本文主要是介绍海洋卫星DCS载荷原始数据文件的分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
依照本数据为例
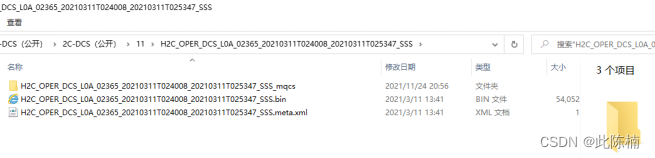
1.命名解读:
H2C:
HY-2C卫星于2020年9月21日成功发射升空,是国家民用空间基础设施海洋动力卫星系列的第二颗业务卫星,主要对海面高度、有效波高、海面风场实现高精度、高分辨率的实时观测,并具备船舶识别以及接收、存贮和转发我国近海及其他海域的浮标测量数据能力。
【HY-2C卫星信息 http://www.nsoas.org.cn/news/content/2021-05/28/44_8460.html】
OPER:
业务化卫星 【HY-2B卫星高度计二级产品数据格式说明.pdf】
DCS:
传感器为dcs,新型的载荷数据收集系统
有效载荷就是直接执行特定卫星任务的仪器、设备或分系统
【提升海洋动力环境卫星观测效能—基于DCS获取海流信息https://mp.weixin.qq.com/s?src=11×tamp=1637770054&ver=3456&signature=08lwgtFmwX00USdnNfeNiF3lYXynfJY2q6jZ6MWtZ2OPkqDBH4H13*TGdyEtBRQi5ux7bzBEWzthAOuSvRlYYT1v*Zw3nfmtwEbAgeob7oC3M1S5SByp3X3saKIFuL55&new=1
卫星DCS载荷测试浮标顺利投入工作
卫星DCS载荷测试浮标顺利投入工作-国家海洋技术中心
L0A:
产品级别。按照NASA的划分如下:http://www.zj-view.com/newsitem/277966126
0级:经数据重构,未进行任何处理的原始数据;所有的通信信息(比如:同步帧、通信头和重复数据)被移除。
1A级:经数据重构,具有时间参考、辅助信息(包括辐射、几何校正系数等)以及地理坐标参数等(如:平台星历等,并没有应用于0级产品)的未进行任何处理的原始数据。
1B级:在1A级产品的基础上处理至传感器单元(并不是所有数据都有L1B级数据)。
2级:与1级数据具有相同分辨率和位置的地球物理参量数据产品。
3级:投影至统一时空格网尺度,通常具有一定完整性和一致性的数据产品。
4级:模型输出结果或从低级数据分析得到的结果。
02365
具体不详,或许是CYCLE,或者PASS
Xxxxxxxxxxxxx-xxxxxxxxx
采集时间
参考中国海洋数据服务系统
DCS载荷数据网站上不公开
已经申请该网站账号
Ander
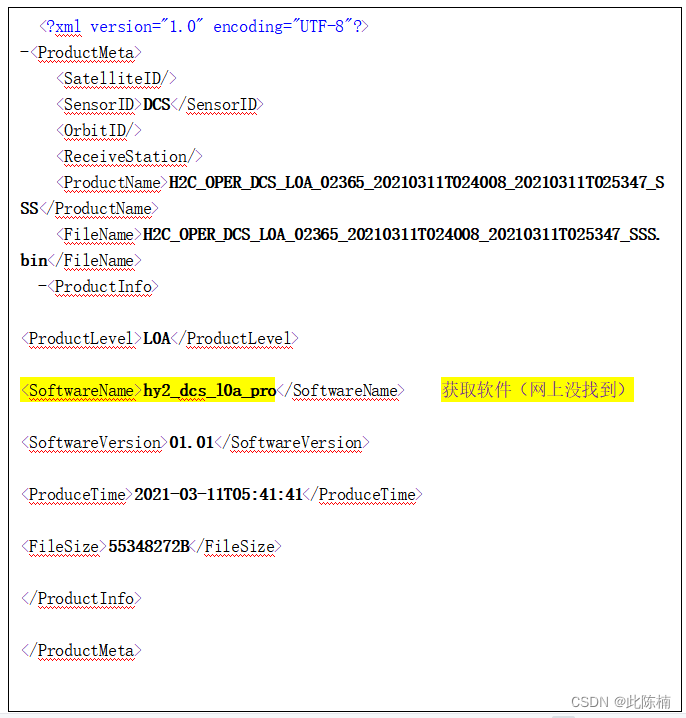
2..meta.xml 配置文件
打开方式
记事本or浏览器
3.mqcs文件夹
mqcs:基本质量控制标准。也就是质量检测文档夹。

.doc文档
在线质量检验内容及结果进行记录以及详细描述
l文件检验:文件格式、文件大小、参数完备性。
l连续性检查:时间连续性、空间连续性。
l参数阈值检查:对参数的阈值范围进行判断。
l数据样本统计:对正常数据、异常数据、缺失数据的样本进行统计。
.h5文件
<质量标志 URL>。H5是一个网页,就像一个很大的容器,里面可以放文本、图片、音视频等基本的流媒体格式的文件。 用下面这个方式可以读取,但无果。
https://blog.csdn.net/weixin_46324973/article/details/119009762
.meta.xml
质量检测配置文件,如下

log.log
操作日志文档

4其他文件
获取、读取、解析数据文件的日志(未查实)

综上所述:
结合海洋卫星数据服务中心下载页面以及给我们的数据文件,判定Bin为源文件,即数据文件。
 数据格式有以上几种,不是每个文件都有。
数据格式有以上几种,不是每个文件都有。
下一步 :Bin文件尝试解读
这篇关于海洋卫星DCS载荷原始数据文件的分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






