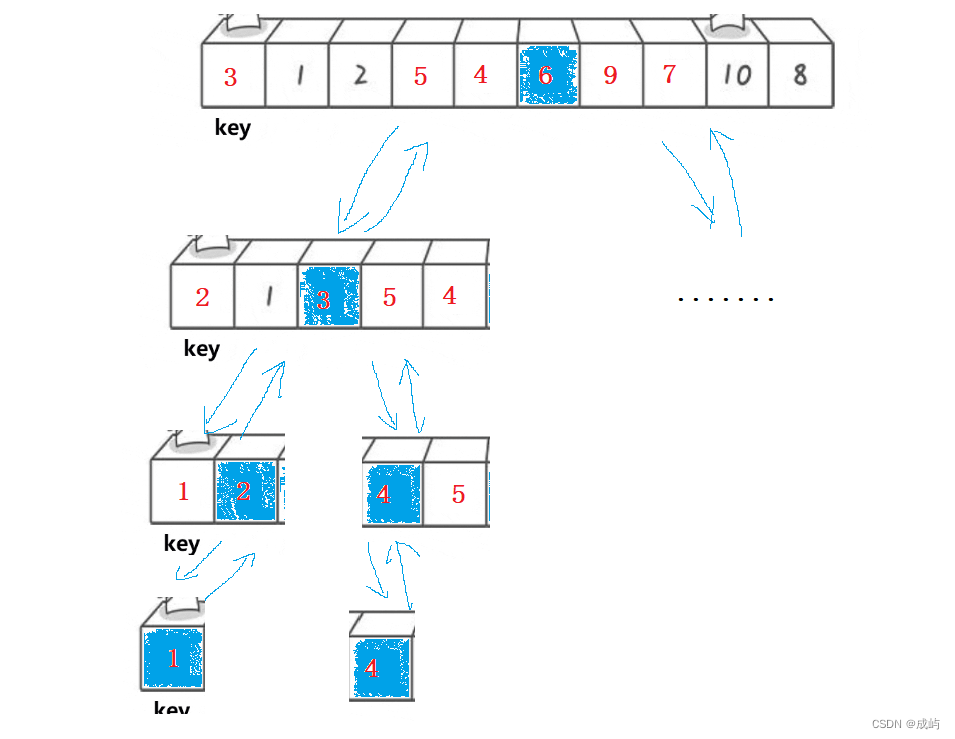
过程如图所示,是一个递归的过程:
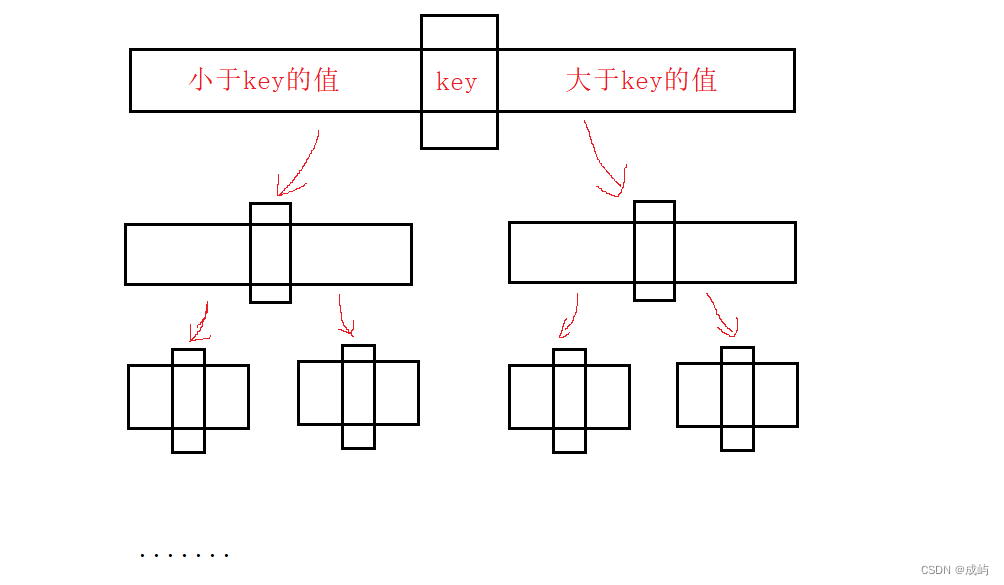
下面我们先来实现一趟的排序:
可以选左边第一个数据为key,然后从右边先开始遍历,当右边找到小于key的值时,停下来,当左边遍历找到大于key的值时,也停下来,然后交换左右两边的数据,最后当左右相遇的时候,把key交换到相遇位置,这就保证了小于key的数据落入key左边,大于key的数据落在key右边。
上代码:
int PartSort(int* a, int left, int right) {int key = a[left];int keyi = left;while (left < right){while (left < right && a[right] >= key){right--;}while (left < right && a[left] <= key){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);return left; }我们单趟排完之后应该如下图所示:
下面来解释一下代码中的循环判断条件:
最外层循环:left<right,左右相遇时就停止。
内层循环:left < right && a[right] >= key,这段代码解决了两个可能存在的问题:
1. 死循环问题
当待排数据如下面所示就可能造成死循环:
所以a[right] >= key时继续遍历。
2. 越界问题
如果a[right] >= key时继续遍历,下面极端情况可能导致越界:
所以我们在内层循环中还要判断一下 left<right。

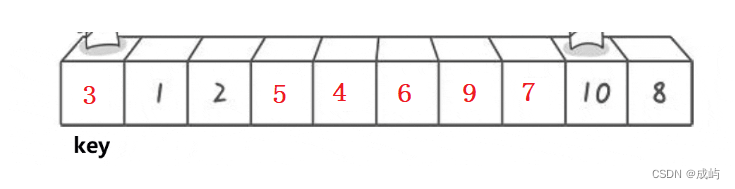
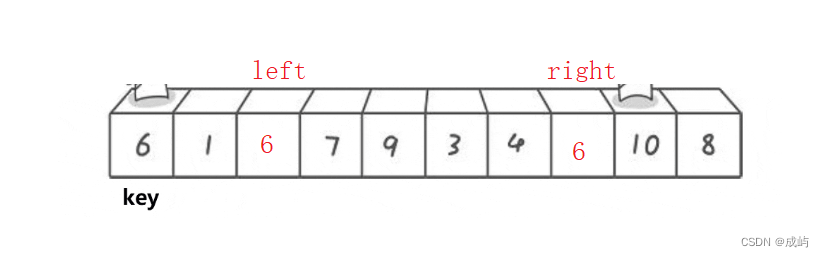
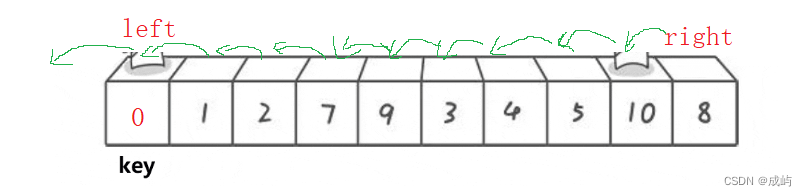
这就是单趟排序的代码了,我们要实现对所有数据的升序,递归调用就行了,当完成一趟排序时,返回相遇位置,然后对相遇位置的左边和右边数据继续重复进行以上操作。这有些类似于二叉树的递归问题。
代码如下:
//交换函数
Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
//快速排序
int PartSort(int* a, int left, int right)
{int key = a[left];int keyi = left;while (left < right){while (left < right && a[right] >= key){right--;}while (left < right && a[left] <= key){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);return left;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int keyi = PartSort(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1,end);
}Print(int* a, int n)
{for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n");
}
int main()
{int a[] = { 9,7,5,2,4,7,1,6,0,8 };QuickSort(a, 0, sizeof(a) / sizeof(int) - 1);Print(a, sizeof(a) / sizeof(int));return 0;
}整个排序过程如下图:
注意下面这段代码的作用是:当区间只有一个值或者出现区间不存在的情况的时候就返回。
if (begin >= end)
{
return;
}
不知道大家有没有注意到一个情况,我们在选择key为左边的数据时,先让右边开始遍历,这是为什么呢?
首先,我们选左边的数据为key,那最终相遇位置的数就一定要比key的值小,这样交换后才能保证key的左边的值都比它小,右边的值都比它大,那我们如何保证相遇位置的值一定就比key小呢?
先给结论:
1. 左边做key,右边先走;保证了相遇位置的值比key小。
2. 右边做key,左边先走;保证了相遇位置的值比key大。
下面我们来论证一下:

结论2的论证同上。
这就是Hoare版本,但是通过上文的学习,这种版本存在的坑太多,下面我们来学一种方法避坑。
挖坑法:
挖坑法的单趟排序过程如图所示:
先选左边的一个数据,把它作为坑,并保存它的值,然后继续右边遍历找到比key小的值就停下,挖走这个值填坑,挖走后形成新的坑,左边遍历找比key大的值就停下,挖走这个值填坑......最后左右相遇,把保存的key值填坑。
代码实现如下:
//挖坑法 int PartSort2(int* a, int left, int right) {int key = a[left];int hole = left;while (left < right){while (left < right && a[right] >= key){right--;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;return hole; }void QuickSort(int* a, int begin, int end) {if (begin >= end){return;}int keyi = PartSort2(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end); } Print(int* a, int n) {for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n"); } int main() {int a[] = { 9,7,5,2,4,7,1,6,0,8 };QuickSort(a, 0, sizeof(a) / sizeof(int) - 1);Print(a, sizeof(a) / sizeof(int));return 0; }

前后指针版本:
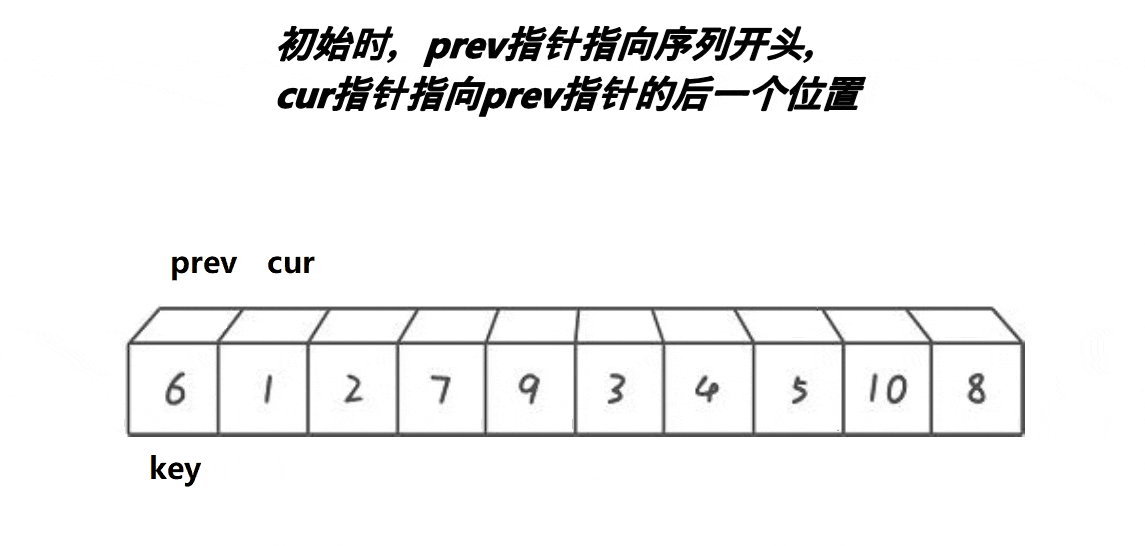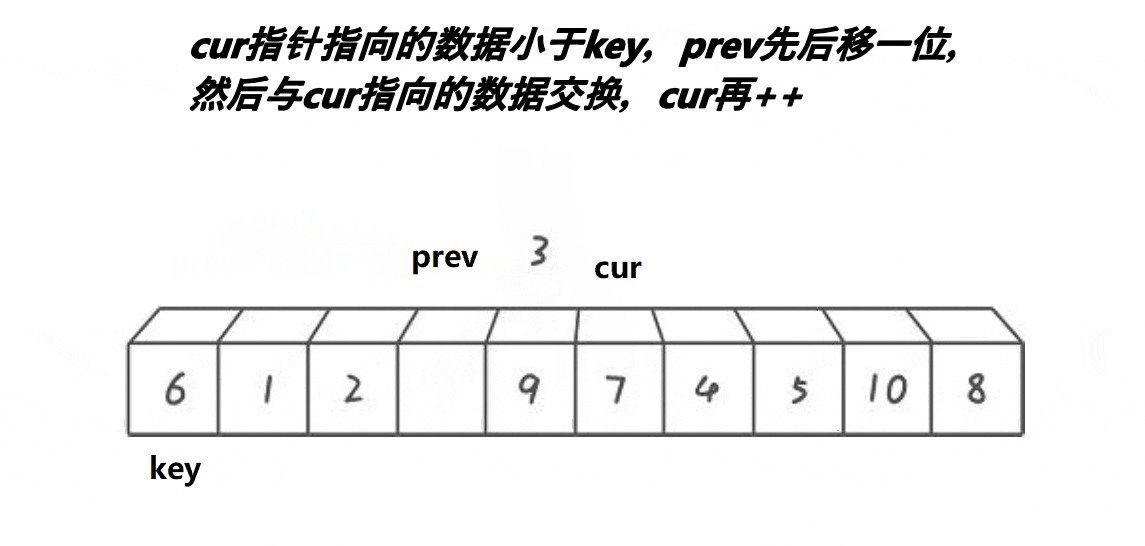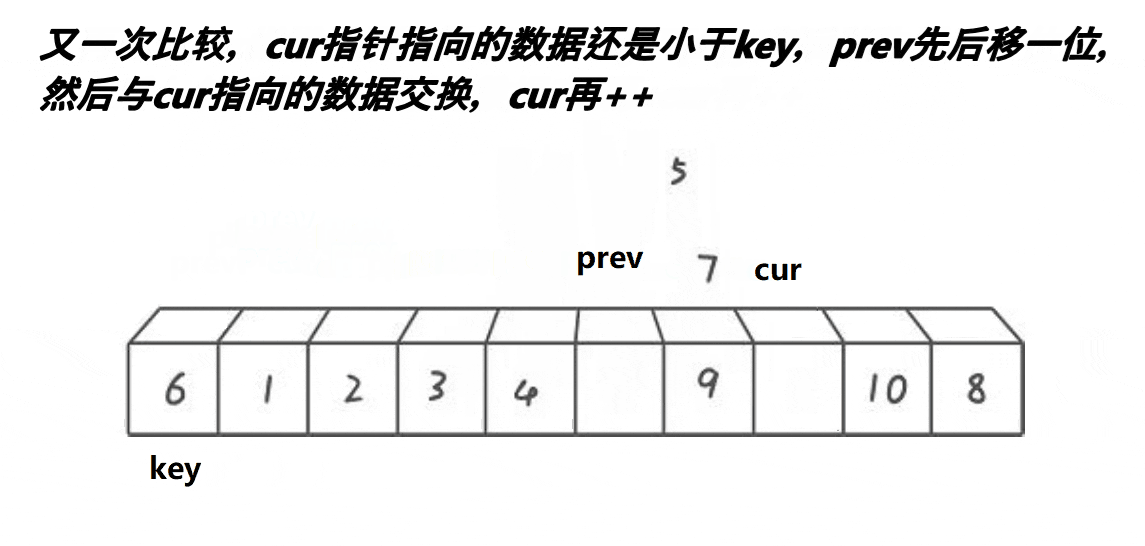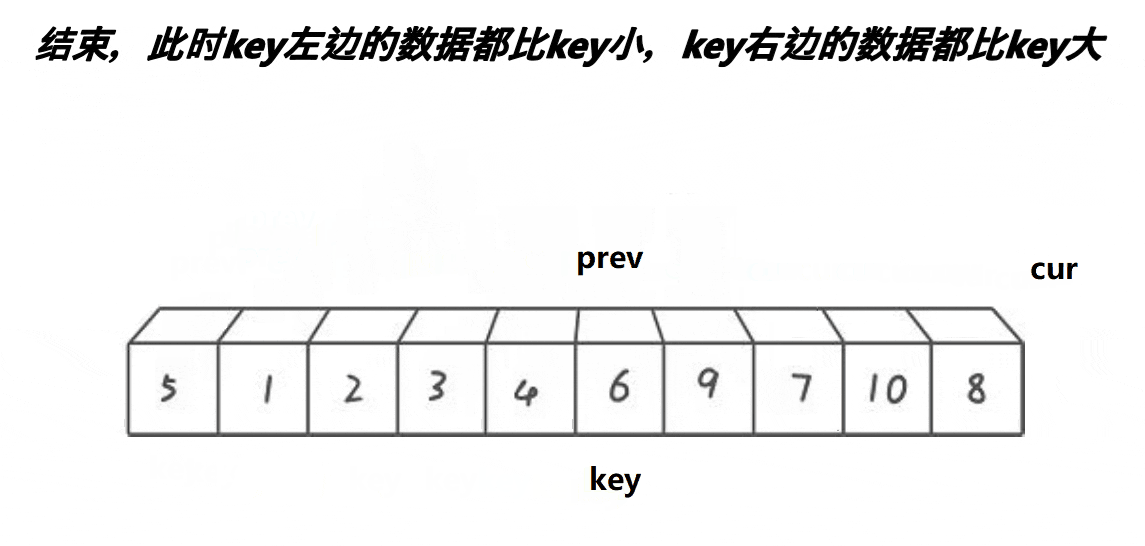
前后指针版本单趟排序过程如下图所示:
我们可以看到,cur在找小,如果a[cur]<key,prev++,然后交换a[prev]和a[cur],如果a[cur]>key,prev不动,整个过程中cur一直不停的往后走,直到cur越界就结束了,此时再交换key和a[prev]。
代码如下:
//前后指针版本 int PartSort3(int* a, int left, int right) {int prev = left;int cur = left + 1;int keyi = left;while (cur <= right){if (a[cur] <= a[keyi]){prev++;Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi; } void QuickSort(int* a, int begin, int end) {if (begin >= end){return;}int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end); } Print(int* a, int n) {for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n"); } int main() {int a[] = {6,1,2,7,9,3,4,5,10,8};QuickSort(a, 0, sizeof(a) / sizeof(int) - 1);Print(a, sizeof(a) / sizeof(int));return 0; }
快速排序的时间复杂度
时间复杂度(最好):O(N*logN)。
时间复杂度(最坏):O(N^2)。
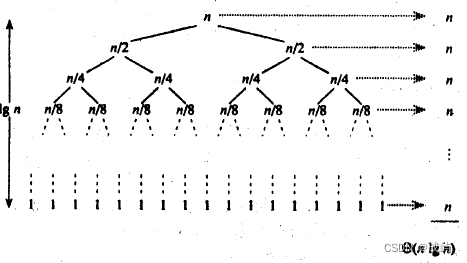
什么时候最好呢?
当每次选的key恰好是中位数时,每次都把数据分成两份,每次减少一半的运算量,相当于二分法:
什么时候最坏呢?
当待排数据本来就是有序的时候,每次选key,选的都是最小的值,此时就相当于等差数列:

那我们选key有两种方案:
1. 随机数取key。
2. 三数取中法选key。
这样可以保证不会是最坏的情况。
2.快速排序的优化
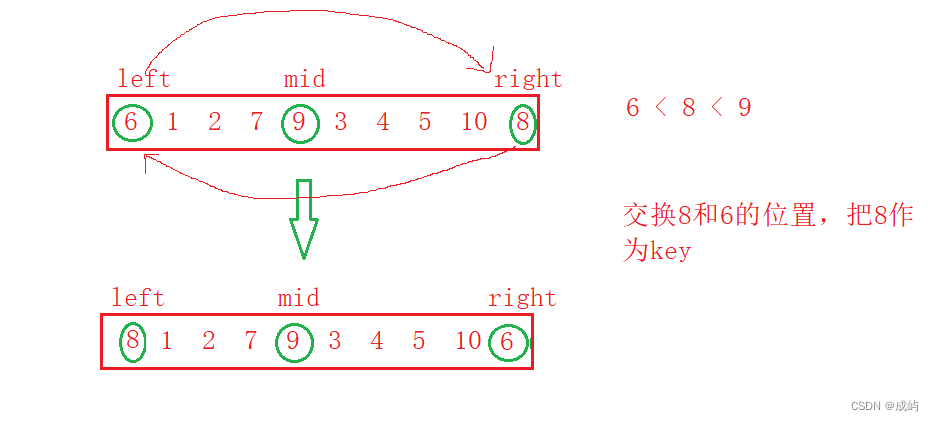
三数取中法选key
三数取中法就是,把左边、右边和中间的三个数相比较,取出其中的中位数,把它作为key,这样就可以提高快速排序的效率。
代码如下:
//三数取中法选key
int GetMidIndex(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[mid] < a[left]){if (a[mid] > a[right]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}else{if (a[mid] < a[right]){return mid;}else if (a[right] > a[left]){return right;}else{return left;}}
}
//快速排序
//Hoare版本
int PartSort(int* a, int left, int right)
{int midi = GetMidIndex(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;while (left < right){while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);return left;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int keyi = PartSort(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}
以上就是三数取中法对快速排序的优化了,下面我们来看一道题,看看我们的快速排序能不能通过?
题目链接:力扣(LeetCode)
结果呢?

超出时间限制了,这其实是力扣针对快速排序三数取中专门设计的一个测试用例,他故意把左边、右边和中间的值都设的很小,这样即使你三数取中,选出的key依旧很小,接近我们上文说的最坏情况,所以会超出时间限制,那我们不玩三数取中能不能过呢?
结果很明显,还是过不了,这次他直接给了个有序的测试用例,这就直接是我们上文中所说的最坏情况了,那怎么办呢?别急,我们还有一招:
随机数选key
随机数取key的意思是,我们保证左右的数据位置不变,中间数据的位置取一个随机数,这样我们三数取中得到的key也是随机的数据,这样力扣就针对不到我们了。
代码如下:
void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; }//三数取中法选key int GetMidIndex(int* a, int left, int right) {//随机数取keyint mid=left+(rand()%(right-left));if (a[mid] < a[left]){if (a[mid] > a[right]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}else{if (a[mid] < a[right]){return mid;}else if (a[right] > a[left]){return right;}else{return left;}} } //前后指针版本 int PartSort3(int* a, int left, int right) {int midi = GetMidIndex(a, left, right);Swap(&a[left], &a[midi]);int prev = left;int cur = left + 1;int keyi = left;while (cur <= right){if (a[cur] <= a[keyi]){prev++;Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi; } void QuickSort(int* a, int begin, int end) {if (begin >= end){return;}int keyi = PartSort3(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end); }int* sortArray(int* nums, int numsSize, int* returnSize) {srand(time(0));QuickSort(nums,0,numsSize-1);*returnSize=numsSize;return nums; }int mid=left+(rand()%(right-left));
表示中间位置取随机位置,为了防止随机数越界,我们用它取余(right-left)。
但是这就结束了吗?还是太天真了,力扣预判了你的预判,不信再运行一下:

这次它给的数据全部相同,那不管我们怎么取key值都是取的最小的,这就又相当于最坏的情况,可见这道题为了针对快速排序是费尽了心思,那我们就没办法了吗?
当然不是,我们还有终极一招,
三路划分法
何谓三路划分呢?我们之前的快速排序是把大于等于key的放在右边,小于等于key的放在左边,相当于待排数据分为两份,而三路划分的意思是把小于key的放在左边,大于key的放在右边,等于key的放在中间,如图所示:
这种方法就是把等于key的收拢在中间位置,当我们递归子区间的时候,只递归小于和大于的区间,这样当待排数据中有重复数据时,可以大大提高效率,尤其是上述测试用例,收拢之后,左右子区间直接就没有值了,都不用再递归。
下图就是三路划分的思想:
我们可以演示一下三路划分的过程:
可以看到,三路划分的本质就是:
1. 和key相等的值都被收拢到中间
2. 小的被甩到左边,大的被甩到右边。
代码如下:
//三数取中法选key int GetMidIndex(int* a, int left, int right) {//随机数取keyint mid=left+(rand()%(right-left));if (a[mid] < a[left]){if (a[mid] > a[right]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}else{if (a[mid] < a[right]){return mid;}else if (a[right] > a[left]){return right;}else{return left;}} }void QuickSort(int* a, int begin, int end) {if (begin >= end){return;}//三数取中int midi = GetMidIndex(a, begin, end);Swap(&a[begin], &a[midi]);int left=begin;int right=end;int cur=left+1;int key=a[left];//三路划分while (cur <= right){if (a[cur] < key){Swap(&a[left], &a[cur]);left++;cur++;}else if (a[cur] > key){Swap(&a[right], &a[cur]);right--;}else{cur++;}}//递归QuickSort(a, begin, left - 1);QuickSort(a, right + 1, end); }int* sortArray(int* nums, int numsSize, int* returnSize) {srand(time(0));QuickSort(nums,0,numsSize-1);*returnSize=numsSize;return nums; }



到这,这道题就用了三种优化方式了,而且三种方式缺一不可,那能不能解决问题呢?
当然可以啦,如果没有上述优化方式,用快排做这道题会很坑,不是快排不快,而是“人红是非多”啊,快排在这道题上被针对的体无完肤,反而堆排、希尔排序等还能通过。
3. 非递归实现快速排序
我们前文讲的递归方式,实际上递归过程处理的是左右子区间,现在我们不能用递归,那要如何处理左右子区间呢?
其实可以用栈实现,每次从栈中拿出一段区间,单趟分割处理,然后让左右子区间入栈。
代码如下(栈部分的代码可以拷贝前面章节的,这里只给核心代码):
//前后指针版本
int PartSort3(int* a, int left, int right)
{int prev = left;int cur = left + 1;int keyi = left;while (cur <= right){if (a[cur] <= a[keyi]){prev++;Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}
//非递归方式实现快排
void QuickSortNonR(int* a, int begin, int end)
{ST st;STInit(&st);STPush(&st, end);STPush(&st, begin);while (!STEmpty(&st)){int left = STTop(&st);STPop(&st);int right = STTop(&st);STPop(&st);int keyi = PartSort3(a, left, right);if (keyi + 1 < right){STPush(&st, right);STPush(&st, keyi + 1);}if (left < keyi-1){STPush(&st, keyi-1);STPush(&st, left);}}STDestroy(&st);
}好了,以上就是快速排序,下节继续学习归并排序,
未完待续。。。
这篇关于数据结构-快速排序“人红是非多”?看我见招拆招的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






